kettle大数据量读写mysql性能优化
修改kettleDB连接设置
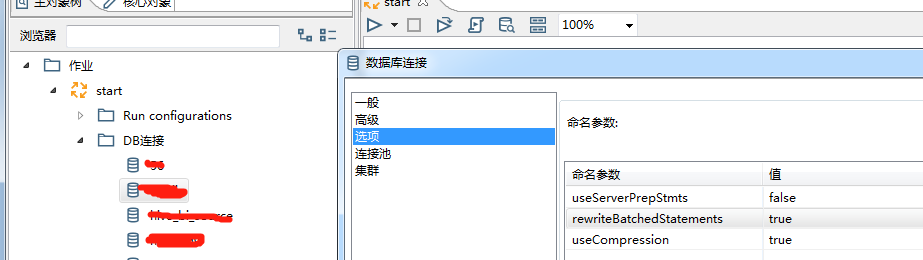
1. 增加批量写的速度:
useServerPrepStmts=false
rewriteBatchedStatements=true
useCompression=true
2. 增加读的速度:
useServerPrepStmts=true
cachePrepStmts=true
参数说明:
1)useCompression=true,压缩数据传输,优化客户端和MySQL服务器之间的通信性能。
2)rewriteBatchedStatements=true ,开启批量写功能
将会使大批量单条插入语句:
INSERT INTO t (c1,c2) VALUES ('One',1);
INSERT INTO t (c1,c2) VALUES ('Two',2);
INSERT INTO t (c1,c2) VALUES ('Three',3);
改写成真正的批量插入语句:
INSERT INTO t (c1,c2) VALUES ('One',1),('Two',2),('Three',3);
3)useServerPrepStmts=false 关闭服务器端编译,sql语句在客户端编译好再发送给服务器端,发送语句如上。
如果为true,sql会采用占位符方式发送到服务器端,在服务器端再组装sql语句。
占位符方式:INSERT INTO t (c1,c2) VALUES (?,?),(?,?),(?,?);
此方式就会产生一个问题,当列数*提交记录数>65535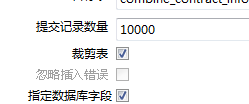
时就会报错:Prepared statement contains too many placeholders,
这是由于我把“提交记录数量”设为10000,而要插入记录的表字段有30个,所以要进行批量插入时需要30*10000=300000 > 65535 ,故而报错。
解决方案:
方案1:把DB连接中的 rewriteBatchedStatements 给设置为false(或者去掉),不过这个操作会影响数据的插入速度。
方案2:更改表输出的设计。确保30个输出字段的和提交记录数量的乘积不超过65535。比如把提交记录数量由10000更改为450(30*2000=60000< 65535)
当然我们的目的是为了提高数据库写速度,所以当rewriteBatchedStatements =true时useServerPrepStmts=false必须配合使用。
mysql参数调优可以参考如下文档
https://dev.mysql.com/doc/connectors/en/connector-j-reference-configuration-properties.html
数据丢失问题:
性能提升后,遇到另外个问题,86万数据丢失了130多条,kettle无报错,各种mysql参数设置之后都无效果,耗时近一天,最终查到是重复数据导致。
估计是因为重复数据在mysql写不进去导致该批次数据写失败,但是kettle无报错这个就比较坑。
解决办法就是:1)取消数据表主键或者唯一索引 ,当然这是治标不治本的做法。2)根本的做法就是排查重复数据,从源头杜绝重复数据
参考文档:
https://blog.csdn.net/smooth00/article/details/69389424?utm_source=itdadao&utm_medium=referral
http://www.jackieathome.net/archives/169.html
kettle大数据量读写mysql性能优化的更多相关文章
- 大数据量时Mysql的优化
(转自网络) 如今随着互联网的发展,数据的量级也是撑指数的增长,从GB到TB到PB.对数据的各种操作也是愈加的困难,传统的关系性数据库已经无法满足快速查询与插入数据的需求.这个时候NoSQL的出现暂时 ...
- spring Batch实现数据库大数据量读写
spring Batch实现数据库大数据量读写 博客分类: spring springBatchquartz定时调度批处理 1. data-source-context.xml <?xml v ...
- 大数据量数据库设计与优化方案(SQL优化)
转自:http://blog.sina.com.cn/s/blog_6c0541d50102wxen.html 一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的 ...
- java excel大数据量导入导出与优化
package com.hundsun.ta.utils; import java.io.File; import java.io.FileOutputStream; import java.io.I ...
- 总结MySQL大数据量下如何进行优化
写在建库前: 在确定数据库业务后.建立数据库表格时,就应对一些常见问题有所考虑,以避免在数据增长一段时间后再做应对,可能造成时间及维护成本增加: 数据的月增量,年增量 数据的快速增长点 是否需要触发器 ...
- 大数据量时 Mysql LIMIT如何正确对其进行优化(转载)
以下的文章主要是对Mysql LIMIT简单介绍,我们大家都知道LIMIT子句一般是用来限制SELECT语句返回的实际行数.LIMIT取1个或是2个数字参数,如果给定的是2个参数,第一个指定要返回的第 ...
- 大数据量下MySQL插入方法的性能比较
不管是日常业务数据处理中,还是数据库的导入导出,都可能遇到需要处理大量数据的插入.插入的方式和数据库引擎都会对插入速度造成影响,这篇文章旨在从理论和实践上对各种方法进行分析和比较,方便以后应用中插入方 ...
- 一文总结高并发大数据量下MySQL开发规范【军规】
在互联网公司中,MySQL是使用最多的数据库,那么在并发量大.数据量大的互联网业务中,如果高效的使用MySQL才能保证服务的稳定呢?根据本人多年运维管理经验的总结,梳理了一些核心的开发规范,希望能给大 ...
- JAVA JDBC大数据量导入Mysql
转自https://blog.csdn.net/q6834850/article/details/73726707?tdsourcetag=s_pctim_aiomsg 采用JDBC批处理(开启事务. ...
随机推荐
- Spring Boot + Jpa + Thymeleaf 增删改查示例
快速上手 配置文件 pom 包配置 pom 包里面添加 Jpa 和 Thymeleaf 的相关包引用 <dependency> <groupId>org.springframe ...
- 201621123075作业07-Java GUI编程
1. 本周学习总结 1.1 思维导图:Java图形界面总结 1.2 可选:使用常规方法总结其他上课内容. 2.书面作业 1. GUI中的事件处理 1.1 写出事件处理模型中最重要的几个关键词. 事件源 ...
- CCF关于NOI省选申诉的说明
NOI省选由各省根据NOI条例及CCF省选规定组织省内选拔,各省组织单位对其省选过程和结果负责 对省选的申诉首先提交至NOI省组织单位,NOI省组织单位必须先给出处理意见.对于NOI省组织单位不能决定 ...
- UVa Live 4794 - Sharing Chocolate 枚举子集substa = (s - 1) & substa,记忆化搜索 难度: 2
题目 https://icpcarchive.ecs.baylor.edu/index.php?option=com_onlinejudge&Itemid=8&page=show_pr ...
- 安装一个Linux
Linux--虚拟机的的安装: 首先需要一个可执行(VMware-workstation-full-14.1.2-8497320.exe)的文件和一个Linux(CentOS-7-x86_64-DVD ...
- 开始Flask项目
新建Flask项目. 设置调试模式. 理解Flask项目主程序. 使用装饰器,设置路径与函数之间的关系. 使用Flask中render_template,用不同的路径,返回首页.登录员.注册页. 用视 ...
- 路由器桥接尝试WDS
第一步:设置主路由器192.168.1.1. 第二步:设置副路由器. 进入副路由器的设置界面 点击「网络参数」->「LAN口设置」 把副路由器的LAN地址设置为192.168.1.2防止与主路由 ...
- oracle开发错误
先展示一个错误写法 public static String printGg_bysly0List() {// 外网 TransManager tm = new TransManager(); try ...
- Error: No EPCS layout data - looking for section [EPCS-C84018]
/********************************************************************** * Error: No EPCS layout data ...
- CentOS6.5上安装MySQL
1.查看操作系统的相关信息 2.查看系统上所有MySQL的rpm包并删除 [root@master ~]# rpm -qa | grep -i mysql [root@masterc ~]# yum ...