kettle大数据量读写mysql性能优化
修改kettleDB连接设置
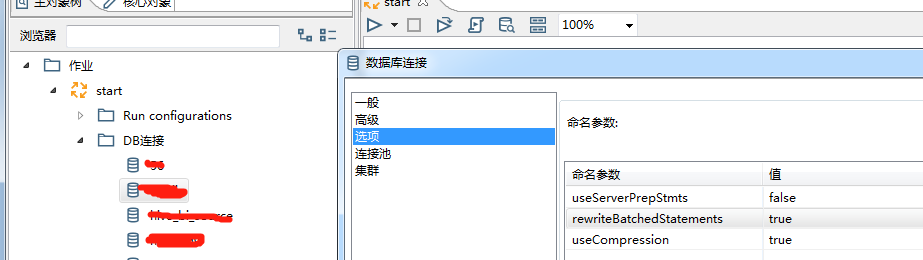
1. 增加批量写的速度:
useServerPrepStmts=false
rewriteBatchedStatements=true
useCompression=true
2. 增加读的速度:
useServerPrepStmts=true
cachePrepStmts=true
参数说明:
1)useCompression=true,压缩数据传输,优化客户端和MySQL服务器之间的通信性能。
2)rewriteBatchedStatements=true ,开启批量写功能
将会使大批量单条插入语句:
INSERT INTO t (c1,c2) VALUES ('One',1);
INSERT INTO t (c1,c2) VALUES ('Two',2);
INSERT INTO t (c1,c2) VALUES ('Three',3);
改写成真正的批量插入语句:
INSERT INTO t (c1,c2) VALUES ('One',1),('Two',2),('Three',3);
3)useServerPrepStmts=false 关闭服务器端编译,sql语句在客户端编译好再发送给服务器端,发送语句如上。
如果为true,sql会采用占位符方式发送到服务器端,在服务器端再组装sql语句。
占位符方式:INSERT INTO t (c1,c2) VALUES (?,?),(?,?),(?,?);
此方式就会产生一个问题,当列数*提交记录数>65535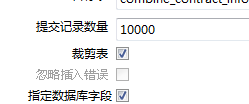
时就会报错:Prepared statement contains too many placeholders,
这是由于我把“提交记录数量”设为10000,而要插入记录的表字段有30个,所以要进行批量插入时需要30*10000=300000 > 65535 ,故而报错。
解决方案:
方案1:把DB连接中的 rewriteBatchedStatements 给设置为false(或者去掉),不过这个操作会影响数据的插入速度。
方案2:更改表输出的设计。确保30个输出字段的和提交记录数量的乘积不超过65535。比如把提交记录数量由10000更改为450(30*2000=60000< 65535)
当然我们的目的是为了提高数据库写速度,所以当rewriteBatchedStatements =true时useServerPrepStmts=false必须配合使用。
mysql参数调优可以参考如下文档
https://dev.mysql.com/doc/connectors/en/connector-j-reference-configuration-properties.html
数据丢失问题:
性能提升后,遇到另外个问题,86万数据丢失了130多条,kettle无报错,各种mysql参数设置之后都无效果,耗时近一天,最终查到是重复数据导致。
估计是因为重复数据在mysql写不进去导致该批次数据写失败,但是kettle无报错这个就比较坑。
解决办法就是:1)取消数据表主键或者唯一索引 ,当然这是治标不治本的做法。2)根本的做法就是排查重复数据,从源头杜绝重复数据
参考文档:
https://blog.csdn.net/smooth00/article/details/69389424?utm_source=itdadao&utm_medium=referral
http://www.jackieathome.net/archives/169.html
kettle大数据量读写mysql性能优化的更多相关文章
- 大数据量时Mysql的优化
(转自网络) 如今随着互联网的发展,数据的量级也是撑指数的增长,从GB到TB到PB.对数据的各种操作也是愈加的困难,传统的关系性数据库已经无法满足快速查询与插入数据的需求.这个时候NoSQL的出现暂时 ...
- spring Batch实现数据库大数据量读写
spring Batch实现数据库大数据量读写 博客分类: spring springBatchquartz定时调度批处理 1. data-source-context.xml <?xml v ...
- 大数据量数据库设计与优化方案(SQL优化)
转自:http://blog.sina.com.cn/s/blog_6c0541d50102wxen.html 一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的 ...
- java excel大数据量导入导出与优化
package com.hundsun.ta.utils; import java.io.File; import java.io.FileOutputStream; import java.io.I ...
- 总结MySQL大数据量下如何进行优化
写在建库前: 在确定数据库业务后.建立数据库表格时,就应对一些常见问题有所考虑,以避免在数据增长一段时间后再做应对,可能造成时间及维护成本增加: 数据的月增量,年增量 数据的快速增长点 是否需要触发器 ...
- 大数据量时 Mysql LIMIT如何正确对其进行优化(转载)
以下的文章主要是对Mysql LIMIT简单介绍,我们大家都知道LIMIT子句一般是用来限制SELECT语句返回的实际行数.LIMIT取1个或是2个数字参数,如果给定的是2个参数,第一个指定要返回的第 ...
- 大数据量下MySQL插入方法的性能比较
不管是日常业务数据处理中,还是数据库的导入导出,都可能遇到需要处理大量数据的插入.插入的方式和数据库引擎都会对插入速度造成影响,这篇文章旨在从理论和实践上对各种方法进行分析和比较,方便以后应用中插入方 ...
- 一文总结高并发大数据量下MySQL开发规范【军规】
在互联网公司中,MySQL是使用最多的数据库,那么在并发量大.数据量大的互联网业务中,如果高效的使用MySQL才能保证服务的稳定呢?根据本人多年运维管理经验的总结,梳理了一些核心的开发规范,希望能给大 ...
- JAVA JDBC大数据量导入Mysql
转自https://blog.csdn.net/q6834850/article/details/73726707?tdsourcetag=s_pctim_aiomsg 采用JDBC批处理(开启事务. ...
随机推荐
- 不安全的HTTP方法(渗透实验)
1.使用 curl -v -X OPTIONS url(含目录) 获取允许访问的http method 例如:curl -v -X OPTIONS http://192.168.1.123:12123 ...
- ThinkPHP5的数据操作和Thinkphp3.2.3对比小结
前言: 由于Thinkphp5和Thinkphp3.2.3的版本差距过大, 在记忆方面容易混淆. 故特意记录一下在数据操作上的对比的不同. Tp3.2.3 增:add(),addAll() 查:fin ...
- 在数据库中sql查询很快,但在程序中查询较慢的解决方法
在写java的时候,有一个方法查询速度比其他方法慢很多,但在数据库查询很快,原来是因为程序中使用参数化查询时参数类型错误的原因 select * from TransactionNo, fmis_Ac ...
- 使用Python爬取代理ip
本文主要代码用于有代理网站http://www.kuaidaili.com/free/intr中的代理ip爬取,爬虫使用过程中需要输入含有代理ip的网页链接. 测试ip是否可以用 import tel ...
- Linux shell基础知识(上)
Linux shell基础知识(上) 目录 一.shell介绍 二.命令历史 三.命令补全和别名 四.通配符 五.输入输出重定向 六.管道符和作业控制 七.shell变量 八.环境变量配置文件 九.b ...
- NOIP2012提高组 Day 2 Problem 2 借教室
原题 题目描述 在大学期间,经常需要租借教室.大到院系举办活动,小到学习小组自习讨论,都需要向学校申请借教室.教室的大小功能不同,借教室人的身份不同,借教室的手续也不一样. 面对海量租借教室的信息,我 ...
- SamplesHashtable
using System; using System.Collections; public class SamplesHashtable { public static void Main() { ...
- APP打包提交审核的步骤
- 导入maven项目导入依赖不会报错,但使用的jar会标红
方法1: 1.通过编译找到报错的jar; 2.在 repository找到此jar,一般未下载完大小为1k我的是这样(); 3.删除未下载完全的jar,在项目上执行maven reimport会重新下 ...
- python3 基础整理
基础语法 1.python中区分大小写 2.查看关键字用 import keyword print (keyword.kwlist) 3.注释 # 单行注释,多行注释的快捷键是ctr+/,取消注释的 ...