HDU - 3407 - String-Matching Automata
先上题目:
String-Matching Automata
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)
Total Submission(s): 215 Accepted Submission(s): 140
Σ is the input alphabet (a finite nonempty set of symbols).
S is a finite nonempty set of states.
s0 is an element in S designated as the initial state.
δ is a function δ: S × Σ → S known as the transition function.
F is a (possibly empty) subset of S whose elements are designated as the final states.
An FSA with the above description operates as follows:
At the beginning, the automaton starts in the initial state s0.
The automaton continuously reads symbols from its input, one symbol at a time, and transits between states according to the transition function δ. To be specific, let s be the current state and w the symbol just read, the automaton moves to the state given by δ(s, w).
When the automaton reaches the end of the input, if the current state belongs to F, the string consisting sequentially of the symbols read by the automaton is declared accepted, otherwise it is declared rejected.
Just as the name implies, a string-matching automaton is a FSA that is used for string matching and is very efficient: they examine each character exactly once, taking constant time per text character. The matching time used (after the automaton is built) is therefore Θ(n). However, the time to build the automaton can be large.
Precisely, there is a string-matching automaton for every pattern P that you search for in a given text string T. For a given pattern of length m, the corresponding automaton has (m + 1) states {q0, q1, …, qm}: q0 is the start state, qm is the only final state, and for each i in {0, 1, …, m}, if the automaton reaches state qi, it means the length of the longest prefix of P that is also a suffix of the input string is i. When we reaches state qm, it means P is a suffix of the currently input string, which suggest we find an occurrence of P.
The following graph shows a string-matching automaton for the pattern “ababaca”, and illustrates how the automaton works given an input string “abababacaba”.
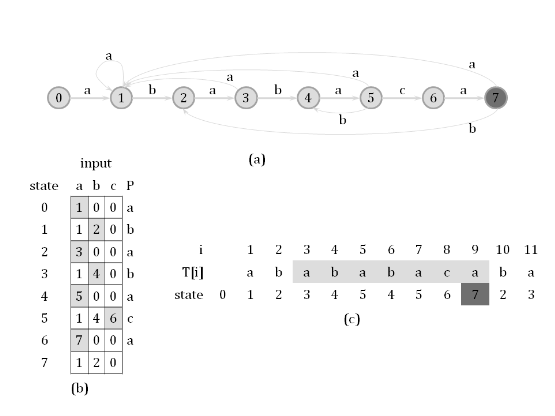
Apparently, the matching process using string-matching automata is quite simple (also efficient). However, building the automaton efficiently seems to be tough, and that’s your task in this problem.
0
#include <cstdio>
#include <cstring>
#include <queue>
#define MAX 10002
using namespace std; struct Trie{
int next[MAX][],fail[MAX],end[MAX],num[MAX][];
int root,L; int newnode(){
for(int i=;i<;i++){ next[L][i]=-; num[L][i]=;}
end[L++]=;
return L-;
}
void init(){
L=; root=newnode();
} void insert(char buf[]){
int len=strlen(buf);
int now = root;
for(int i=;i<len;i++){
if(next[now][buf[i]-'a']==-){
next[now][buf[i]-'a']=newnode(); }
now=next[now][buf[i]-'a'];
}
end[now]++;
} void build(){
queue<int> Q;
fail[root]=root;
for(int i=;i<;i++){
if(next[root][i]==-) next[root][i]=root;
else{
fail[next[root][i]]=root;
Q.push(next[root][i]);
}
}
while(!Q.empty()){
int now=Q.front();
Q.pop();
for(int i=;i<;i++){
if(next[now][i]==-) next[now][i]=next[fail[now]][i];
else{
fail[next[now][i]]=next[fail[now]][i];
Q.push(next[now][i]);
}
}
}
} void print(char buf[]){
int len=strlen(buf);
int now=root;
for(int i=;i<=len;i++){
printf("%d",i);
for(int j=;j<;j++) printf(" %d",next[now][j]);
printf("\n");
now=next[now][buf[i]-'a'];
}
}
}; Trie ac;
char s[MAX]; int main()
{
//freopen("data.txt","r",stdin);
while(scanf("%s",s),strcmp(s,"")){
ac.init();
ac.insert(s);
ac.build();
ac.print(s);//printf("\n");
}
return ;
}
/*3407*/
HDU - 3407 - String-Matching Automata的更多相关文章
- Binary String Matching
问题 B: Binary String Matching 时间限制: 3 Sec 内存限制: 128 MB提交: 4 解决: 2[提交][状态][讨论版] 题目描述 Given two strin ...
- NYOJ之Binary String Matching
Binary String Matching 时间限制:3000 ms | 内存限制:65535 KB 难度:3 描述 Given two strings A and B, whose a ...
- ACM Binary String Matching
Binary String Matching 时间限制:3000 ms | 内存限制:65535 KB 难度:3 描述 Given two strings A and B, whose alp ...
- 南阳OJ----Binary String Matching
Binary String Matching 时间限制:3000 ms | 内存限制:65535 KB 难度:3 描述 Given two strings A and B, whose alp ...
- Binary String Matching(kmp+str)
Binary String Matching 时间限制:3000 ms | 内存限制:65535 KB 难度:3 描述 Given two strings A and B, whose alp ...
- Aho - Corasick string matching algorithm
Aho - Corasick string matching algorithm 俗称:多模式匹配算法,它是对 Knuth - Morris - pratt algorithm (单模式匹配算法) 形 ...
- [POJ] String Matching
String Matching Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 4074 Accepted: 2077 D ...
- String Matching Content Length
hihocoder #1059 :String Matching Content Length 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 We define the ...
- HDU 3374 String Problem (KMP+最大最小表示)
HDU 3374 String Problem (KMP+最大最小表示) String Problem Time Limit: 2000/1000 MS (Java/Others) Memory ...
随机推荐
- 小记 react 数据存储位置
react 中状态的六个存储位置 state 我想大家都知道这个地方,而且在使用 setState 时会触发组件的更新 class prop 将值存在 class 的对象中,如: class App ...
- C++面向对象程序设计_Part2
目录 Composition(复合) 内存视角下的composition(复合) composition(复合)关系下的构造与析构 Delegation (委託) -- Composition by ...
- 基于.Net Core的API框架的搭建(3)
5.加入缓存支持 我们希望为项目增加缓存支持,我们选择Redis做为缓存数据库. 首先,我们在Services目录增加一个缓存接口类ICacheService: using System; using ...
- May Challenge 2019 Division 2 水题讲解
Reduce to One 这题其实蛮水的? 题意就是说: 给定一个 1~n 的序列,每次挑两个数 x y 合并,合并值为 \(x+y+xy\) ,然后求不断合并最后剩下的一个的最大值 随便搞搞发现答 ...
- [BZOJ5109/CodePlus2017]大吉大利,晚上吃鸡!
Description 最近<绝地求生:大逃杀>风靡全球,皮皮和毛毛也迷上了这款游戏,他们经常组队玩这款游戏.在游戏中,皮皮和毛毛最喜欢做的事情就是堵桥,每每有一个好时机都能收到不少的快递 ...
- 洛谷 P3389 【模板】高斯消元法
以下这个好像叫高斯约旦消元法,没有回代 https://www.luogu.org/blog/37781/solution-p3389 #include<cstdio> #include& ...
- 贪心 Codeforces Round #263 (Div. 2) C. Appleman and Toastman
题目传送门 /* 贪心:每次把一个丢掉,选择最小的.累加求和,重复n-1次 */ /************************************************ Author :R ...
- FormsAuthentication权限管理
通常我们在做访问权限管理的时候会把用户正确登录后的基本信息保存在Session中然后用户每次请求页面或接口数据的时候代上会话状态即能拿到Session中存储的基本信息Session的原理,也就是在服务 ...
- android视频播放器系列(二)——VideoView
最近在学习视频相关的知识,现在也是在按部就班的一步步的来,如果有同样需求的同学可以跟着大家一起促进学习. 上一节说到了可以使用系统播放器以及浏览器播放本地以及网络视频,但是这在很大程度上并不能满足我们 ...
- 读《实战GUI产品的自动化测试》:第一步——了解自动化测试,简单RFT的录制回放实例
1.了解自动化测试,什么是自动化测试?(可以参数百度百科“自动化测试”) 2.了解自动化测试 * 自动化测试如何改善产品的质量 * 自动化测试无法完全替代手工测试 * 自动化测试无法发现新的问题——适 ...