由mysql分区想到的分表分库的方案
在分区分库分表前一定要了解分区分库分表的动机。
对实时性要求比较高的场景,使用数据库的分区分表分库。
对实时性要求不高的场景,可以考虑使用索引库(es/solr)或者大数据hadoop平台来解决(如数据分析,挖掘,报表等)或者混合使用(如es+hbase/mongodb)。
...分区解决冷热数据分离的问题;
...分库解决互联网的高并发问题;
...分表解决互联网的高容量问题;
...分库分表解决高并发和高容量的问题。
今天细细品味了一下mysql分区的官方资料,有一点点收获,记录下来。
1.mysql的分区
官方文档介绍的比较详细,这里就以实例为主介绍。
1.1 分区类型
1.range分区
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21)
);
2.list分区
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LIST(store_id) (
PARTITION pNorth VALUES IN (3,5,6,9,17),
PARTITION pEast VALUES IN (1,2,10,11,19,20),
PARTITION pWest VALUES IN (4,12,13,14,18),
PARTITION pCentral VALUES IN (7,8,15,16)
);
3.多列分区
多列分区有分为range分区和list分区
多列range分区
mysql> CREATE TABLE rcx (
-> a INT,
-> b INT,
-> c CHAR(3),
-> d INT
-> )
-> PARTITION BY RANGE COLUMNS(a,d,c) (
-> PARTITION p0 VALUES LESS THAN (5,10,'ggg'),
-> PARTITION p1 VALUES LESS THAN (10,20,'mmm'),
-> PARTITION p2 VALUES LESS THAN (15,30,'sss'),
-> PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE,MAXVALUE)
-> );
多列list分区
CREATE TABLE customers_1 (
first_name VARCHAR(25),
last_name VARCHAR(25),
street_1 VARCHAR(30),
street_2 VARCHAR(30),
city VARCHAR(15),
renewal DATE
)
PARTITION BY LIST COLUMNS(city) (
PARTITION pRegion_1 VALUES IN('Oskarshamn', 'Högsby', 'Mönsterås'),
PARTITION pRegion_2 VALUES IN('Vimmerby', 'Hultsfred', 'Västervik'),
PARTITION pRegion_3 VALUES IN('Nässjö', 'Eksjö', 'Vetlanda'),
PARTITION pRegion_4 VALUES IN('Uppvidinge', 'Alvesta', 'Växjo')
4.Linear hash分区
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY LINEAR HASH( YEAR(hired) )
PARTITIONS 4;
5. Key分区
CREATE TABLE tm1 (
s1 CHAR(32) PRIMARY KEY
)
PARTITION BY KEY(s1)
PARTITIONS 10;
6.Sub分区
CREATE TABLE ts (id INT, purchased DATE)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) )
SUBPARTITIONS 2 (
PARTITION p0 VALUES LESS THAN (1990),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE
);
7.对控制的处理
range分区,null 分到最低的分区;
list分区,如果包含null的列,则进去,否则会报错,如下实例
mysql> CREATE TABLE ts1 (
-> c1 INT,
-> c2 VARCHAR(20)
-> )
-> PARTITION BY LIST(c1) (
-> PARTITION p0 VALUES IN (0, 3, 6),
-> PARTITION p1 VALUES IN (1, 4, 7),
-> PARTITION p2 VALUES IN (2, 5, 8)
-> );
Query OK, 0 rows affected (0.01 sec) mysql> INSERT INTO ts1 VALUES (9, 'mothra');
ERROR 1504 (HY000): Table has no partition for value 9 mysql> INSERT INTO ts1 VALUES (NULL, 'mothra');
ERROR 1504 (HY000): Table has no partition for value NULL
hash分区和key分区,null做0处理,示例如下:
mysql> INSERT INTO th VALUES (NULL, 'mothra'), (0, 'gigan');
Query OK, 1 row affected (0.00 sec) mysql> SELECT * FROM th;
+------+---------+
| c1 | c2 |
+------+---------+
| NULL | mothra |
+------+---------+
| 0 | gigan |
+------+---------+
2 rows in set (0.01 sec)
1.2 分区管理
Range和list分区管理
ALTER TABLE ... DROP PARTITION 删除分区
ALTER TABLE ... ADD PARTITION 增加分区
ALTER TABLE ...REORGANIZE PARTITION 移动分区
Hash和key分区管理
不能通过DROP来删除分区,可以ALTER TABLE ... COALESCE PARTITION来合并分区
ALTER TABLE ... ADD PARTITION 增加分区
表间的分区交换和子分区表的交换
ALTER TABLE ... EXCHANGE PARTITION
维护分区
表的维护:CHECK TABLE,OPTIMIZE TABLE,ANALYZE TABLE, REPAIR TABLE
分区的维护:ALTER TABLE ...
Rebuilding partitions
Optimizing partitions
Analyzing partitions
Repairing partitions
Checking partitions
TRUNCATE PARTITION
获取分区信息
SHOW CREATE TABLE
SHOW TABLE STATUS
INFORMATION_SCHEMA.PARTITIONS
EXPLAIN SELECT
1.3 小结
从分区表的设计思想上来看,支持多张分区方式:range,list,多列,linear hash,key,sub分区
另外,还提供对分区的管理。
2.分库或者分表
分区,分表,分库解决的问题不一样,但解决思路或者架构设计有相通的地方,我们可以借鉴分区表的设计思维来构建分表分库的实现。

分区具有的功能:
分区屏蔽的对用户dml和select的细节,分表或者分库db代理应该也可以实现,分表或者分库db代理保存db的元数据和映射情况,对用户来说,应该屏蔽细节,不应该暴露给用户
分区的管理提供了相应的命令,分表或者分库db代理也应该实现该功能
分区不具有的功能:
监控,日志,可视化等方面分区做的不够,分表或者分库db代理可以做的更好。
想到了hadoop的hdfs架构设计
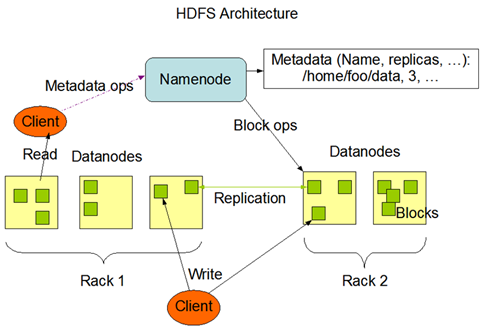
3.mycat的实现
根据上面的思路,是否有响应的开源实现呢?找到一个比较相近的开源实现mycat:
- 一个彻底开源的,面向企业应用开发的大数据库集群
- 支持事务、ACID、可以替代MySQL的加强版数据库
- 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
- 一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
- 一个新颖的数据库中间件产品
总结:
mycat在国内使用的不少,可以试用。如果想定制自己的mycat,可以参考mysql分区的实现和hadoop存储hdfs的架构思想。
参考资料:
【1】https://dev.mysql.com/doc/refman/8.0/en/partitioning-limitations-partitioning-keys-unique-keys.html
由mysql分区想到的分表分库的方案的更多相关文章
- mysql大数据解决方案--分表分库(0)
引言 对于一个大型的互联网应用,海量数据的存储和访问成为了系统设计的瓶颈问题,对于系统的稳定性和扩展性造成了极大的问题.通过数据切分来提高网站性能,横向扩展数据层已经成为架构研发人员首选的方式. •水 ...
- Mysql数据库进阶之(分表分库,主从分离)
前言:数据库的优化是一个程序员的分水岭,作为小白我也得去提前学习这方面的数据的 (一) 三范式和逆范式 听起范式这个迟非常专业我来举个简单的栗子: 第一范式就是: 把能够关联的每条数据都拆分成一个 ...
- 总结下Mysql分表分库的策略及应用
上月前面试某公司,对于mysql分表的思路,当时简要的说了下hash算法分表,以及discuz分表的思路,但是对于新增数据自增id存放的设计思想回答的不是很好(笔试+面试整个过程算是OK过了,因与个人 ...
- 重新学习Mysql数据13:Mysql主从复制,读写分离,分表分库策略与实践
一.MySQL扩展具体的实现方式 随着业务规模的不断扩大,需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量. 关于数据库的扩展主要包括:业务拆分.主从复制.读写分离.数据库分库 ...
- mysql数据库为什么要分表和分区?
一般下载的源码都带了MySQL数据库的,做个真正意义上的网站没数据库肯定不行. 数据库主要存放用户信息(注册用户名密码,分组,等级等),配置信息(管理权限配置,模板配置等),内容链接(html ,图片 ...
- [NewLife.XCode]分表分库(百亿级大数据存储)
NewLife.XCode是一个有15年历史的开源数据中间件,支持netcore/net45/net40,由新生命团队(2002~2019)开发完成并维护至今,以下简称XCode. 整个系列教程会大量 ...
- 学会数据库读写分离、分表分库——用Mycat,这一篇就够了!
系统开发中,数据库是非常重要的一个点.除了程序的本身的优化,如:SQL语句优化.代码优化,数据库的处理本身优化也是非常重要的.主从.热备.分表分库等都是系统发展迟早会遇到的技术问题问题.Mycat是一 ...
- .NETCore 下支持分表分库、读写分离的通用 Repository
首先声明这篇文章不是标题党,我说的这个类库是 FreeSql.Repository,它作为扩展库现实了通用仓储层功能,接口规范参考 abp vnext 定义,实现了基础的仓储层(CURD). 安装 d ...
- 学会数据库读写分离、分表分库——用Mycat
系统开发中,数据库是非常重要的一个点.除了程序的本身的优化,如:SQL语句优化.代码优化,数据库的处理本身优化也是非常重要的.主从.热备.分表分库等都是系统发展迟早会遇到的技术问题问题.Mycat是一 ...
随机推荐
- Mac电脑解压文件unrar用密码问题解决
下载了一个rar文件,有密码的,你懂的. 但是在mac上面,用unrar解压,只能解出空文件:用izip解压,直接停在那里不动. 只好上网搜索.找到了办法. 用brew 安装了命令行版本的 unrar ...
- 【CV知识学习】神经网络梯度与归一化问题总结+highway network、ResNet的思考
这是一篇水货写的笔记,希望路过的大牛可以指出其中的错误,带蒟蒻飞啊~ 一. 梯度消失/梯度爆炸的问题 首先来说说梯度消失问题产生的原因吧,虽然是已经被各大牛说烂的东西.不如先看一个简单的网络结构 ...
- BUPT复试专题—众数(2014)
题目描述 有一个长度为N的非降数列,求数列中出现最多的数,若答案不唯一输出最小的数 输入 第一行T表示测试数据的组数(T<100) 对于每组测试数据: 第一行是一个正整数N表示数列长度 第二行有 ...
- 使用squid架设自己的代理server
主要參考了 http://blog.chinaunix.net/uid-20778906-id-540115.html Ubuntu下Squid代理server的安装与配置 1 安装 $ sudo a ...
- evaluate-reverse-polish-notation——栈
Evaluate the value of an arithmetic expression in Reverse Polish Notation. Valid operators are+,-,*, ...
- DTD笔记
DTD(Document Type Definition)文档类型定义: DTD被用于定义XML文档的结构,作为规范XML文档的一种内容模型,DTD在各领域已形成统一规范的文档. 在XML文档中使用D ...
- openwrt mt7620 内存大小检测
单独编译内核: make V=s target/linux/install 相调函数调用流程: init/main.c : start_kernel() -> setup_arch(&c ...
- ubuntu编译airplay
1.alsa/asoundlib.h: No such file or directory 缺少一个库: apt-get install libasound2-dev 2.fatal error: ...
- stm32GPIO8种模式
stm32GPIO工作模式及用途 1.浮空输入GPIO_IN_FLOATING ——浮空输入,可以做KEY识别,RX1 2.带上拉输入GPIO_IPU——IO内部上拉电阻输入 ...
- 检測磁盘驱动的健康程度SMART
在server中,全部组件中一般最easy坏掉的就是磁盘.所以一般採取RAID来保证系统的稳定性,通过冗余磁盘的方式防止磁盘故障. 现代硬件驱动器一般支持SMART(自我监測分析和报告技术),它可以监 ...