TensorFlow 用神经网络解决非线性问题
本节涉及点:
- 激活函数 sigmoid
- 产生随机训练数据
- 使用随机训练数据训练
- 加入偏移量b加快训练过程
- 进阶:批量生产随机训练数据
在前面的三好学生问题中,学校改变了评三好的标准 —— 总分>= 95,即可当三好。计算总分公式不变 —— 总分 = 德*0.6+智*0.3+体*0.1
但学校没有公布这些规则,家长们希望通过神经网络计算出学校的上述规则
这个问题显然不是线性问题,也就是无法用一个类似 y = w*x + b 的公式来从输入数据获得结果
虽然总分和各项成绩是线性关系,但总分与是否评比上三好并不是线性关系,而是一个阶跃函数
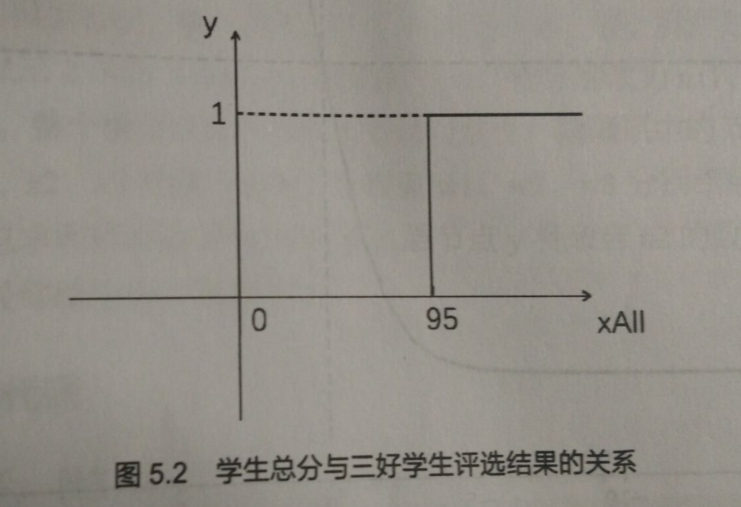
# 如果在一连串的线性关系中有一个非线性关系出现,整个问题都将成为非线性的问题
一、激活函数 sigmoid
把评选结果 是不是三好学生 定义为 1 / 0
那么由总分 ——> 评选结果的过程 就是 0~100的数字得出1 或 0 的计算过程 ——> sidmoid 函数
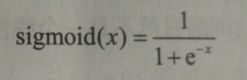 e 为自然底数
e 为自然底数
(1)sigmoid 函数
可以把任意数字变成 0 - 1 范围内的数字
在图中可以观察到,-5~5 的范围是个快速的从0 变1的过程,非常像这个问题出现的阶跃函数 ————> 常常用来进行 二分类
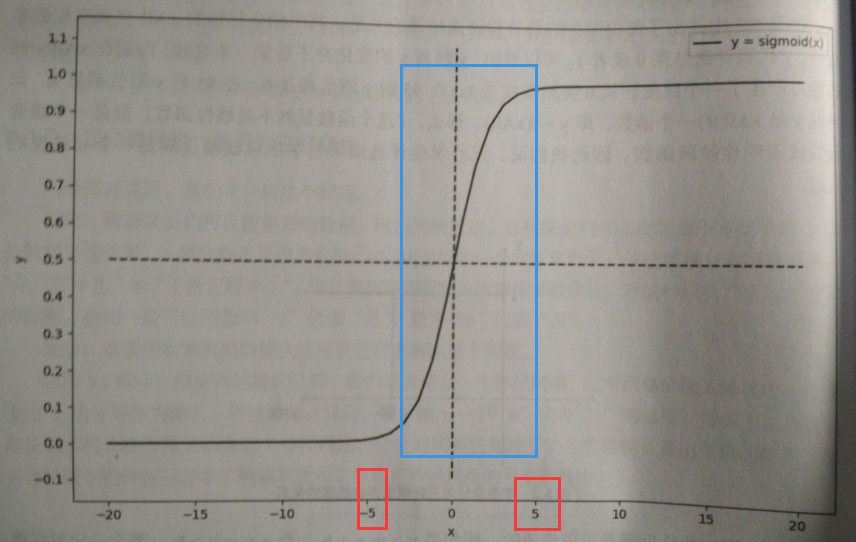
# 在神经网络中,像sigmoid 这种把线性化的关系转化为非线性化关系的函数叫做 激活函数
(2)使用sigmoid 函数后的神经网络模型
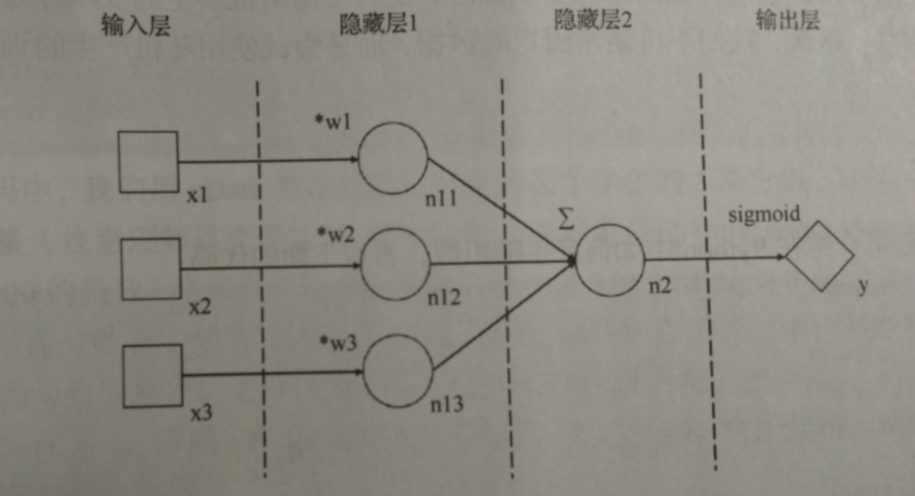
隐藏层中的节点 n11,n12,n13 分别接收来自输入层节点 x1 x2 x3的输入数据,与权重 w1 w2 w3 分别相乘后都送到 隐藏层 2 的节点 n2 ,n2将这些数据汇总求和后再 送到输出层,输出层节点将来自n2 的数据使用激活函数 sigmoid 处理后面作为神经网络最后输出的计算结果
用代码实现这个模型:
import tensorflow as tf x = tf.placeholder(dtype=tf.float32)
yTrain = tf.placeholder(dtype=tf.float32) w = tf.Variable(tf.zeros([3]),dtype=tf.float32) n1 = w* x
n2 = tf.reduce_sum(n1) y = tf.nn.sigmoid(n2)
上面的代码中 使用了以向量来组织数据的简单的实现方法 x —— [x1,x2,x3]
输出层节点则是 调用了tf.nn.sigmoid() 函数
二、产生随机训练数据
随机数:
import random
random.seed()
r = random.random() * 10
print(r)
x = int (r)
print(x)
6.999030147748621
6
random包 提供的函数 random 产生 [0,1) 范围内的随机小数
int (r) ———— 对小数r 向下取
计算机产生的随机数都是伪随机数,随机性并不好,最好运行函数 random.seed() 来产生新的 随机数种子
产生随机训练数据:
import random
random.seed() xData = [int (random.random() * 101),int (random.random() * 101),int(random.random() * 101)]
xAll = xData[0]* 0.6 + xData[1] * 0.3 + xData[2]*0.1 if xAll >= 95:
yTrainData = 1
else:
yTrainData = 0
print(xData)
print(yTrainData)
我们用xData 来存放随机产生的某个学生的三个分数 ———— 这是一个 一维数组来存放的三维向量
xAll 用来存放 总分
接着 用条件判断语句生成目标值,满足 总分 >= 95 时为1, 否则为0
结果:
[52, 70, 7]
0
虽然该数据理论上是正确的,但一名学生一科7分,有点不正常,所以优化下
import random
random.seed() xData = [int (random.random() * 41+60),int (random.random() *41+60),int(random.random() *41+60)]
xAll = xData[0]* 0.6 + xData[1] * 0.3 + xData[2]*0.1 if xAll >= 95:
yTrainData = 1
else:
yTrainData = 0
print(xData)
print(yTrainData)
产生随机数在 [60,100],是数据更合理
但符合三好学生的条件的数据太少,不利于神经网络的训练,所以更大概率的产生一些 符合三好学生调节的数据:
xData = [int (random.random() * 8+93),int (random.random() *8+93),int(random.random() *8+93)]
使数据介于[93,100]
但为了避免出现太多符合三好学生条件的数据,会交替使用这两种方法产生更平衡的训练数据
三、使用随机数据训练
本段代码一共循环执行 5 轮,每一轮两次训练,第一次是 三好学生概率大的一些随机分数,第二次使用一般的随机分数
import tensorflow as tf
import random
random.seed()
x = tf.placeholder(dtype=tf.float32)
yTrain = tf.placeholder(dtype=tf.float32)
w = tf.Variable(tf.zeros([3]), dtype=tf.float32)
wn = tf.nn.softmax(w)
n1 = wn * x
n2 = tf.reduce_sum(n1)
y = tf.nn.sigmoid(n2)
loss = tf.abs(yTrain - y)
optimizer = tf.train.RMSPropOptimizer(0.1)
train = optimizer.minimize(loss)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(5):
xData = [int(random.random() * 8 + 93), int(random.random() * 8 + 93), int(random.random() * 8 + 93)]
xAll = xData[0] * 0.6 + xData[1] * 0.3 + xData[2] * 0.1
if xAll >= 95:
yTrainData = 1
else:
yTrainData = 0
result = sess.run([train, x, yTrain, w, n2, y, loss], feed_dict={x: xData, yTrain: yTrainData})
print(result)
xData = [int(random.random() * 41 + 60), int(random.random() * 41 + 60), int(random.random() * 41 + 60)]
xAll = xData[0] * 0.6 + xData[1] * 0.3 + xData[2] * 0.1
if xAll >= 95:
yTrainData = 1
else:
yTrainData = 0
result = sess.run([train, x, yTrain, w, n2, y, loss], feed_dict={x: xData, yTrain: yTrainData})
print(result)
[None, array([96., 98., 95.], dtype=float32), array(1., dtype=float32), array([0., 0., 0.], dtype=float32), 96.33334, 1.0, 0.0]
[None, array([85., 91., 61.], dtype=float32), array(0., dtype=float32), array([0., 0., 0.], dtype=float32), 79.0, 1.0, 1.0]
[None, array([95., 96., 94.], dtype=float32), array(1., dtype=float32), array([0., 0., 0.], dtype=float32), 95.0, 1.0, 0.0]
[None, array([94., 87., 68.], dtype=float32), array(0., dtype=float32), array([0., 0., 0.], dtype=float32), 83.0, 1.0, 1.0]
[None, array([99., 93., 95.], dtype=float32), array(1., dtype=float32), array([0., 0., 0.], dtype=float32), 95.66667, 1.0, 0.0]
[None, array([98., 75., 63.], dtype=float32), array(0., dtype=float32), array([0., 0., 0.], dtype=float32), 78.66667, 1.0, 1.0]
[None, array([99., 95., 95.], dtype=float32), array(1., dtype=float32), array([0., 0., 0.], dtype=float32), 96.33334, 1.0, 0.0]
[None, array([83., 89., 74.], dtype=float32), array(0., dtype=float32), array([0., 0., 0.], dtype=float32), 82.0, 1.0, 1.0]
[None, array([ 98., 100., 95.], dtype=float32), array(1., dtype=float32), array([0., 0., 0.], dtype=float32), 97.66667, 1.0, 0.0]
[None, array([62., 79., 61.], dtype=float32), array(0., dtype=float32), array([0., 0., 0.], dtype=float32), 67.333336, 1.0, 1.0]

加入偏移量b加快训练过程
import tensorflow as tf
import random
random.seed()
x = tf.placeholder(dtype=tf.float32)
yTrain = tf.placeholder(dtype=tf.float32)
w = tf.Variable(tf.zeros([3]), dtype=tf.float32)
b = tf.Variable(80, dtype=tf.float32)
wn = tf.nn.softmax(w)
n1 = wn * x
n2 = tf.reduce_sum(n1) - b
y = tf.nn.sigmoid(n2)
loss = tf.abs(yTrain - y)
optimizer = tf.train.RMSPropOptimizer(0.1)
train = optimizer.minimize(loss)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(500):
xData = [int(random.random() * 8 + 93), int(random.random() * 8 + 93), int(random.random() * 8 + 93)]
xAll = xData[0] * 0.6 + xData[1] * 0.3 + xData[2] * 0.1
if xAll >= 95:
yTrainData = 1
else:
yTrainData = 0
result = sess.run([train, x, yTrain, wn, b, n2, y, loss], feed_dict={x: xData, yTrain: yTrainData})
print(result)
xData = [int(random.random() * 41 + 60), int(random.random() * 41 + 60), int(random.random() * 41 + 60)]
xAll = xData[0] * 0.6 + xData[1] * 0.3 + xData[2] * 0.1
if xAll >= 95:
yTrainData = 1
else:
yTrainData = 0
result = sess.run([train, x, yTrain, wn, b, n2, y, loss], feed_dict={x: xData, yTrain: yTrainData})
print(result)
程序中,我们让 n2 在计算总分的 基础上 - b,目的是为了让 n2向[-5,5]这个区间范围靠拢。
根据前面代码的输出,我们随便预估了 b 的取值,80
输出:
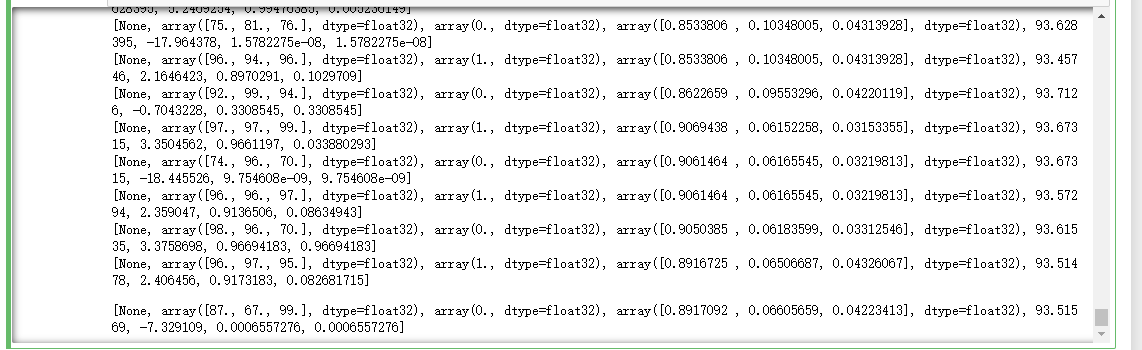
参数w 和 b 的值明显变化,n2的值也在 0 附近跳动,误差也出现了小数上的调整,这说明神经网络的训练已经进入良性的循环了
尝试增加训练次数,并把输出结果信息中的w 改为 wn,最后几次的输出结果如下:
import tensorflow as tf
import random
random.seed()
x = tf.placeholder(dtype=tf.float32)
yTrain = tf.placeholder(dtype=tf.float32)
w = tf.Variable(tf.zeros([3]), dtype=tf.float32)
b = tf.Variable(80, dtype=tf.float32)
wn = tf.nn.softmax(w)
n1 = wn * x
n2 = tf.reduce_sum(n1) - b
y = tf.nn.sigmoid(n2)
loss = tf.abs(yTrain - y)
optimizer = tf.train.RMSPropOptimizer(0.1)
train = optimizer.minimize(loss)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(500):
xData = [int(random.random() * 8 + 93), int(random.random() * 8 + 93), int(random.random() * 8 + 93)]
xAll = xData[0] * 0.6 + xData[1] * 0.3 + xData[2] * 0.1
if xAll >= 95:
yTrainData = 1
else:
yTrainData = 0
result = sess.run([train, x, yTrain, wn, b, n2, y, loss], feed_dict={x: xData, yTrain: yTrainData})
print(result)
xData = [int(random.random() * 41 + 60), int(random.random() * 41 + 60), int(random.random() * 41 + 60)]
xAll = xData[0] * 0.6 + xData[1] * 0.3 + xData[2] * 0.1
if xAll >= 95:
yTrainData = 1
else:
yTrainData = 0
result = sess.run([train, x, yTrain, wn, b, n2, y, loss], feed_dict={x: xData, yTrain: yTrainData})
print(result)

可以看到, 三项分数的权重变量wn 非常接近于期待值 [0.6,0.3,0.1] ,可变参数b 非常接近这个问题中判断是否是 三好学生的门槛 95 ——— 总分门槛95分,会有一个评选结果从 0-1的跳变,,而 sigmoid 函数的输入值在 [-5,5] 之间时,会有一个从 0 到 1 的巨变,那么总分减去偏移量 b 就可以得到引起模型输出结果巨变的数值,显然可以看出,偏移量b 为 95
即b 的值为95左右时,优化器可以“感受到” 调整可变参数 w 后对输出结果的影响,因而能够有效的调整可变参数,使误差越来越小
b 为啥不等于95? ———— sigmoid函数比较不是从0直接跳变成1,是连续的,这个渐变的过程中,输出的数值会导致优化器判断出现误判,这是正常的。可以通过增加大量在这个边界附近的训练数据,可以有效的减少误差
四、进阶:批量生产随机训练数据
在训练前 一次性 批量生成 一批训练数据以备训练
import tensorflow as tf
import random
import numpy as np
random.seed()
rowCount = 5
#np.full 生成一个多维数组,并用预定的值来填充
xData = np.full(shape=(rowCount, 3), fill_value=0, dtype=np.float32)#生成了一个形态为 (rowCount,3)的多维数组,并全部用0填充
#rowCount 是准备生成的训练数据的条数
yTrainData = np.full(shape=rowCount, fill_value=0, dtype=np.float32)
goodCount = 0#符合三好学生条件的数据的个数
# 生成随机训练数据的循环
for i in range(rowCount):
xData[i] = [int(random.random() * 11 + 90), int(random.random() * 11 + 90), int(random.random() * 11 + 90)]
xAll = xData[i][0] * 0.6 + xData[i][1] * 0.3 + xData[i][2] * 0.1
if xAll >= 95:
yTrainData[i] = 1
goodCount = goodCount + 1
else:
yTrainData[i] = 0
print("xData=%s" % xData)
print("yTrainData=%s" % yTrainData)
print("goodCount=%d" % goodCount)
x = tf.placeholder(dtype=tf.float32)
yTrain = tf.placeholder(dtype=tf.float32)
w = tf.Variable(tf.zeros([3]), dtype=tf.float32)
b = tf.Variable(80, dtype=tf.float32)
wn = tf.nn.softmax(w)
n1 = wn * x
n2 = tf.reduce_sum(n1) - b
y = tf.nn.sigmoid(n2)
loss = tf.abs(yTrain - y)
optimizer = tf.train.RMSPropOptimizer(0.1)
train = optimizer.minimize(loss)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(2):
for j in range(rowCount):
result = sess.run([train, x, yTrain, wn, b, n2, y, loss], feed_dict={x: xData[j], yTrain: yTrainData[j]})
print(result) #最后,在训练的时候,每一轮训练会训练rowCount 次,也就是5次,每次训练会把 xData yTrainData 中对应小标序号的数据“喂”给神经网络
结果如下:
xData=[[ 96. 90. 97.]
[ 95. 100. 98.]
[ 97. 91. 94.]
[ 96. 92. 95.]
[100. 97. 100.]]
yTrainData=[0. 1. 0. 0. 1.]
goodCount=2
[None, array([96., 90., 97.], dtype=float32), array(0., dtype=float32), array([0.33333334, 0.33333334, 0.33333334], dtype=float32), 80.0, 14.333336, 0.9999994, 0.9999994]
[None, array([ 95., 100., 98.], dtype=float32), array(1., dtype=float32), array([0.33333334, 0.33333337, 0.33333334], dtype=float32), 80.0, 17.666672, 1.0, 0.0]
[None, array([97., 91., 94.], dtype=float32), array(0., dtype=float32), array([0.33333334, 0.33333337, 0.33333334], dtype=float32), 80.0, 14.000008, 0.99999917, 0.99999917]
[None, array([96., 92., 95.], dtype=float32), array(0., dtype=float32), array([0.33333328, 0.33333337, 0.33333328], dtype=float32), 80.0, 14.333328, 0.9999994, 0.9999994]
[None, array([100., 97., 100.], dtype=float32), array(1., dtype=float32), array([0.33333325, 0.3333334 , 0.3333333 ], dtype=float32), 80.0, 19.0, 1.0, 0.0]
[None, array([96., 90., 97.], dtype=float32), array(0., dtype=float32), array([0.33333325, 0.3333334 , 0.3333333 ], dtype=float32), 80.0, 14.333328, 0.9999994, 0.9999994]
[None, array([ 95., 100., 98.], dtype=float32), array(1., dtype=float32), array([0.33333325, 0.33333346, 0.33333328], dtype=float32), 80.0, 17.666672, 1.0, 0.0]
[None, array([97., 91., 94.], dtype=float32), array(0., dtype=float32), array([0.33333325, 0.33333346, 0.33333328], dtype=float32), 80.0, 14.0, 0.99999917, 0.99999917]
[None, array([96., 92., 95.], dtype=float32), array(0., dtype=float32), array([0.33333322, 0.3333335 , 0.33333328], dtype=float32), 80.0, 14.333336, 0.9999994, 0.9999994]
[None, array([100., 97., 100.], dtype=float32), array(1., dtype=float32), array([0.3333332 , 0.33333352, 0.33333328], dtype=float32), 80.0, 19.0, 1.0, 0.0]

随时生成数据的方法能够最大限度地提高神经网络训练的覆盖范围(因为每一次 训练都是使用新产生的随机数据),进而最大限度地提高它的准确性,缺点是训练速度相对较慢;
一次性生成一批随机数据的方法则反之, 训练速度会很快,因为每轮训练都是同一批数据, 神经网络中的参数可以很快地被调节到合适的取值,但是这样训练出来的神经网络会比较“依赖”于这批数据,换一批数据时 会发现准确度明显下降
TensorFlow 用神经网络解决非线性问题的更多相关文章
- 用Tensorflow让神经网络自动创造音乐
#————————————————————————本文禁止转载,禁止用于各类讲座及ppt中,违者必究————————————————————————# 前几天看到一个有意思的分享,大意是讲如何用Ten ...
- 【零基础】使用Tensorflow实现神经网络
一.序言 前面已经逐步从单神经元慢慢“爬”到了神经网络并把常见的优化都逐个解析了,再往前走就是一些实际应用问题,所以在开始实际应用之前还得把“框架”翻出来,因为后面要做的工作需要我们将精力集中在业务而 ...
- (转)一文学会用 Tensorflow 搭建神经网络
一文学会用 Tensorflow 搭建神经网络 本文转自:http://www.jianshu.com/p/e112012a4b2d 字数2259 阅读3168 评论8 喜欢11 cs224d-Day ...
- 用Tensorflow搭建神经网络的一般步骤
用Tensorflow搭建神经网络的一般步骤如下: ① 导入模块 ② 创建模型变量和占位符 ③ 建立模型 ④ 定义loss函数 ⑤ 定义优化器(optimizer), 使 loss 达到最小 ⑥ 引入 ...
- Tensorflow卷积神经网络[转]
Tensorflow卷积神经网络 卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络, 在计算机视觉等领域被广泛应用. 本文将简单介绍其原理并分析Te ...
- 深度学习原理与框架-Tensorflow卷积神经网络-cifar10图片分类(代码) 1.tf.nn.lrn(局部响应归一化操作) 2.random.sample(在列表中随机选值) 3.tf.one_hot(对标签进行one_hot编码)
1.tf.nn.lrn(pool_h1, 4, bias=1.0, alpha=0.001/9.0, beta=0.75) # 局部响应归一化,使用相同位置的前后的filter进行响应归一化操作 参数 ...
- 深度学习原理与框架-Tensorflow卷积神经网络-神经网络mnist分类
使用tensorflow构造神经网络用来进行mnist数据集的分类 相比与上一节讲到的逻辑回归,神经网络比逻辑回归多了隐藏层,同时在每一个线性变化后添加了relu作为激活函数, 神经网络使用的损失值为 ...
- 一文学会用 Tensorflow 搭建神经网络
http://www.jianshu.com/p/e112012a4b2d 本文是学习这个视频课程系列的笔记,课程链接是 youtube 上的,讲的很好,浅显易懂,入门首选, 而且在github有代码 ...
- tensorflow之神经网络实现流程总结
tensorflow之神经网络实现流程总结 1.数据预处理preprocess 2.前向传播的神经网络搭建(包括activation_function和层数) 3.指数下降的learning_rate ...
随机推荐
- ARDUINO UNO烧录BOOTLOADER
批量烧录为了速度加快,使用USBASP工具,配合PROGISP软件进行烧录. 因为脱离了ARDUINO IDE,所以需要研究AVR单片机的熔丝位设置问题. 刷ATMEGA32U4芯片,需要这样设置: ...
- jquery之闭包
闭包 常见形式是函数A里面定义一个函数B,并返回函数体的引用,很抽象是不是,具体代码如下: function wenwa() { ; function cj() { console.log(" ...
- js中toFixed()函数出现小数点后的多位数的原因
不演示示例了. 强调一点就是:toFixed()返回的str类型,所以如果想写成百分之多少的情况下,建议直接在分子上乘100后,在除以总和,再使用toFixed()函数保留几位小数.不然会出现如下:7 ...
- JAVA 日期操作
1.用java.util.Calender来实现 Calendar calendar=Calendar.getInstance(); calendar.setTime(new Date()); Sys ...
- BOOST 解析,修改,生成xml样例
解析XML 解析iworld XML,拿到entity和VisibleVolume的数据 int ParseiWorlds::readXML(const bpath &dir) { ptree ...
- 列表控件 ListBox、ComboBox
列表控件可以当作容器,内部可以有RadioButton.CheckBox.StackPanel等.即Items类型多样. ListBox,多个Item可被选中:ComboBox,只能有一个Item被选 ...
- [Flask]sqlalchemy使用count()函数遇到的问题
sqlalchemy使用count()函数遇到的问题 在使用flask-sqlalchemy对一个千万级别表进行count操作时,出现了耗时严重.内存飙升的问题. 原代码: # 统计当日登陆次数 co ...
- luoguP3373 【模板】线段树 2
P3373 [模板]线段树 2 969通过 3.9K提交 题目提供者 HansBug 标签 云端↑ 难度 提高+/省选- 时空限制 1s / 128MB 题目描述 如题,已知一个数列,你需要进行下面两 ...
- K8s中RS和Deployment
什么是ReplicaSet? ReplicaSet是下一代复本控制器.ReplicaSet和 Replication Controller之间的唯一区别是现在的选择器支持.Replication Co ...
- svn的下载与安装,使用,包教包会!!!
svn的安装使用说明 下载svn服务器与搭建 高效开发 — SVN使用教程(客户端与服务端安装详解!带图!带注释!安装客户端与服务端的地址可以看上两个链接) svn安装分为两部分,服务端安装与客户端安 ...