Solr 集成ikanalyzer
Solr 不能对中文进行分词,ikanalyzer可以。
ikanalyzer下载链接
1.下载 jar形式
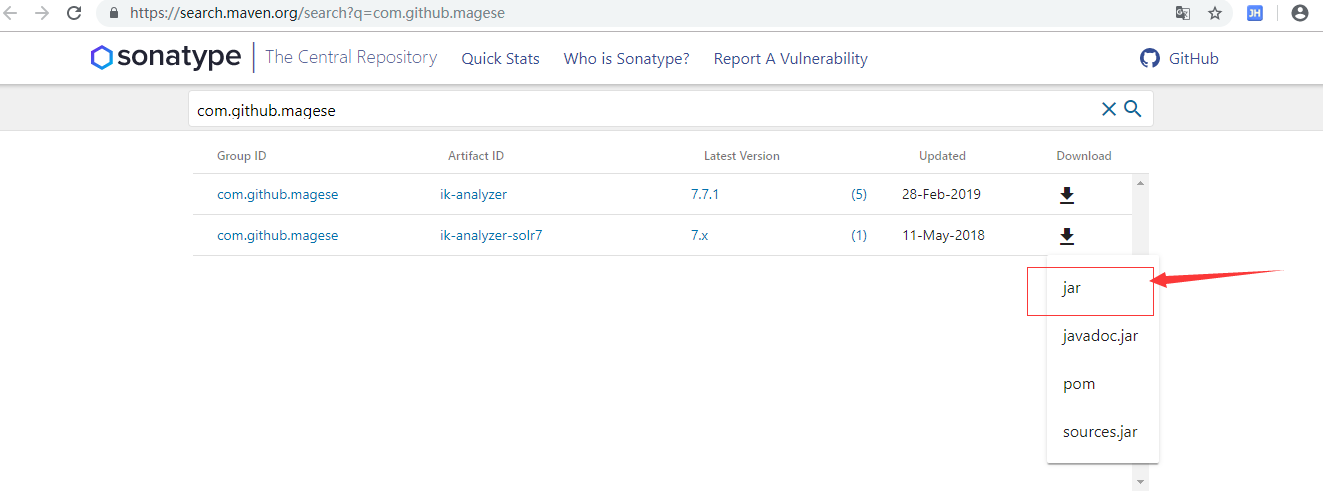
2.放到D:\soft\solr-8.1.0\server\solr-webapp\webapp\WEB-INF\lib路径下
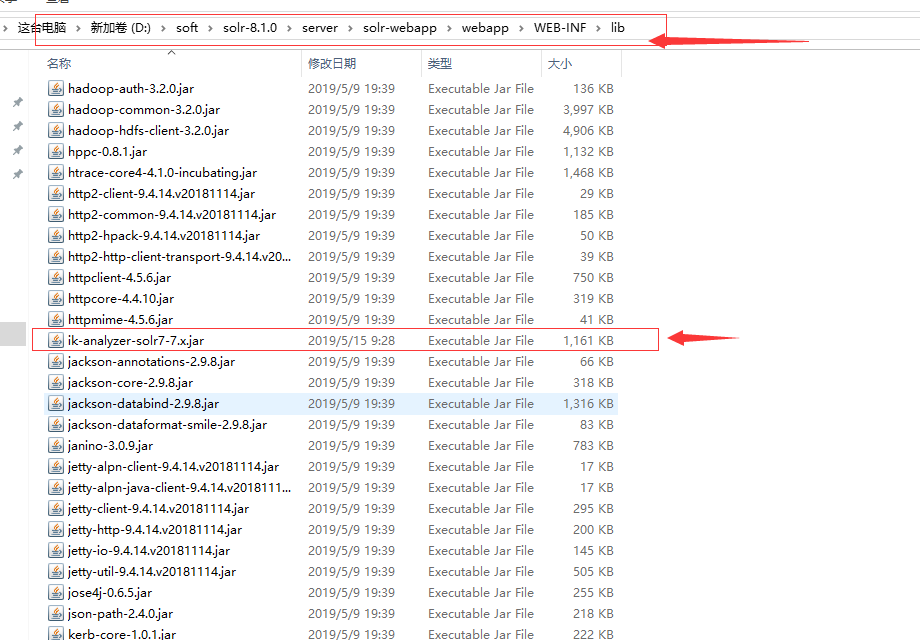
3.在路径D:\soft\solr-8.1.0\server\solr下,新建一个mycore
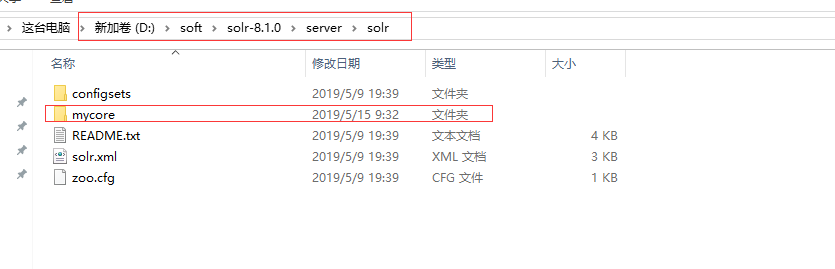
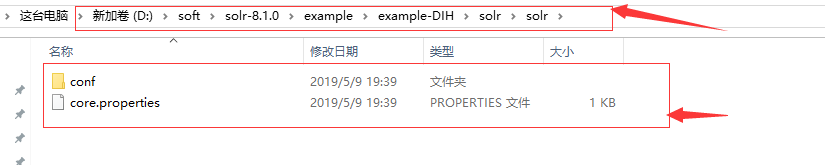
4. 复制 路径D:\soft\solr-8.1.0\example\example-DIH\solr\solr下所有文件,放到D:\soft\solr-8.1.0\server\solr\mycore
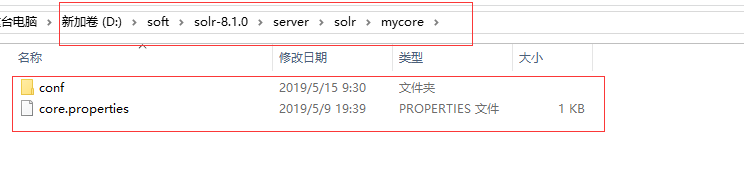
5.找到D:\soft\solr-8.1.0\server\solr\mycore\conf 路径下的managed-schema文件,打开,加入下面的代码
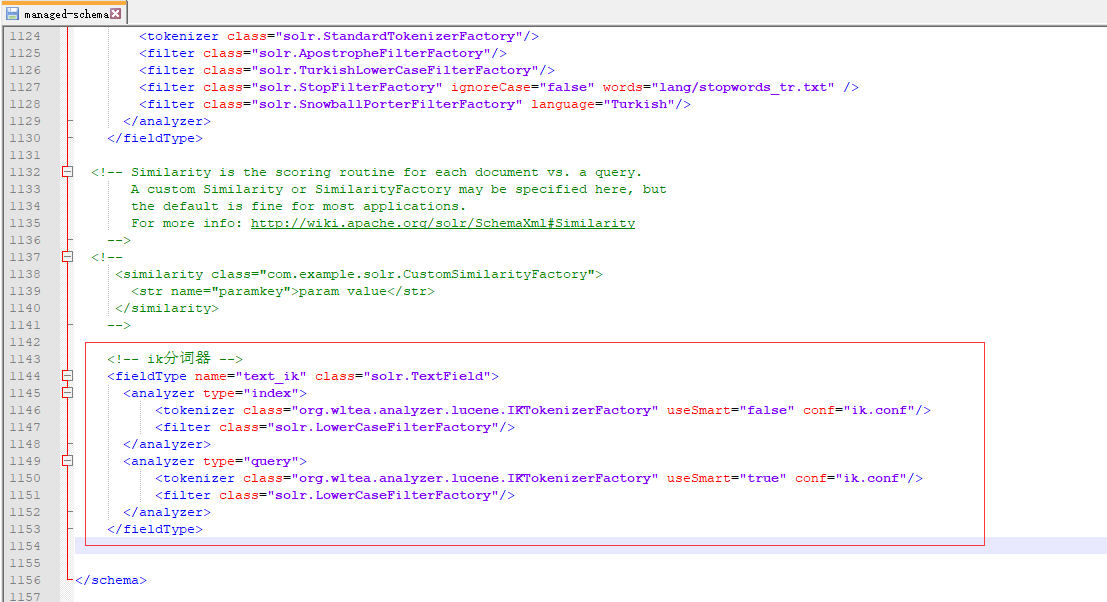
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
6.重启solr solr restart -p 8983 ,浏览器 输入 : http://localhost:8983


7.自定义分词索引
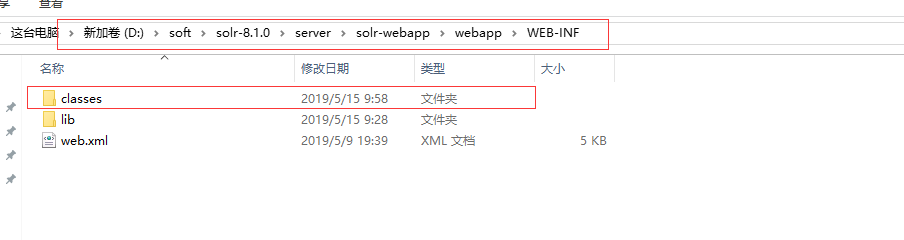
7.1 在路径D:\soft\solr-8.1.0\server\solr-webapp\webapp\WEB-INF下,新建classes文件。
7.2 解压 ik-analyzer-solr7-7.x.jar ,复制 ext.dic,IKAnalyzer.cfg.xml,stopword.dic 这三个文件。
7.3 将上面复制的三个文件放到classes里。

8.对比测试 在ext.dic文件里加上一个索引: 黑夜给了我黑色的眼睛,
然后重启solr solr restart -p 8983 ,浏览器 输入 : http://localhost:8983
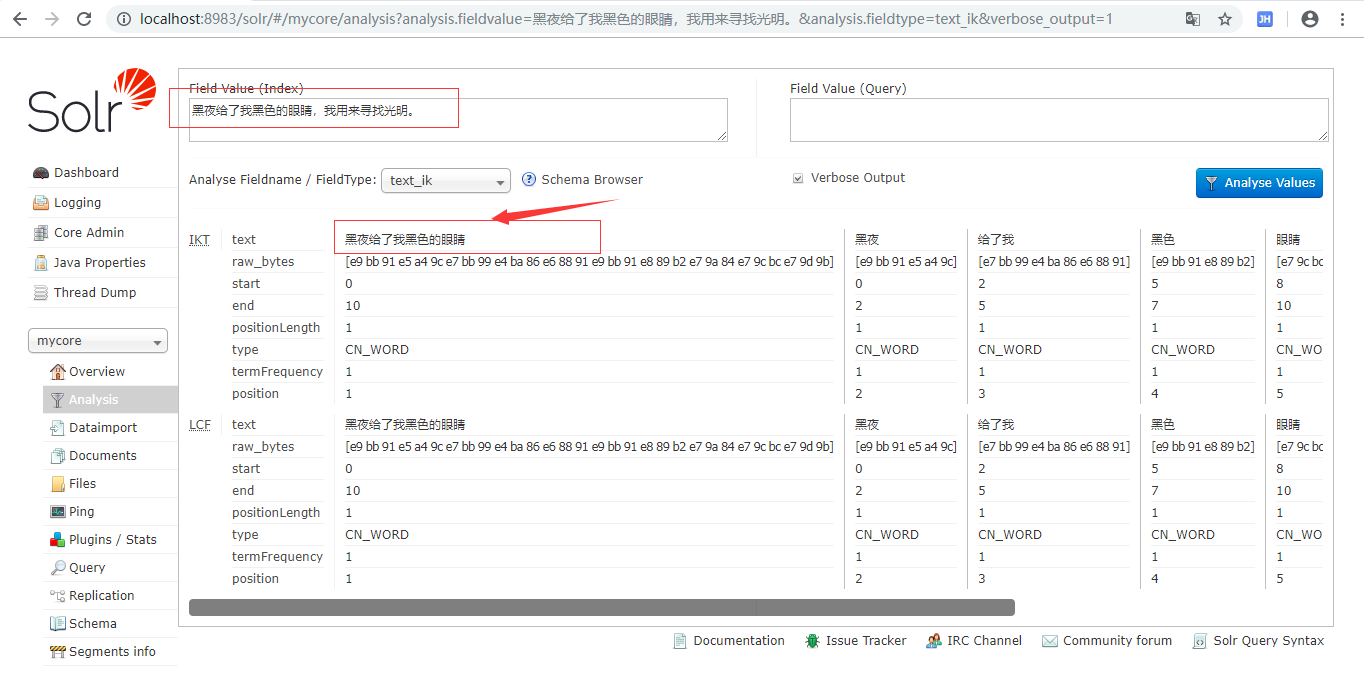
参考文章 : solr7.3 环境搭建 配置中文分词器 ik-analyzer-solr7 详细步骤
Solr 集成ikanalyzer的更多相关文章
- solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务:今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索. 在solr服务中集成IKAnalyzer中文分词器的步骤: ...
- elasticsearch系列一:elasticsearch(ES简介、安装&配置、集成Ikanalyzer)
一.ES简介 1. ES是什么? Elasticsearch 是一个开源的搜索引擎,建立在全文搜索引擎库 Apache Lucene 基础之上 用 Java 编写的,它的内部使用 Lucene 做索引 ...
- elasticsearch系列一elasticsearch(ES简介、安装&配置、集成Ikanalyzer)
一.ES简介 1. ES是什么? Elasticsearch 是一个开源的搜索引擎,建立在全文搜索引擎库 Apache Lucene 基础之上 用 Java 编写的,它的内部使用 Lucene 做索引 ...
- solr集成mmseg4j分词
solr集成mmseg4j分词 mmseg4j https://code.google.com/p/mmseg4j/ https://github.com/chenlb/mmseg4j-solr 作者 ...
- nutch和solr集成
Linux下的Nutch和solr集成 3.1.Nutch安装 l 解压 tar -zxvf apache-nutch-1.4-bin.tar.gz l 终端下cd到目录 apache-nutch- ...
- solr配置IKAnalyzer抛出ClassNotFoundException
这个问题搞了很久,在QQ群上问了很久,关键很气人的是我居然被群主给开了.我也是醉了.我不知道我哪里得罪了那个solr群的群主. 废话不多说.抛出的异常如下: 刚开始一直认为是没有找到类,也就相当于没找 ...
- 玩转大数据系列之Apache Pig如何与Apache Solr集成(二)
散仙,在上篇文章中介绍了,如何使用Apache Pig与Lucene集成,还不知道的道友们,可以先看下上篇,熟悉下具体的流程. 在与Lucene集成过程中,我们发现最终还要把生成的Lucene索引,拷 ...
- Solr集成IK中文分词器
1.将IKAnalyzer-2012-4x.jar拷贝到example\solr-webapp\webapp\WEB-INF\lib下: 2.在schema.xml文件中添加fieldType: &l ...
- Solr配置Ikanalyzer分词器
上一篇文章讲解在win系统中如何安装solr并创建一个名为test_core的Core,接下为text_core配置Ikanalyzer 分词器 1.打开text_core的instanceDir目录 ...
随机推荐
- MySQL binlog反解析
反解析delete语句 背景:delete table忘了加条件导致整张表被删除 恢复方式:直接从binlog里反解析delete语句为insert进行恢复 导出删指定表的DELETE语句: # my ...
- 修改mysql/MariaDB数据库的端口号+远程
1.修改端口 2.远程+开放端口 (1)设置远程账号:xxx和密码yyyyyyygrant all privileges on *.* to 'xxx'@'%' identified by 'yyyy ...
- Git与其他VCS的差异
推荐:Git essentials 一共4集视频 对待数据 在对待不同版本数据问题上,分为两派:差异增量.直接快照 增量差异 Git 和其它版本控制系统(包括 Subversion 和近似工具)的主 ...
- 运维开发笔记整理-使用Django编写helloworld
运维开发笔记整理-使用Django编写helloworld 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.创建Django项目 1>.创建Django项目 djang ...
- Bootstrap学习地址
第一步:https://www.runoob.com/bootstrap/bootstrap-tutorial.html //菜鸟教程 第二步:https://v3.bootcss.com/gett ...
- linux网络编程之posix消息队列
在前面已经学习了System v相关的IPC,今天起学习posix相关的IPC,关于这两者的内容区别,简单回顾一下: 而今天先学习posix的消息队列,下面开始: 接下来则编写程序来创建一个posix ...
- LOJ 103子串查找——用hash代替kmp算法
题意 给出两个字符串 $s_1,s_2$,求 $s_2$ 在 $s_1$ 中出现的次数. 分析 预处理出两个字符串的哈希值,再逐位比较. 时间复杂度为 $O(n+m)$,和 $kmp$ 算法一样. 可 ...
- python - super 寻找继承关系
""" super 是根据当前类对象的 mro 的继承顺序进行函数的调用的 """ class Base(object): def fn(s ...
- js手机点击图片放大
点击每个图片获取到对应的img的url链接,再把链接给一个空img以此来实现 最终效果:
- 使用unittest测试(基础一)
#导入unittest单元测试框架 ##用例的方法前缀必须要以 test 开头的 #这是用来组织用例的 import unittest class TestDBQB(unittest.TestCase ...