《python解释器源码剖析》第5章--python中的tuple对象
5.0 序
我们知道对于tuple,就相当于不支持元素添加、修改、删除等操作的list
5.1 PyTupleObject对象
tuple的实现机制非常简单,可以看做是在list的基础上删除了增删改等操作。既然如此,那要元组有什么用呢?毕竟元组的功能只是list的子集。元组存在的最大一个特点就是,它可以作为字典的key、以及可以作为集合的元素。因为字典和集合存储数据的原理是哈希表,字典和集合我们后续章节会说。对于list这样的可变对象来说是可以动态改变的,而哈希值是一开始就计算好的,显然如果支持动态修改的话,那么哈希值肯定会变,这是不允许的。所以我们希望key是一个序列,显然元组再适合不过了。
从tuple的特点也能看出:tuple的底层是一个变长对象,但同时也是一个不可变对象。
typedef struct {
PyObject_VAR_HEAD
PyObject *ob_item[1];
} PyTupleObject;
可以看到,对于不可变对象来说,它底层结构体定义也非常简单。一个引用计数、一个类型、一个指针数组索引为1的元素的地址,至于这里为什么是1,而且我们在PyLongObject中好像看到索引也是1,这一点不必纠结,就把它当成第一个元素的内存地址即可。
并且我们发现不想列表,元组没有allocated,这是因为它是不可变的,不支持resize操作。至于维护的值,同样是指针组成的数组,数组里面的每一个指针都指向了具体的值。
5.2 PyTupleObject对象的创建
正如list一样,python创建PyTupleObject也提供了类似的初始化方法
PyObject *
PyTuple_New(Py_ssize_t size)
{
PyTupleObject *op;
Py_ssize_t i;
if (size < 0) {
PyErr_BadInternalCall();
return NULL;
}
#if PyTuple_MAXSAVESIZE > 0
if (size == 0 && free_list[0]) {
op = free_list[0];
Py_INCREF(op);
#ifdef COUNT_ALLOCS
tuple_zero_allocs++;
#endif
return (PyObject *) op;
}
if (size < PyTuple_MAXSAVESIZE && (op = free_list[size]) != NULL) {
free_list[size] = (PyTupleObject *) op->ob_item[0];
numfree[size]--;
#ifdef COUNT_ALLOCS
fast_tuple_allocs++;
#endif
/* Inline PyObject_InitVar */
#ifdef Py_TRACE_REFS
Py_SIZE(op) = size;
Py_TYPE(op) = &PyTuple_Type;
#endif
_Py_NewReference((PyObject *)op);
}
else
#endif
{
/* Check for overflow */
if ((size_t)size > ((size_t)PY_SSIZE_T_MAX - sizeof(PyTupleObject) -
sizeof(PyObject *)) / sizeof(PyObject *)) {
return PyErr_NoMemory();
}
op = PyObject_GC_NewVar(PyTupleObject, &PyTuple_Type, size);
if (op == NULL)
return NULL;
}
for (i=0; i < size; i++)
op->ob_item[i] = NULL;
#if PyTuple_MAXSAVESIZE > 0
if (size == 0) {
free_list[0] = op;
++numfree[0];
Py_INCREF(op); /* extra INCREF so that this is never freed */
}
#endif
#ifdef SHOW_TRACK_COUNT
count_tracked++;
#endif
_PyObject_GC_TRACK(op);
return (PyObject *) op;
}
和PyListObject初始化类似,同样需要做一些类型检测,内存是否溢出等等。
5.2.1 查看元素
tuple和list一样,支持通过索引来获取元素,并且两者的性能是类似的。
PyObject *
PyTuple_GetItem(PyObject *op, Py_ssize_t i)
{
//类型检测
if (!PyTuple_Check(op)) {
PyErr_BadInternalCall();
return NULL;
}
//索引是否越界
if (i < 0 || i >= Py_SIZE(op)) {
PyErr_SetString(PyExc_IndexError, "tuple index out of range");
return NULL;
}
//直接返回ob_item[i]
//转化成了PyTupleObject *,证明tuple里面存储的也是指针
//但是在python层面上,打印会自动打印指针所指向的值
return ((PyTupleObject *)op) -> ob_item[i];
}
5.2.2 设置元素
我们知道tuple是不可变的,但是如果我们非要设置会怎么样呢?
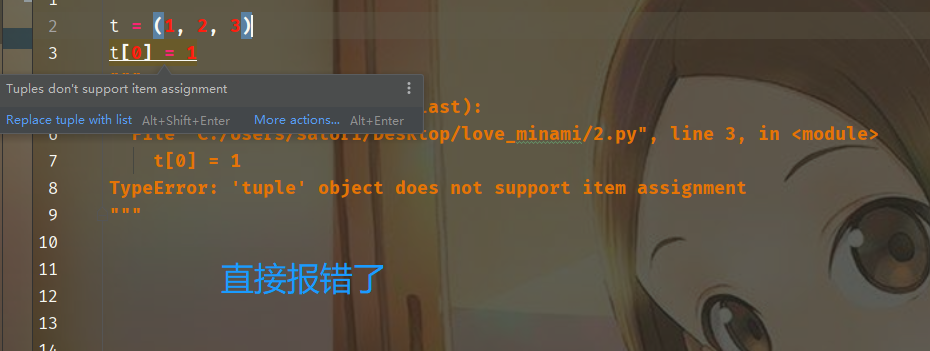
我们看一下源码
int
PyTuple_SetItem(PyObject *op, Py_ssize_t i, PyObject *newitem)
{
PyObject **p;
if (!PyTuple_Check(op) || op->ob_refcnt != 1) {
Py_XDECREF(newitem);
PyErr_BadInternalCall();
return -1;
}
if (i < 0 || i >= Py_SIZE(op)) {
Py_XDECREF(newitem);
PyErr_SetString(PyExc_IndexError,
"tuple assignment index out of range");
return -1;
}
p = ((PyTupleObject *)op) -> ob_item + i;
Py_XSETREF(*p, newitem);
return 0;
}
从源码上我们看到这个list是一样的啊,那python是怎么判断这是元组并且报错的呢?还记得我们之前说的tp_as_number,tp_as_sequence,tp_as_mapping吗?我们继续看,Object/abstract.c
int
PySequence_SetItem(PyObject *s, Py_ssize_t i, PyObject *o)
{
PySequenceMethods *m;
//s为NULL,也就是PYTHON中的None,直接报错返回-1
if (s == NULL) {
null_error();
return -1;
}
//获取对应类型的tp_as_sequence属性
m = s->ob_type->tp_as_sequence;
//如果m存在,像int就没有这个属性。
//但是字符串、和元组都有,因此还需要一层判断
//如果m->sq_ass_item还不为NULL的话,直接设置元素
//否则的话
if (m && m->sq_ass_item) {
if (i < 0) {
if (m->sq_length) {
Py_ssize_t l = (*m->sq_length)(s);
if (l < 0) {
assert(PyErr_Occurred());
return -1;
}
i += l;
}
}
return m->sq_ass_item(s, i, o);
}
//直接提示:xx不支持设置值
type_error("'%.200s' object does not support item assignment", s);
return -1;
}
5.3 静态资源缓存
列表和元组两者在通过索引查找元素的时候是一致的,但是元组除了能作为字典的key之外,还有一个特点,就是分配的速度比较快。一方面是因为由于其不可变性,使得在编译的时候就确定了,使得分配的速度快之外、另一方面就是它还具有静态资源缓存的作用。
对于一些静态变量,比如元组,如果它不被使用并且占用空间不大时,Python 会暂时缓存这部分内存。这样,下次我们再创建同样大小的元组时,Python 就可以不用再向操作系统发出请求,去寻找内存,而是可以直接分配之前缓存的内存空间,这样就能大大加快程序的运行速度。
from timeit import timeit
t1 = timeit(stmt="x1 = [1, 2, 3, 4, 5]", number=1000000)
t2 = timeit(stmt="x2 = (1, 2, 3, 4, 5)", number=1000000)
print(round(t1, 2)) # 0.05
print(round(t2, 2)) # 0.01
可以看到用时,元组只是列表的五分之一。这便是元组的另一个优势,可以将资源缓存起来。
《python解释器源码剖析》第5章--python中的tuple对象的更多相关文章
- 《python解释器源码剖析》第13章--python虚拟机中的类机制
13.0 序 这一章我们就来看看python中类是怎么实现的,我们知道C不是一个面向对象语言,而python却是一个面向对象的语言,那么在python的底层,是如何使用C来支持python实现面向对象 ...
- 《python解释器源码剖析》第12章--python虚拟机中的函数机制
12.0 序 函数是任何一门编程语言都具备的基本元素,它可以将多个动作组合起来,一个函数代表了一系列的动作.当然在调用函数时,会干什么来着.对,要在运行时栈中创建栈帧,用于函数的执行. 在python ...
- 《python解释器源码剖析》第9章--python虚拟机框架
9.0 序 下面我们就来剖析python运行字节码的原理,我们知道python虚拟机是python的核心,在源代码被编译成字节码序列之后,就将有python的虚拟机接手整个工作.python虚拟机会从 ...
- 《python解释器源码剖析》第0章--python的架构与编译python
本系列是以陈儒先生的<python源码剖析>为学习素材,所记录的学习内容.不同的是陈儒先生的<python源码剖析>所剖析的是python2.5,本系列对应的是python3. ...
- 《python解释器源码剖析》第1章--python对象初探
1.0 序 对象是python中最核心的一个概念,在python的世界中,一切都是对象,整数.字符串.甚至类型.整数类型.字符串类型,都是对象.换句话说,python中面向对象的理念观测的非常彻底,面 ...
- 《python解释器源码剖析》第11章--python虚拟机中的控制流
11.0 序 在上一章中,我们剖析了python虚拟机中的一般表达式的实现.在剖析一遍表达式是我们的流程都是从上往下顺序执行的,在执行的过程中没有任何变化.但是显然这是不够的,因为怎么能没有流程控制呢 ...
- 《python解释器源码剖析》第8章--python的字节码与pyc文件
8.0 序 我们日常会写各种各样的python脚本,在运行的时候只需要输入python xxx.py程序就执行了.那么问题就来了,一个py文件是如何被python变成一系列的机器指令并执行的呢? 8. ...
- 《python解释器源码剖析》第7章--python中的set对象
7.0 序 集合和字典一样,都是性能非常高效的数据结构,性能高效的原因就在于底层使用了哈希表.因此集合和字典的原理本质上是一样的,都是把值映射成索引,通过索引去查找. 7.1 PySetObject ...
- 《python解释器源码剖析》第4章--python中的list对象
4.0 序 python中的list对象,底层对应的则是PyListObject.如果你熟悉C++,那么会很容易和C++中的list联系起来.但实际上,这个C++中的list大相径庭,反而和STL中的 ...
- 《python解释器源码剖析》第2章--python中的int对象
2.0 序 在所有的python内建对象中,整数对象是最简单的对象.从对python对象机制的剖析来看,整数对象是一个非常好的切入点.那么下面就开始剖析整数对象的实现机制 2.1 初识PyLongOb ...
随机推荐
- LVS系列二、LVS集群-DR模式
一. LVS-DR和LVS-IP TUN集群概述 1. Direct Routing(直接路由) Director分配请求到不同的real server.real server处理请求后直接回应给用 ...
- Python统计分析可视化库seaborn(相关性图,变量分布图,箱线图等等)
Visualization of seaborn seaborn[1]是一个建立在matplot之上,可用于制作丰富和非常具有吸引力统计图形的Python库.Seaborn库旨在将可视化作为探索和理 ...
- Books Exchange (easy version) CodeForces - 1249B2
The only difference between easy and hard versions is constraints. There are nn kids, each of them i ...
- 2019-2020 ICPC, Asia Jakarta Regional Contest A. Copying Homework
Danang and Darto are classmates. They are given homework to create a permutation of N integers from ...
- 深入理解JVM(二)JVM内存模型
一.前言 上文讲过了虚拟机的内存划分,即,我们将内存分为线程共享和线程私有. 线程共享的即java堆,和方法区.java堆大家可能都不会陌生:而方法区中包含了常量池,他也被称为永久代.通常方法区也会被 ...
- AspxGridView 弹框选择器 JS
function Dictionary() { this.data = new Array(); this.put = function (key, value) { this.data[key] = ...
- openresty+lua+kafka方案与Tomcat接口并发度对比分析
1.openresty+lua+kafka 1.1 openresty+lua+kafka方案 之前的项目基于nginx反向代理后转发到Tomcat的API接口进行业务处理,然后将json数据打入ka ...
- RDP爆破方式攻击防控思路梳理
- PYTHON 100days学习笔记005:总结和练习
目录 day005:总结和练习 1.寻找水仙花数 2.寻找"完美数" 3."百鸡百钱"问题 4.生成"斐波那契数列" 5.Craps赌博游戏 ...
- 记录一次maven打包时将test目录下的类打包到jar中,Maven Assembly Plugin的使用
今天有人问我打包后找不到主类,运行的类写在test中.按照常规,test目录下的文件不会打包到jar包中.(但是我测试一个springboot工程就可以,这里之后再研究) 具体解决如下 第一步:在po ...