笔记:Hive的主要技术改进(Major Technical Advancements in Apache Hive)
- Introduction
hive的主要不足: 存储和查询计划执行。文中提出了三个主要的改进点 - 新的文件格式 ORC
- 查询计划组件优化(关联优化器correlation optimizer
- 向量执行模型,以充分利用CPU CACHE
- Hive architecture
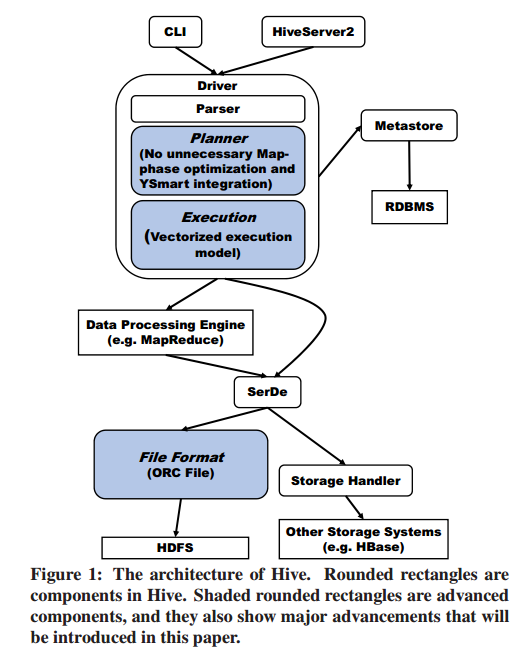
- 识别hive的不足
- 存储格式的不感知以及一次只能处理一行数据。在hive,存储效率由序列化和文件格式决定。以前支持的text和sequence格式,以及v0.4后支持的RCFile都是类型不感知的。RCFile每次只能处理一行数据。类型不感知意味着不能做有针对类型的优化;一次处理一行数据,意味着并行度低,并且序列化的压缩比低。
- 没有数据索引(包括统计汇总信息)以及不支持复杂数据类型。RCFile是为数据扫描设计的,并没有索引和提供其他语意以跳过无用的数据。不支持复杂类型的解析(如map、array),意味着访问该类型的任何一个成员,都要去读整个类型的数据。
- 忽略了数据操作之间的联系,导致出现很多的不必须shuffle。
- 每次处理一行数据也限制了对现代CPU缓存和并行处理的利用。
- 文件格式优化(ORC)
类型识别;支持刚类型的数据索引;支持复杂数据类型分解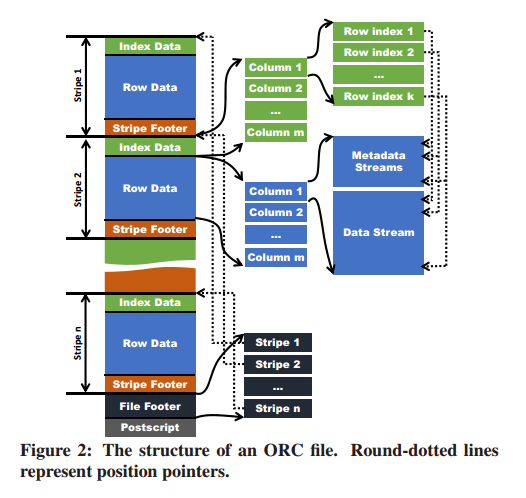
- 1 表的数据布局方式(The table placement method), 见上图。注意,ORC不支持将列放到列组里面。

优点1: stripe的缺省大小为256m(RCFile为4M)
优点2:支持复杂数据类型,见table1.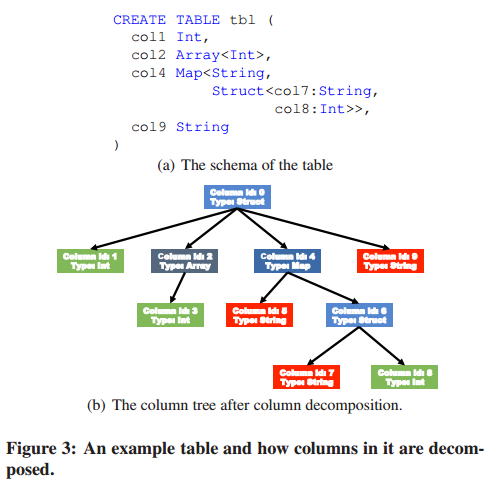
有点3: stripe的边界与hdfs的边界对齐。通常,stripe大小会小于hdfs的block大小,使用这种对齐,可以确保一个stripe始终保存在同一个block内部。 - 数据索引(Indexes)
处于加载速度的考虑,只使用稀疏索引。存在两种索引: - 数据统计信息(data statistics)。包括counter/mix/max/sum/len
数据统计信息分三个级别: 文件、stripe、逻辑数据块(缺省10000个value一个块,可配置) - 位置指针(position pointer)。
- 压缩。
有两个级别的压缩, - 基于类型的压缩。(string类型的压缩,如果去重后数量除以总数量大于0.8使用字典压缩,否则使用byte类型压缩。

- 通用压缩方式(可选)(e.g., gzip,snappy等,默认压缩窗口256k)
- 内存管理。根据内存的限制自动调节实际使用的stripe的大小。(应该是指每次读取数据块的大小)
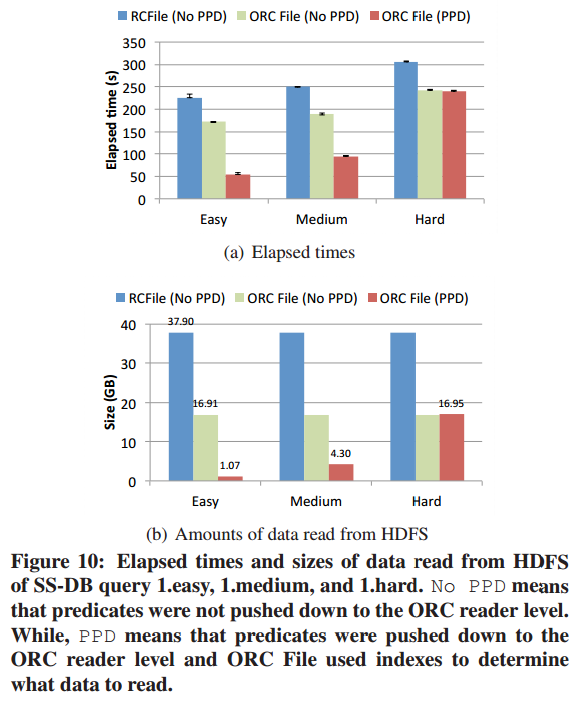
- 查询计划
三个不足点: - 不必要的Map阶段。由于一个MR job最多有一个shuffle,所以出现多个MR job很正常。MR的中间文件会回写到hdfs中的。如果一个map没有reduce,它就引入了一次没有必要的回写hdfs。
- 重复的数据加载。一个表被多次在不同MR中使用的情况下,这个表被多次加载。
- 不必要的数据重分片。
- 消除不必要的map phase.
Map-only job产生是因为MR job 被转换成了Map job。存在集中情况,其中最有代表性的是较小的表和大表之间的hash join。为了减少map phase,每次将reduce join转化为map join之前,计算map-only job中参与hash join操作的较小的表是否小于某个阈值,如果是就将这个map-only jion到他的子job中去。
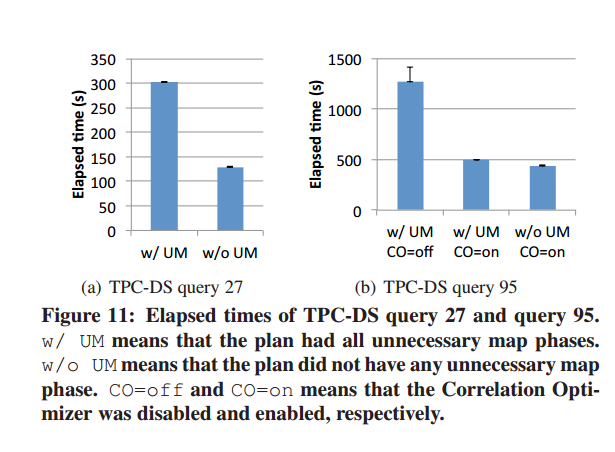
- 关联优化器(correlation optimizer)
基于YSmart(http://web.cse.ohio-state.edu/hpcs/WWW/HTML/publications/papers/TR-11-7.pdf )。
存在两种关联: - 输入关联(input correlation):意思是一个表在不同MR job中别使用多次。
- job flow correlation(工作流程关联):一个操作依赖于另一个操作,且这两种操作使用相同的数据分片方法。
有三个条件决定一个上游RSOp是否与一个下游RSOp关联: - 产生的行使用相同的排序方法;
- 使用相同的数据分片方法
- 没有reduce数量上的冲突(?)
- 操作树转换
- 必须有底层RSOp,用来产生行数据
- 添加DemuxOperator来减少不必要的RSOp。
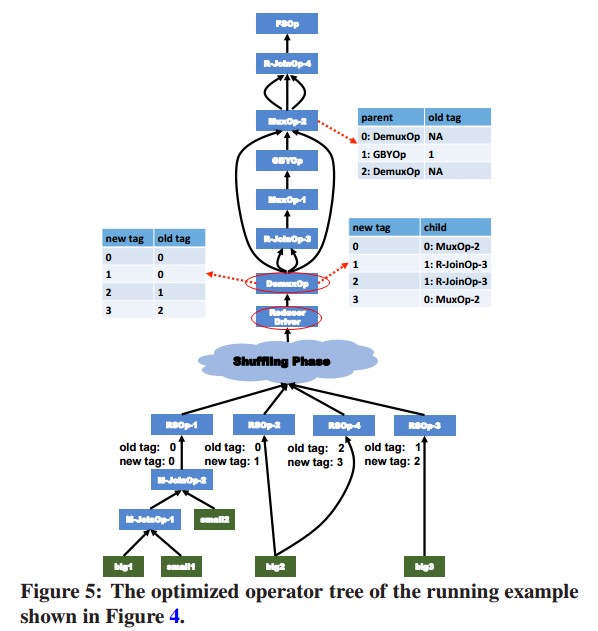
- 操作协调。
因为MR是push数据的,导致很多不必要的数据也被传输。所以需要一个协调器实现“按需传输”的功能。 - 查询执行
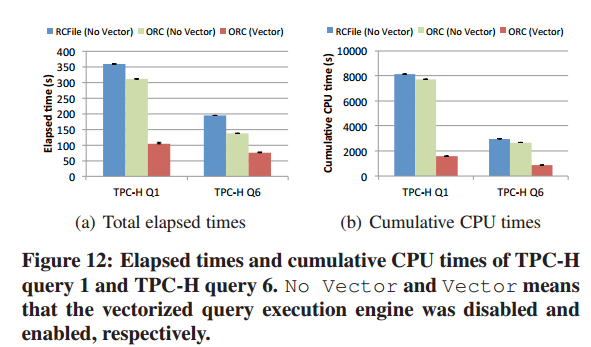
目的是充分利用现代cpu的特点。现代cpu的效率很大程度取决于并行度。为了实现多条流水线并行执行,需要减少指令分支。另外,数据的独立也有利于提高并行度。另外,一次执行一行导致cache性能低。 - 数据集代表批量的行(默认1024,可配置)。
- 单行模式下,一行数据被整棵查询树处理后才处理下一行;现在批量的行为单位执行了。


- 性能测试
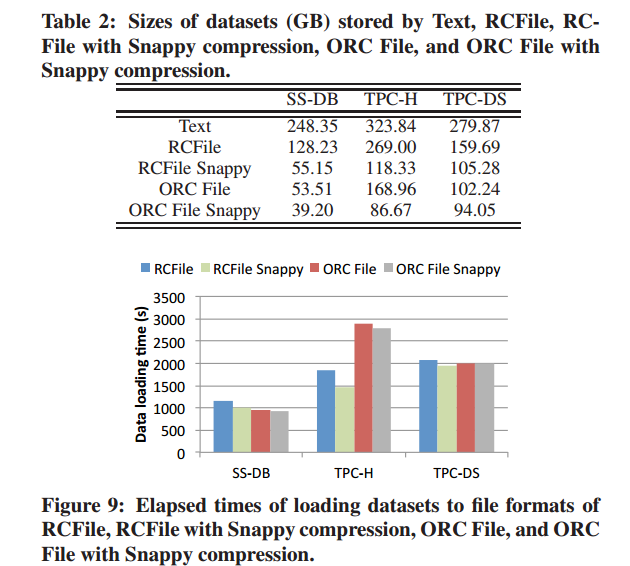
- file format
- 查询计划
- 查询执行
笔记:Hive的主要技术改进(Major Technical Advancements in Apache Hive)的更多相关文章
- 解决kylin sync table报错:MetaException(message:java.lang.ClassNotFoundException Class org.apache.hive.hcatalog.data.JsonSerDe not found
在kylin-gui中sync表default.customer_visit时报错: -- ::, ERROR [http-bio--exec-] controller.BasicController ...
- Hive执行count函数失败,Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException)
Hive执行count函数失败 1.现象: 0: jdbc:hive2://192.168.137.12:10000> select count(*) from emp; INFO : Numb ...
- 技术领导(Technical Leader)画像
程序员都讨厌被管理,而乐于被领导.管理的角色由PM(project manager)扮演,具体来说,PM负责提需求.改改改.大多数情况,PM是不懂技术的,这也是程序员觉得PM难以沟通的原因.而后者由技 ...
- 【学习笔记】大数据技术原理与应用(MOOC视频、厦门大学林子雨)
1 大数据概述 大数据特性:4v volume velocity variety value 即大量化.快速化.多样化.价值密度低 数据量大:大数据摩尔定律 快速化:从数据的生成到消耗,时间窗口小,可 ...
- webservice 技术改进
Webservice 技术改进 1.不同系统不同语言之间的交互 基于http协议进行传输,使用REST服务实现WS 2.不同系统相同语言之间的交互 使用RPC(romate process call) ...
- Android:日常学习笔记(9)———探究持久化技术
Android:日常学习笔记(9)———探究持久化技术 引入持久化技术 什么是持久化技术 持久化技术就是指将那些内存中的瞬时数据保存到存储设备中,保证即使在手机或电脑关机的情况下,这些数据仍然不会丢失 ...
- [转帖]我最近研究了hive的相关技术,有点心得,这里和大家分享下。
我最近研究了hive的相关技术,有点心得,这里和大家分享下. https://www.cnblogs.com/sharpxiajun/archive/2013/06/02/3114180.html 首 ...
- 深入探索Android热修复技术原理读书笔记 —— 资源热修复技术
该系列文章: 深入探索Android热修复技术原理读书笔记 -- 热修复技术介绍 深入探索Android热修复技术原理读书笔记 -- 代码热修复技术 1 普遍的实现方式 Android资源的热修复,就 ...
- 系统解析Apache Hive
Apache Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供一种HQL语言进行查询,具有扩展性好.延展性好.高容错等特点,多应用于离线数仓建设. 1. ...
随机推荐
- IDEA GIT 忽略文件
1.装插件 .igore 2.新建忽略文件格式 3.编辑忽略后缀文件 可以是文件夹 也可以是 具体文件类型
- 怎么解决Win7电脑更新出现80072EE2代码的错误?
我们在使用Win7系统时经常会遇到更新,这些更新可以修复一些系统漏洞,提高系统的安全性.但有时我们在进行相关更新时会出现错误,而导致最后的更新失败.下面好系统重装助手就和大家分享一下Win7系统更新出 ...
- android提升
https://blog.csdn.net/lou_liang/article/details/82856531
- opencv读取图像python和c++版本的结果不同
问题: 在读取同一张图像时,python读取的结果和c++读取的结果差异较大,测试图像中最大误差达到16. 原因: python的opencv采用的是4.1.1,c++采用的是3.1.0,在解析JPE ...
- web开发: css高级与盒模型
一.组合选择器 二.复制选择器优先级 三.伪类选择器 四.盒模型 五.盒模型显示区域 六.盒模型布局 一.组合选择器 <!DOCTYPE html> <html> <he ...
- hdu4786 Fibonacci Tree[最小生成树]【结论题】
一道结论题:如果最小生成树和最大生成树之间存在fib数,成立.不存在或者不连通则不成立.由于是01图,所以这个区间内的任何生成树都存在. 证明:数学归纳?如果一棵树没有办法再用非树边0边替代1边了,那 ...
- es高级用法之冷热分离
背景 用户需求:近期数据查询速度快,较远历史数据运行查询速度慢? 对于开发人员而言即数据的冷热分离,实现此功能有2个前提条件: 硬件:处理速度不同的硬件,最起码有读写速度不同的硬盘,如SSD.机械硬盘 ...
- 如何实现swipe、tap、longTap等自定义事件
前言 移动端原生支持touchstart.touchmove.touchend等事件,但是在平常业务中我们经常需要使用swipe.tap.doubleTap.longTap等事件去实现想要的效果,对于 ...
- Hbuilder + MUI 修改App 启动的首页面
- [MySQL优化] -- 如何查找SQL效率地下的原因
[MySQL优化] -- 如何查找SQL效率地下的原因 来源: ChinaUnix博客 日期: 2009.07.20 16:12 (共有条评论) 我要评论 查询到效率低的 SQL 语句 ...