[Pytorch框架] 1.5 Neural Networks
文章目录
Neural Networks
使用torch.nn包来构建神经网络。
上一讲已经讲过了autograd,nn包依赖autograd包来定义模型并求导。
一个nn.Module包含各个层和一个forward(input)方法,该方法返回output。
例如:
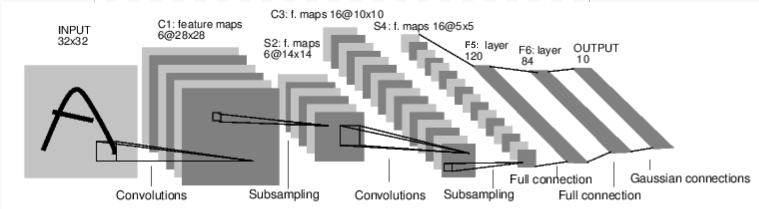
它是一个简单的前馈神经网络,它接受一个输入,然后一层接着一层地传递,最后输出计算的结果。
神经网络的典型训练过程如下:
- 定义包含一些可学习的参数(或者叫权重)神经网络模型;
- 在数据集上迭代;
- 通过神经网络处理输入;
- 计算损失(输出结果和正确值的差值大小);
- 将梯度反向传播回网络的参数;
- 更新网络的参数,主要使用如下简单的更新原则:
weight = weight - learning_rate * gradient
定义网络
开始定义一个网络:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
Net(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
在模型中必须要定义 forward 函数,backward
函数(用来计算梯度)会被autograd自动创建。
可以在 forward 函数中使用任何针对 Tensor 的操作。
net.parameters()返回可被学习的参数(权重)列表和值
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1's .weight
10
torch.Size([6, 1, 5, 5])
测试随机输入32×32。
注:这个网络(LeNet)期望的输入大小是32×32,如果使用MNIST数据集来训练这个网络,请把图片大小重新调整到32×32。
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)
tensor([[ 0.1120, 0.0713, 0.1014, -0.0696, -0.1210, 0.0084, -0.0206, 0.1366,
-0.0455, -0.0036]], grad_fn=<AddmmBackward>)
将所有参数的梯度缓存清零,然后进行随机梯度的的反向传播:
net.zero_grad()
out.backward(torch.randn(1, 10))
Note
``torch.nn`` 只支持小批量输入。整个 ``torch.nn`` 包都只支持小批量样本,而不支持单个样本。
例如,``nn.Conv2d`` 接受一个4维的张量,
``每一维分别是sSamples * nChannels * Height * Width(样本数*通道数*高*宽)``。
如果你有单个样本,只需使用 ``input.unsqueeze(0)`` 来添加其它的维数</p></div>
在继续之前,我们回顾一下到目前为止用到的类。
回顾:
torch.Tensor:一个用过自动调用backward()实现支持自动梯度计算的 多维数组 ,
并且保存关于这个向量的梯度 w.r.t.nn.Module:神经网络模块。封装参数、移动到GPU上运行、导出、加载等。nn.Parameter:一种变量,当把它赋值给一个Module时,被 自动 地注册为一个参数。autograd.Function:实现一个自动求导操作的前向和反向定义,每个变量操作至少创建一个函数节点,每一个Tensor的操作都回创建一个接到创建Tensor和 编码其历史 的函数的Function节点。
重点如下:
- 定义一个网络
- 处理输入,调用backword
还剩:
- 计算损失
- 更新网络权重
损失函数
一个损失函数接受一对 (output, target) 作为输入,计算一个值来估计网络的输出和目标值相差多少。
译者注:output为网络的输出,target为实际值
nn包中有很多不同的损失函数。
nn.MSELoss是一个比较简单的损失函数,它计算输出和目标间的均方误差,
例如:
output = net(input)
target = torch.randn(10) # 随机值作为样例
target = target.view(1, -1) # 使target和output的shape相同
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)
tensor(0.8109, grad_fn=<MseLossBackward>)
现在,如果在反向过程中跟随loss , 使用它的
.grad_fn 属性,将看到如下所示的计算图。
::
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> view -> linear -> relu -> linear -> relu -> linear
-> MSELoss
-> loss
所以,当我们调用 loss.backward()时,整张计算图都会
根据loss进行微分,而且图中所有设置为requires_grad=True的张量
将会拥有一个随着梯度累积的.grad 张量。
为了说明,让我们向后退几步:
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU
<MseLossBackward object at 0x7f3b49fe2470>
<AddmmBackward object at 0x7f3bb05f17f0>
<AccumulateGrad object at 0x7f3b4a3c34e0>
反向传播
调用loss.backward()获得反向传播的误差。
但是在调用前需要清除已存在的梯度,否则梯度将被累加到已存在的梯度。
现在,我们将调用loss.backward(),并查看conv1层的偏差(bias)项在反向传播前后的梯度。
net.zero_grad() # 清除梯度
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
conv1.bias.grad before backward
tensor([0., 0., 0., 0., 0., 0.])
conv1.bias.grad after backward
tensor([ 0.0051, 0.0042, 0.0026, 0.0152, -0.0040, -0.0036])
如何使用损失函数
稍后阅读:
nn包,包含了各种用来构成深度神经网络构建块的模块和损失函数,完整的文档请查看here。
剩下的最后一件事:
- 新网络的权重
更新权重
在实践中最简单的权重更新规则是随机梯度下降(SGD):
``weight = weight - learning_rate * gradient``
我们可以使用简单的Python代码实现这个规则:
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
但是当使用神经网络是想要使用各种不同的更新规则时,比如SGD、Nesterov-SGD、Adam、RMSPROP等,PyTorch中构建了一个包torch.optim实现了所有的这些规则。
使用它们非常简单:
import torch.optim as optim
# create your optimizer
optimizer = optim.SGD(net.parameters(), lr=0.01)
# in your training loop:
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # Does the update
… 注意::
观察如何使用``optimizer.zero_grad()``手动将梯度缓冲区设置为零。
这是因为梯度是按Backprop部分中的说明累积的。
[Pytorch框架] 1.5 Neural Networks的更多相关文章
- PyTorch Tutorials 3 Neural Networks
%matplotlib inline Neural Networks 使用torch.nn包来构建神经网络. 上一讲已经讲过了autograd,nn包依赖autograd包来定义模型并求导. 一个nn ...
- pytorch -- CNN 文本分类 -- 《 Convolutional Neural Networks for Sentence Classification》
论文 < Convolutional Neural Networks for Sentence Classification>通过CNN实现了文本分类. 论文地址: 666666 模型图 ...
- Quantization aware training 量化背后的技术——Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
1,概述 模型量化属于模型压缩的范畴,模型压缩的目的旨在降低模型的内存大小,加速模型的推断速度(除了压缩之外,一些模型推断框架也可以通过内存,io,计算等优化来加速推断). 常见的模型压缩算法有:量化 ...
- Exploring Adversarial Attack in Spiking Neural Networks with Spike-Compatible Gradient
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:2001.01587v1 [cs.NE] 1 Jan 2020 Abstract 脉冲神经网络(SNN)被广泛应用于神经形态设 ...
- Machine Learning - 第5周(Neural Networks: Learning)
The Neural Network is one of the most powerful learning algorithms (when a linear classifier doesn't ...
- 论文笔记之:Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking arXiv Paper ...
- 论文笔记之:Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
Learning Multi-Domain Convolutional Neural Networks for Visual Tracking CVPR 2016 本文提出了一种新的CNN 框架来处理 ...
- Recurrent Neural Networks(RNN) 循环神经网络初探
1. 针对机器学习/深度神经网络“记忆能力”的讨论 0x1:数据规律的本质是能代表此类数据的通用模式 - 数据挖掘的本质是在进行模式提取 数据的本质是存储信息的介质,而模式(pattern)是信息的一 ...
- 3D Graph Neural Networks for RGBD Semantic Segmentation
3D Graph Neural Networks for RGBD Semantic Segmentation 原文章:https://www.yuque.com/lart/papers/wmu47a ...
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节5.2-5.3,Neural Networks神经网络训练(BP算法)
转载请注明出处:http://www.cnblogs.com/xbinworld/p/4265530.html 这一篇是整个第五章的精华了,会重点介绍一下Neural Networks的训练方法——反 ...
随机推荐
- CV入坑
https://www.cnblogs.com/fldev/p/14360149.html
- C Ⅷ
数组 int number[100]; //这个数组可以放100个数 int x; int cnt = 0; double sum = 0; scanf("%d", & ...
- 修改word文档中已有的批注者名称
前言 https://blog.csdn.net/hyh19962008/article/details/89430548 word中可以通过修改用户的信息实现新建的批注者显示不同的名称,但是对于文档 ...
- Java集合框架个人总结
Java集合框架个人总结 集合主要分为两大类:①单列集合Collection ②双列集合Map 集合存储的都是引用类型,不可是基础类型,如果保存基础类型需要用包装类. 1.Collection接口 ...
- sql生成code
- 思考20230208-关于chatGPT
最近的ChatGPT火了,我今天FQ.充了1 USD买了个虚拟手机号创建了openAI 的账号,试了一把,它的表现令我叹为观止.他已经不再是简单的基于海量数据在网络上搜索已有的答案,而是会根据用户的想 ...
- TortoiseGit自动保存用户名和密码
在使用TortoiseGit上传时,会多次提示输入用户名和密码,采用以下方法解决 1.桌面点击右键 -> 选择TortoiseGit -> 点击settings 2.点击选择Git 3.点 ...
- Centos7安装nodejs(npm)
执行命令: 设置yum安装源> curl --silent --location https://rpm.nodesource.com/setup_14.x | sudo bash (14是大的 ...
- OSPF V3协议简介
LSA1/LSA 2在ospfv3中,变成了只携带拓扑信息,区域内的路由信息注意到LSA 9中
- vue路由重复跳转导致控制台报错
重复跳转了同一个页面,导致空值台报错了! 解决思路: 方案1:在路由跳转时捕获错误. 1.1 全局捕获处理 //index.js import VueRouter from 'vue-router' ...