[人脸活体检测] 论文: Learning Deep Models for Face Anti-Spoofing: Binary or Auxiliary Supervision
Learning Deep Models for Face Anti-Spoofing: Binary or Auxiliary Supervision
论文简介
与人脸生理相关的rppG信号被研究者广泛运用于活体检测,文[3]中使用了CNN和RNN分别预测人脸深度和rppG信号提升了活体检测的精度。
文章引用量:50+
推荐指数:✦✦✦✦✦
[3] Liu Y, Jourabloo A, Liu X. Learning deep models for face anti-spoofing: Binary or auxiliary supervision[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 389-398.
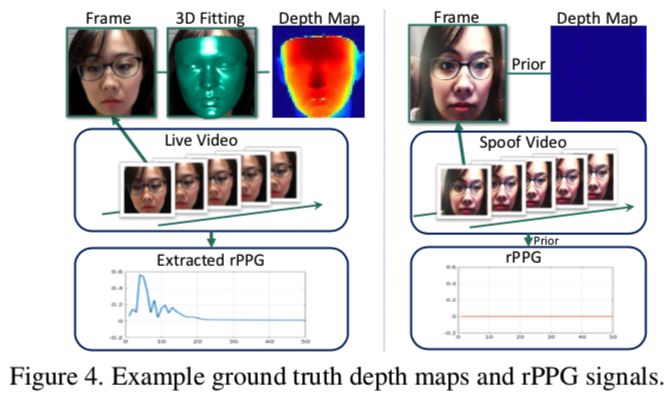
作者认为现存大多数活体算法用binary classification监督不够合理,也不能说明预测结果的依据(模型是否学习到真正的活体与攻击之间差异),故提出CNN-RNN框架,采用pixel-wise的深度图监督方式和sequence-wise的rPPG信号监督方式(如下图),并提出高分辨率+丰富PIE的数据集SiW;试验在cross-test取得了sota。
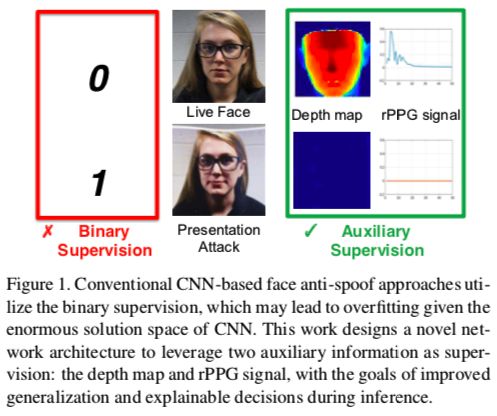
主要贡献:
- 提出用深度图和rPPG信号作为CNN学习的监督信息,提高模型泛化能力;
- 提出CNN-RNN框架,支持深度图和rPPG信号的end-to-end训练;
- 发布全新数据集,包含多种PIE和其他影响因素,并取得sota。
方法介绍:
首先我们看rPPG是什么,Remote Photoplethysmography (rPPG)是在不接触人体皮肤的情况下,跟踪如心率等重要信号的技术。作者引用了很多文献来解释rPPG的发展,然而结论却是,分析这种信号的解决方案太容易实现了,那么它一定很容易受到PIE变化的影响!因此,作者用RNN来学习从人脸视频到rPPG信号的映射,对于PIE变化可能不够鲁棒,但是足够区分真人和攻击。
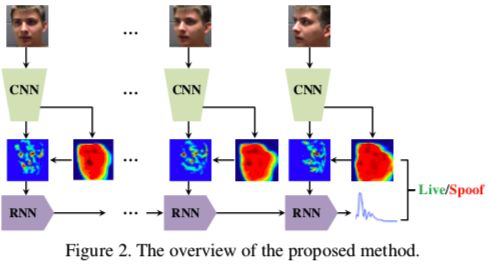
1. Face Anti-Spoofing with Deep Network
如Figure 2所示,先用CNN提取特征,用深度图做监督信息,然后把预测的深度图和最后一层的特征图输入到non-rigid registration layer,获得aligned后的特征图,再用aligned的特征图和rPPG监督信息训练RNN,使其通过视频序列获得区分真人和攻击的能力。
2. 深度图监督
深度图是二维图像的三维信息表达,表示不同区域和相机之间不同距离。这种表达比二维标签传达出更多的信息,可以从根本上区分真人与打印、视频回放的攻击方式。作者用DeFA估计3D信息(具体的没太看懂),考虑到绝对深度不方便训练也没太大作用,就将深度归一化到[0, 1],再用z-Buffer算法把归一化的z值映射回2D图像,这样作为CNN部分pixel-wise监督信息的“ground truth”就产生了。
3. rPPG 监督
rPPG信号最近已经被用到活体识别领域了,为face liveness提供时域信息,这类信息与血液流动高度相关。传统的rPPG信号提取方法有三个弊端:对姿态太敏感,很难跟踪某个特定的面部区域;对光照敏感,额外的光照会影响皮肤反光的总量;对于活体识别而言,从视频提取的rPPG信号可能无法与真实视频区分。
作者认为用RNN去估计rPPG信号可以有效解决上述所有问题,假设,同一subject的视频在不同PIE条件下的ground truth rPPG信号是相同的。由于同一人的心跳在视频中(拍摄时间小于5分钟)是相似的,所以假设有效。作者把某个subject的constrained(PIE 无变化)视频中提取出的rPPG信号作为这个subject所有rPPG信号的groundtruth。这种可持续的监督信息有助提升CNN和RNN的鲁棒性。作者用DeFA提取人脸区域用于计算两个正交色度信号,然后FFT变换至频域。
4. CNN网络
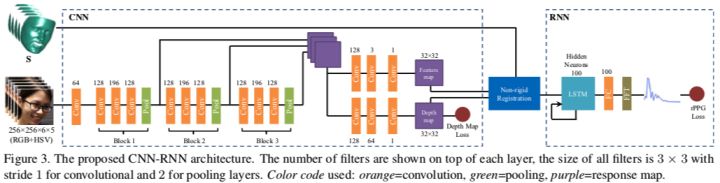
作者用了全卷积网络,包含三个block,每个block的输出都resize到64*64再合并。合并后的feature分别输入到两个分支,第一个分支用于估计深度图,目标函数:
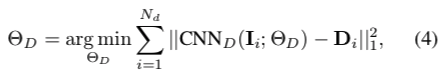
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-exIRa0F5-1606997701480)(https://www.zhihu.com/equation?tex=%5Ctheta)] D为CNN参数,Nd为训练集样本总数。第二个分支输入到non-rigid registration layer。
5. RNN网络
RNN网络基于图像序列估计rPPG信号,然后FFT变换到频域,目标函数:
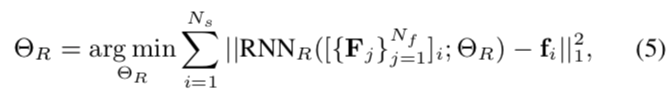
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QZTEcizG-1606997701482)(https://www.zhihu.com/equation?tex=%5Ctheta)]R是RNN参数,Fj是frontalized feature map,Ns是图像序列的总数。作者在FFT之后对FFT求Loss,那么bp的时候怎么FFT过乘求导呢?先IFFT么?既然FFT没有参数,为什么不把fc的输入接入loss呢,不解。
6. 实现
1)ground truth
作者按照2. 中方法生成深度图的ground truth,并把攻击样本的深度设为一个平面,如全部设为“0”;同样,按照3. 中方法生成rPPG的ground truth,并做L2归一化,攻击样本的rPPG设为“0”
2)训练策略
作者合并CNN和RNN,做端到端训练。CNN部分需要的数据需要打乱所有subject的所有样本,再分成多个batch,以此来维持训练的稳定性和模型的泛化能力,但是RNN模型需要某个subject的较长视频序列来利用跨帧的时域信息。这两方面是互相矛盾的,也对显存要求很高,为此作者设计了two-stream 策略:第一个stream满足CNN,输入为RGB图片和深度图“ground truth”;第二个stream满足RNN,输入是视频序列,深度图“ground truth”,预测的3Dshapes和rPPG “ground truth”。训练时,交替训练两个stream,训练CNN时只更新CNN参数,训练RNN时更新CNN和RNN的参数(很难理解,怎么通过non-rigid registration反传回去的)。
3)测试
输入视频序列,得到预测的深度图和rPPG信号,计算最后的
得分:

为常数权重,用来合并两个输出。
4)Non-rigid registration 层
作者设计non-rigid registration层,用于RNN输入数据的预处理。这一层用预测的稠密3Dshape align CNN输出的feature map的activations,确保RNN跟踪和学习到不同人脸同一部分的变化。如下图,该层有三个输入:CNN输出的feature map T,估计的深度图Dhat,3D shape S;首先把Dhat二值化,得到V,然后计算V和T的内积,得到U,相当于把V当成T的mask来使用。
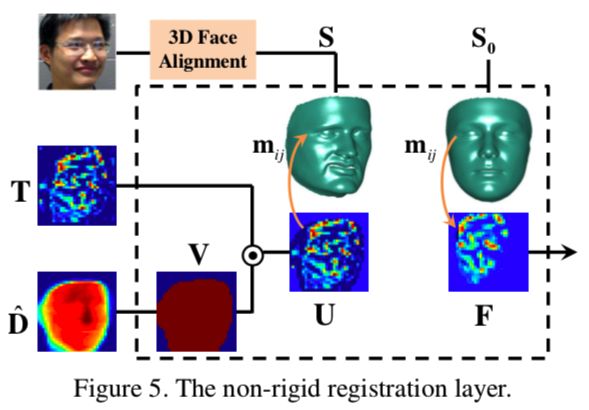
最后,用S frontalize U(不理解):
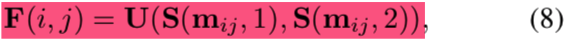
作者认为该层对整个网络有三个贡献:输入数据被对齐,RNN在学习特征是不受到面部姿态和表情的影响;减少feature map中背景的影响;对于攻击样本,深度图几乎接近0,因此和feature做内积时,极大弱化了feature map的activation,有利于RNN学习并输出的rPPG信号为0,因此,rPPG loss也有助于CNN产生值为0的深度图。
实验与结论:
作者在tf框架下进行试验,学习率为 3e-3,10个epoch,CNN stream batch 为10,CNN-RNN stream batch 为2,视频序列长度为5,公式(6)中为0.015,公式(7)的阈值为0.1。作者用APCER,BPCER,ACER,HTER作为测试的metric,ablation 测试结果如下:
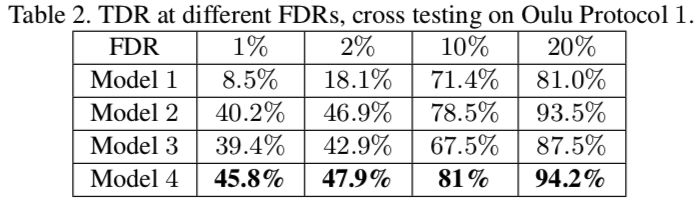
Model 1: CNN + pooling layer + fc layer + softmax
Model 2: CNN + depth map
Model 3: CNN + RNN + depth map + rPPG(w/o non-rigid registration)
Model 4: 作者提出的框架
作者用SiW数据集中的20个subject进行试验,显然本文提出的框架效果最好,作者还研究了不同视频长度对结果的影响,见下图,视频序列越长取得效果越好,对显存要求也就越高。
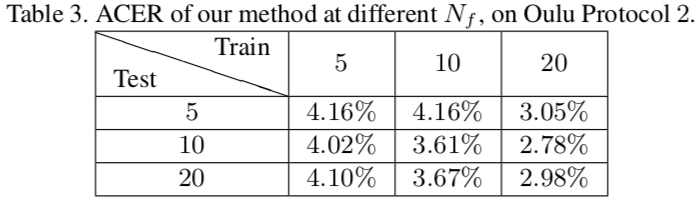
其他测试结果如下:
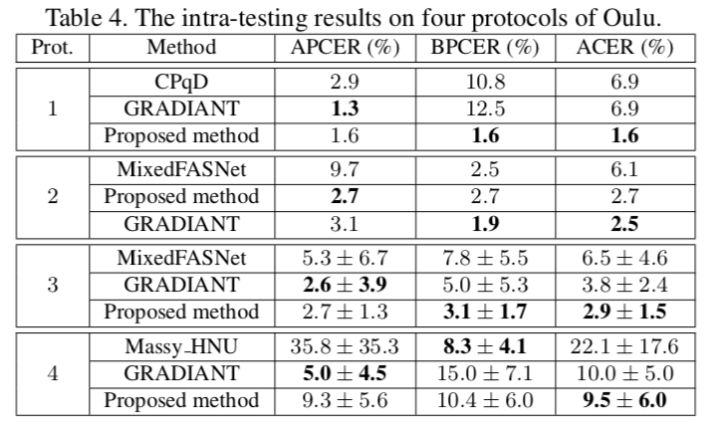
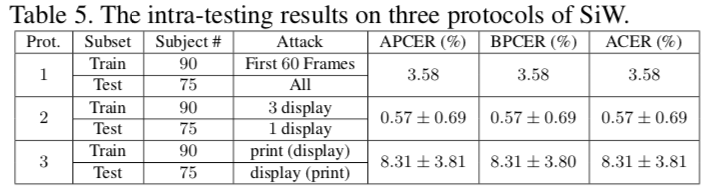
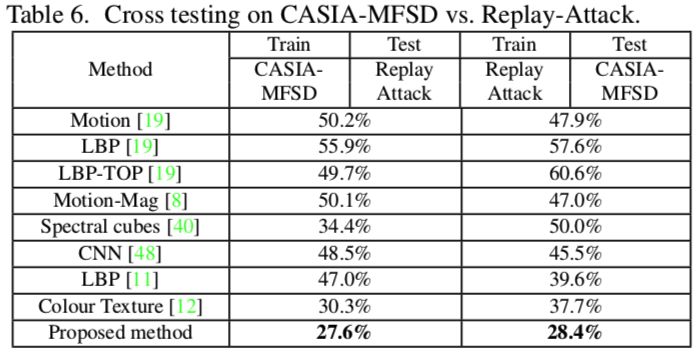
其他
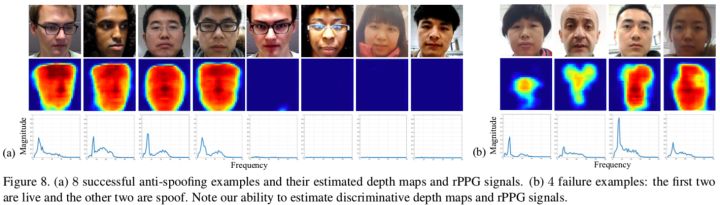
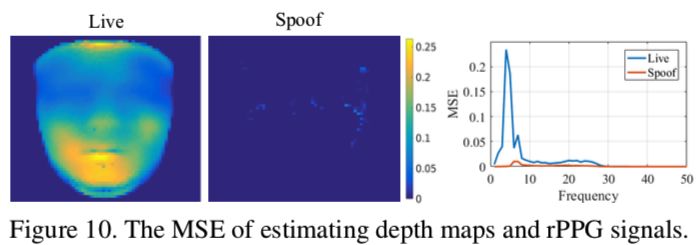
1)可视化
从下图可以看到,辅助的监督信息是有效的。

更多信息请关注公众号:

[人脸活体检测] 论文: Learning Deep Models for Face Anti-Spoofing: Binary or Auxiliary Supervision的更多相关文章
- 从零玩转人脸识别之RGB人脸活体检测
从零玩转RGB人脸活体检测 前言 本期教程人脸识别第三方平台为虹软科技,本文章讲解的是人脸识别RGB活体追踪技术,免费的功能很多可以自行搭配,希望在你看完本章课程有所收获. ArcFace 离线SDK ...
- 论文解读《Learning Deep CNN Denoiser Prior for Image Restoration》
CVPR2017的一篇论文 Learning Deep CNN Denoiser Prior for Image Restoration: 一般的,image restoration(IR)任务旨在从 ...
- 人脸标记检测:ICCV2019论文解析
人脸标记检测:ICCV2019论文解析 Learning Robust Facial Landmark Detection via Hierarchical Structured Ensemble 论 ...
- Qt编写百度离线版人脸识别+比对+活体检测
在AI技术发展迅猛的今天,很多设备都希望加上人脸识别功能,好像不加上点人脸识别功能感觉不够高大上,都往人脸识别这边靠,手机刷脸解锁,刷脸支付,刷脸开门,刷脸金融,刷脸安防,是不是以后还可以刷脸匹配男女 ...
- 虹软人脸识别 - faceId及IR活体检测的更新介绍
虹软人脸识别 - faceId及IR活体检测的介绍 前几天虹软推出了 Android ArcFace 2.2版本的SDK,相比于2.1版本,2.2版本中的变化如下: VIDEO模式新增faceId(类 ...
- python3 百度AI-v3之 人脸对比 & 人脸检测 & 在线活体检测 接口
#!/usr/bin/python3 # 百度人脸对比 & 人脸检测api-v3 import sys, tkinter.messagebox, ast import ssl, json,re ...
- 虹软人脸识别 - faceId及IR活体检测的介绍
虹软人脸识别 - faceId及IR活体检测的介绍 前几天虹软推出了 Android ArcFace 2.2版本的SDK,相比于2.1版本,2.2版本中的变化如下: VIDEO模式新增faceId(类 ...
- dlib人脸关键点检测的模型分析与压缩
本文系原创,转载请注明出处~ 小喵的博客:https://www.miaoerduo.com 博客原文(排版更精美):https://www.miaoerduo.com/c/dlib人脸关键点检测的模 ...
- Python 3 利用 Dlib 19.7 和 sklearn机器学习模型 实现人脸微笑检测
0.引言 利用机器学习的方法训练微笑检测模型,给一张人脸照片,判断是否微笑: 使用的数据集中69张没笑脸,65张有笑脸,训练结果识别精度在95%附近: 效果: 图1 示例效果 工程利用pytho ...
- Python 3 利用 Dlib 和 sklearn 人脸笑脸检测机器学习建模
0. 引言 利用机器学习的方法训练微笑检测模型,输入一张人脸照片,判断是否微笑: 精度在 95% 左右( 使用的数据集中 69 张没笑脸,65 张有笑脸 ): 图1 测试图像与检测结果 项目实现的笑脸 ...
随机推荐
- pageTools 一个复用的通知条
<template> <el-card class="page-tools"> <el-row type="flex" align ...
- R 曲线拐点
x = seq(1,15) y = c(4,5,6,5,5,6,7,8,7,7,6,6,7,8,9) plot(x,y,type="l",ylim=c(3,10)) lo < ...
- python&C++区别
1.类的定义 struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), ne ...
- rules验证数值大于0
[['mobile'],'number'],[['mobile'],'compare','compareValue' =>0,'operator' => '>']compare对比, ...
- Scrapy框架报错:Ignoring non-200 response
1.当爬取页面状态码是异常状态码,但response是正常的时候,正常情况Scrapy框架会判断状态码,如果不是正常状态码会停止后续操作 解决方案: 在meta"handle_httpsta ...
- 将map转成vo实体
//将map转成vo实体 AssetManagementProductsVO param= JSON.parseObject(JSON.toJSONString(map), AssetManageme ...
- baodoumi mybaitplus自增很大问题
参考: https://blog.csdn.net/u012019209/article/details/124585933 @TableId(type = IdType.AUTO) private ...
- fatal: unable to access 'https://github.com/github-eliviate/papers.git/': Failed to connect to github.com port 443 after 21107 ms: Timed out
fatal: unable to access 'https://github.com/github-eliviate/papers.git/': Failed to connect to githu ...
- ElasticSearch 实现分词全文检索 - match、match_all、multimatch查询
目录 ElasticSearch 实现分词全文检索 - 概述 ElasticSearch 实现分词全文检索 - ES.Kibana.IK安装 ElasticSearch 实现分词全文检索 - Rest ...
- 同步协程的必备工具: WaitGroup
1. 简介 本文将介绍 Go 语言中的 WaitGroup 并发原语,包括 WaitGroup 的基本使用方法.实现原理.使用注意事项以及常见的使用方式.能够更好地理解和应用 WaitGroup 来协 ...