【NLP 系列】Bert 词向量的空间分布
作者:京东零售 彭馨
1. 背景
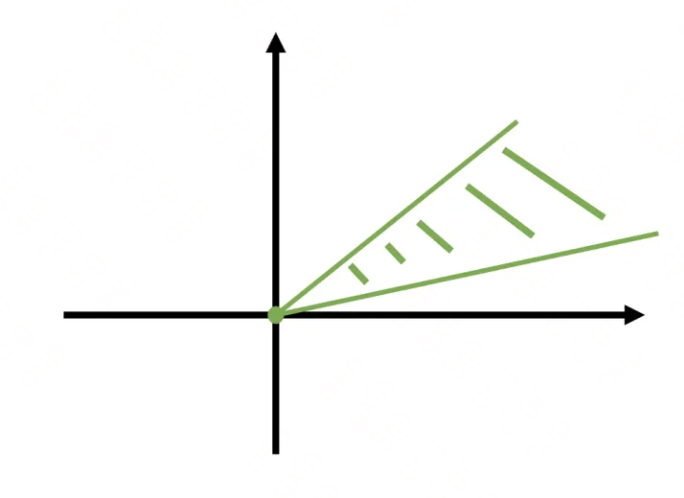
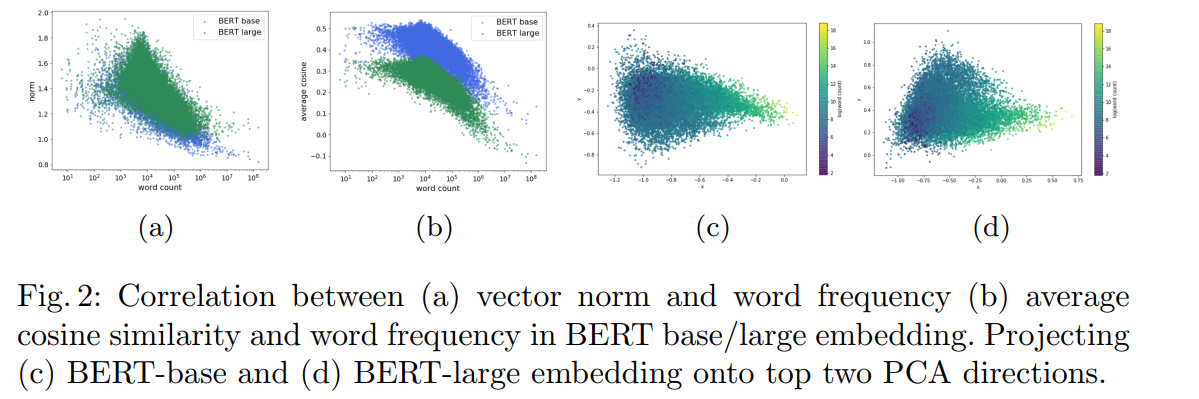
我们知道Bert 预训练模型针对分词、ner、文本分类等下游任务取得了很好的效果,但在语义相似度任务上,表现相较于 Word2Vec、Glove 等并没有明显的提升。有学者研究发现,这是因为 Bert 词向量存在各向异性(不同方向表现出的特征不一致),高频词分布在狭小的区域,靠近原点,低频词训练不充分,分布相对稀疏,远离原点,词向量整体的空间分布呈现锥形,如下图,导致计算的相似度存在问题。

2. 问题分析
为什么Bert词向量会呈现圆锥形的空间分布且高频词更靠近原点?

查了一些论文发现,除了这篇 ICLR 2019 的论文《Representation Degeneration Problem in Training Natural Language Generation Models》给出了一定的理论解释,几乎所有提及到 Bert 词向量空间分布存在问题的论文,都只是在引用该篇的基础上,直接将词向量压缩到二维平面上进行观测统计(肉眼看的说服力明显不够)
图中(b)(c)可以看出原生 Word2Vec 和分类任务的词向量经 SVD 投影,分布在原点周围,而原生 Transformer 则分布在圆锥形区域,且任意两个词向量都正相关,会降低模型性能,这种现象被称为表征退化问题。
①造成这种现象的直观解释是:在模型训练过程中,真词的embedding会被推向隐藏状态的方向,而其他词会被推向其负方向,结果是词汇表中大多数单词的嵌入将被推向与大多数隐藏状态负相关的相似方向,因此在嵌入空间的局部区域中聚集在一起。
②理论解释则是分析未出现词的嵌入,发现表征退化和隐藏状态的结构有关:当隐藏状态的凸包不包含原点时,退化出现,并且当使用层归一化进行训练时,很可能发生这种情况。并发现低频词很可能在优化过程中被训练为彼此接近,因此位于局部区域。
论文将对理论解释部分给出证明,下面从我的理解,来解读一下,最后再简单说一下另外两篇对 Bert 词向量观测统计的论文。
3. 理论解释
在介绍之前,先熟悉几个关于凸优化问题的概念(不知道其实也问题不大):
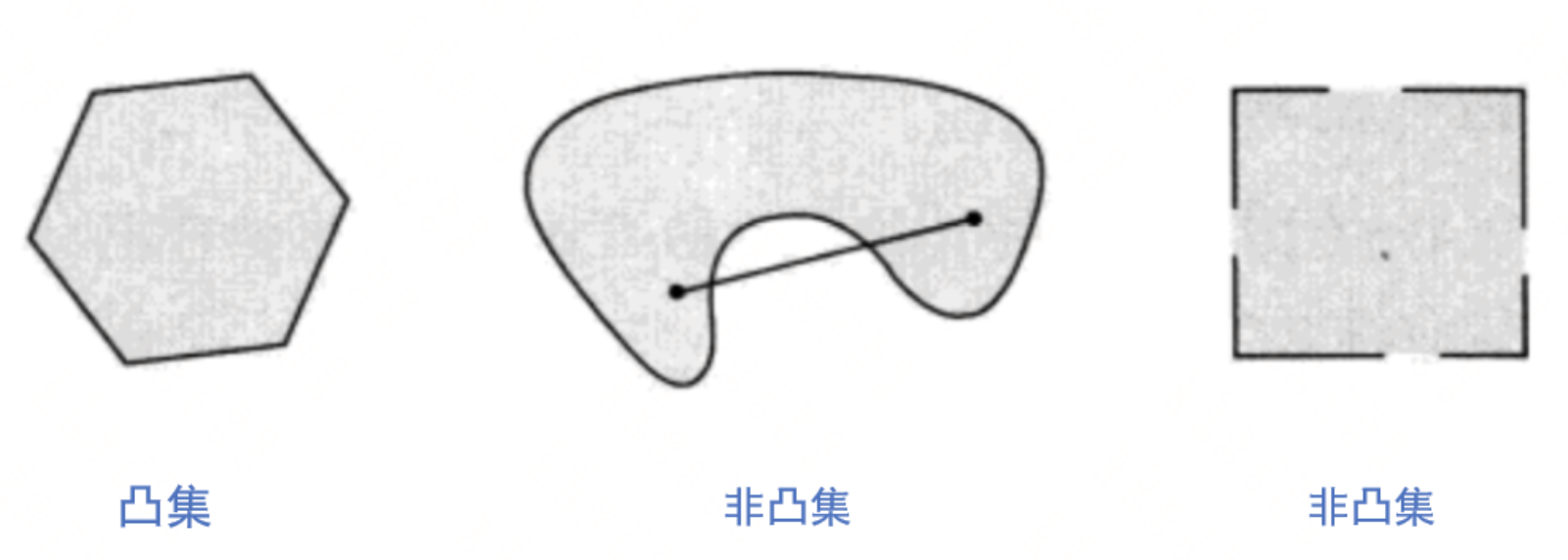
- 凸集:

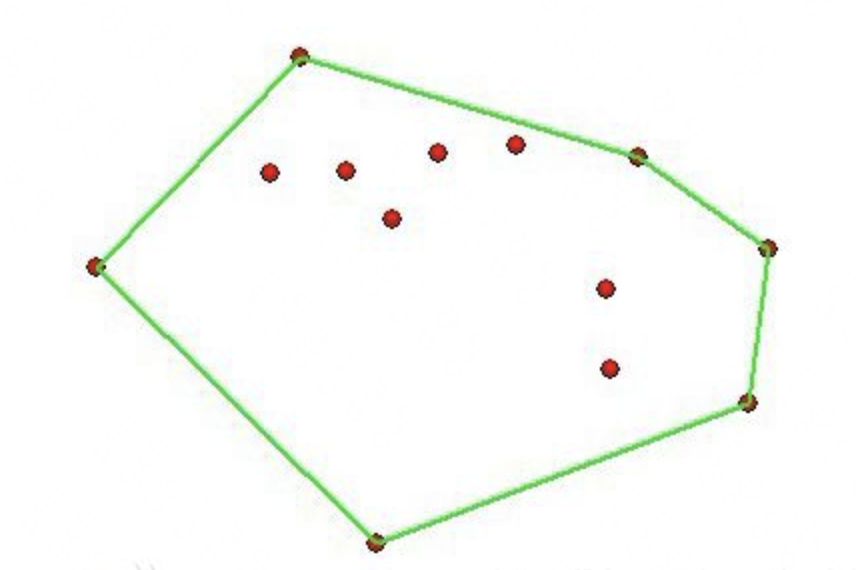
- 凸包:
点集Q的凸包是指一个最小凸多边形,满足Q中的点或者在多边形边上或者在其内。(最小的凸集)
- 锥:

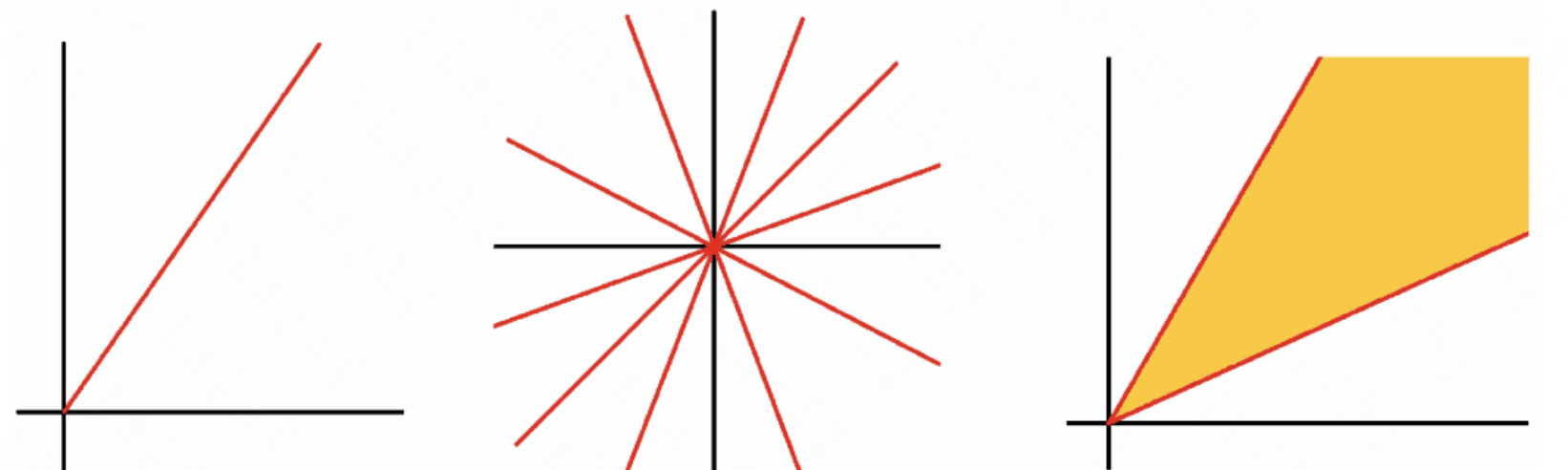
- 凸锥:
如果一个集合既是锥,又是凸集,则该集合是凸锥。
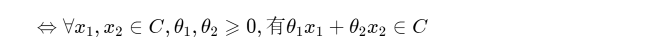
1)未出现词
因为不容易直接分析高、低频词,作者另辟蹊径,选择和低频词比较相似的未出现词来分析目标函数。


因为其他参数固定,则上式等价于:
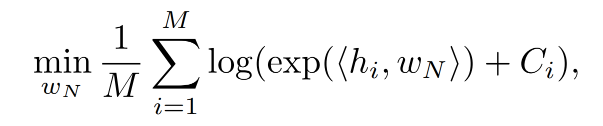

文中说定理1 中的 A 显而易见,那就只能大家自行理解这个凸集了。B 则是对上面最小化公式的求解,下面给出证明
证明:

证明:

以上还是很好理解的,定理1说明未出现词的向量会被优化无穷远,远离原点(模越来越大)。定理2则是说明词向量的分布不包含原点,而是在原点的一侧
2)低频词
低频词的分析则是在未出现词的基础上,因为分析低频词的embedding对损失函数的影响,将损失函数分为了两部分:
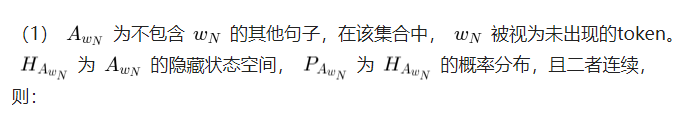
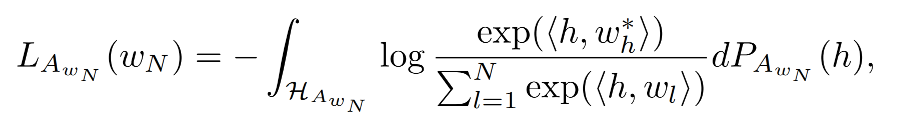

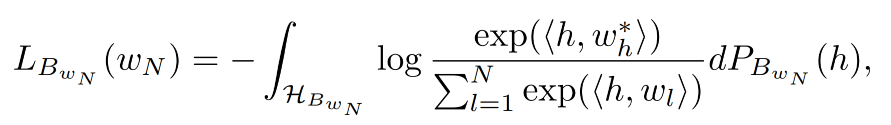
总损失函数为:


原来定理3 才是理解路上的最大绊脚石!

下面简述一下对词向量进行观测统计的论文
论文1《On the Sentence Embeddings from Pre-trained Language Models》
其实这篇论文就是字节的 Bert-flow(不熟悉 Bert-flow 可见《对比学习——文本匹配》)。论文计算了词嵌入与原点的平均l2距离,并根据词频做了排序(词频越高排名越靠前,第0位词频最高),得出高频词靠近原点、低频词远离原点的结论,如下表上半部分:
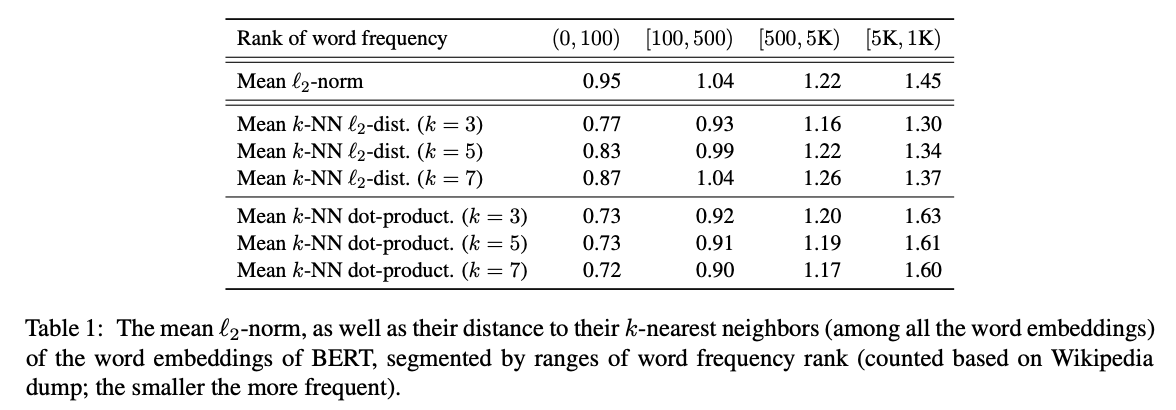
表的下半部分则为词嵌入和它的k个近邻之间的平均l2距离和点积,可以看出低频词相较于高频词,和它们的k近邻距离更远,说明低频词相对高频词分布更稀疏。
论文2《Learning to Remove: Towards Isotropic Pre-trained BERT Embedding》
该论文则是通过随机计算两个词的相似度,发现都远大于0(说明词向量的方向基本都一致,不一致不会都远大于0),以此说明词向量不是均匀分布在向量空间中,而是分布在一个狭窄的圆锥体中。
4. 总结
都有理论解释了,结论自然就是 Bert 词向量确实存在表征退化问题,词向量存在各向异性,高频词距离原点更近,低频词训练不充分,远离原点,整体分布呈现圆锥形,导致其不适用于语义相似度任务。不过不知道该理论解释有没有说服你,有不同见解或疑问,欢迎前来交流。
针对此类问题,可以采用一下方法对其进行纠正,如论文[1]中加入cos正则,论文[2]中将锥形分布转化为高斯分布。因为词向量有问题,句向量自然跑不了,所以《对比学习——文本匹配》中的算法其实也都是为了解决这个问题。
附:(定理3证明)

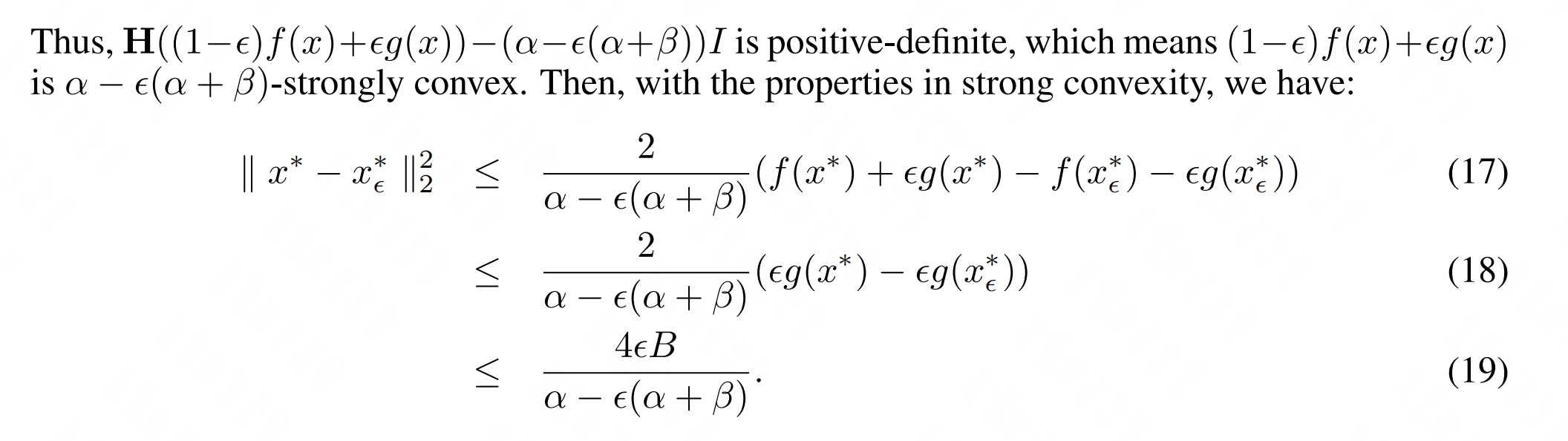
【NLP 系列】Bert 词向量的空间分布的更多相关文章
- 斯坦福NLP课程 | 第1讲 - NLP介绍与词向量初步
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- Deep Learning In NLP 神经网络与词向量
0. 词向量是什么 自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化. NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representati ...
- NLP直播-1 词向量与ELMo模型
翻车2次,试水2次,今天在B站终于成功直播了. 人气11万. 主要讲了语言模型.词向量的训练.ELMo模型(深度.双向的LSTM模型) 预训练与词向量 词向量的常见训练方法 深度学习与层次表示 LST ...
- 斯坦福NLP课程 | 第2讲 - 词向量进阶
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- NLP教程(2) | GloVe及词向量的训练与评估
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
有很多改进版的word2vec,但是目前还是word2vec最流行,但是Glove也有很多在提及,笔者在自己实验的时候,发现Glove也还是有很多优点以及可以深入研究对比的地方的,所以对其进行了一定的 ...
- NLP之词向量
1.对词用独热编码进行表示的缺点 向量的维度会随着句子中词的类型的增大而增大,最后可能会造成维度灾难2.任意两个词之间都是孤立的,仅仅将词符号化,不包含任何语义信息,根本无法表示出在语义层面上词与词之 ...
- NLP︱高级词向量表达(三)——WordRank(简述)
如果说FastText的词向量在表达句子时候很在行的话,GloVe在多义词方面表现出色,那么wordRank在相似词寻找方面表现地不错. 其是通过Robust Ranking来进行词向量定义. 相关p ...
- NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,不过这个项目其实是有两部分组成的,一部分是这篇文章介绍的 fastText 文本分类(paper: ...
随机推荐
- Java-ArrayList常用API
返回值 方法 用途 boolean add(E e) 将指定的元素追加到此列表的末尾. void add(int index, E element) 在此列表中的指定位置插入指定的元素. boolea ...
- git 代码已经commit ,发现提错了分支
步骤: git reset HEAD^ //把上次提交恢复为未提交状态 git status //查看当前状态 git stash //将修改add到暂存区,暂存代码 git checkout 分支 ...
- fastdfs 上传成功后返回了错误URL,Request URL: http://localhost:8081/121.122.25.133/group1/M00/00/00/wKgZhV63.jpg
错误的URL. 原因: 图片服务器地址格式错误,fastdfs返回了错误的URL IMAGE_SERVER_URL = http:121.12.25.13/ 正确: IMAGE_SERVER_URL ...
- 1903021126 申文骏 Java 第三周作业 编写代码及运行
项目 内容 课程班级博客链接 19级信计班(本) 作业要求链接 第三周作业要求 博客名称 1903021126 申文骏 Java 第三周作业 编写代码及运行 要求 每道题要有题目,代码(使用插入代码, ...
- PostgreSQL 存储过程 通过设定条件,返回指定的数据表记录
PL/pgSQL是 PostgreSQL 数据库系统的一个可装载的过程语言. PL/pgSQL的设计目标是创建一种可装载的过程语言,可以可用于创建函数和触发器过程, 在SQL语言中添加控制结构功能, ...
- c++学习2 基础关键词
三 volatile强制访问内存 在一个变量的频繁使用中,系统为了提高效率,会自动将内存里面的数据放入CPU里的寄存器里.但在某些特殊场景下,放入寄存器这个操作反倒会导致CPU无法及时获取最新的一手数 ...
- Compose Modifier Clip 圆角
Row( modifier = Modifier .fillMaxWidth() .padding(20.dp) // 圆角 .clip(RoundedCornerShape(15.dp)) .cli ...
- Deformable DETR (ICLR2021)
Pre-Trained Image Processing Transformer paper:https://arxiv.org/abs/2010.04159 code:https://github. ...
- Vue Element使用第三方图标(iconfont阿里矢量图标库)
在 www.iconfont.cn 中搜索图标并加入购物车然后添加至项目,编辑项目名称 然后将项目下载至本地解压后将如下文件复制移到到 src/assets/icon中, 并把iconfont.c ...
- base64与中文字符串互转
实现代码如下 // 字符串转base64 getEncode64(str){ return btoa(encodeURIComponent(str).replace(/%([0-9A-F]{2})/g ...