图文详解MapReduce工作机制
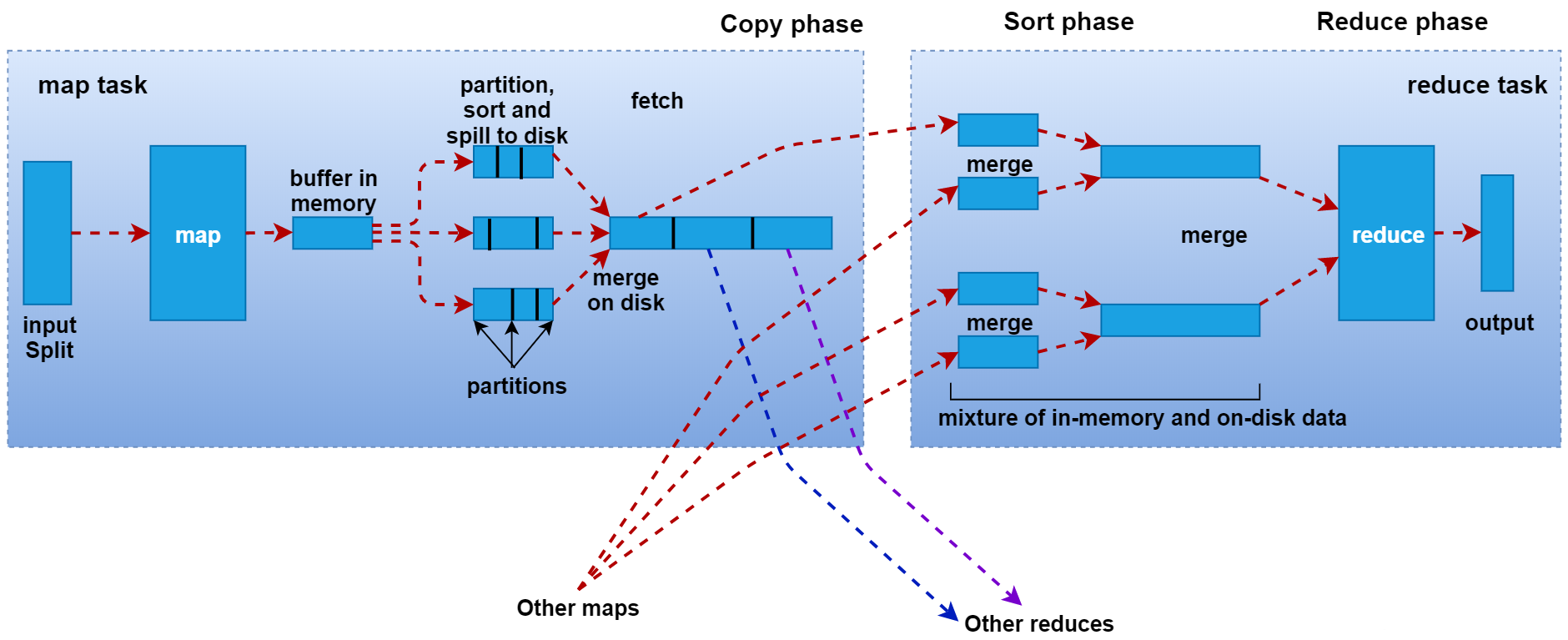
job提交阶段
1、准备好待处理文本。
2、客户端submit()前,获取待处理数据的信息,然后根据参数配置,形成一个任务分配的规划。
3、客户端向Yarn请求创建MrAppMaster并提交切片等相关信息:job.split、wc.jar、job.xml。Yarn调用ResourceManager来创建MrAppMaster,而MrAppMaster则会根据切片的个数来创建MapTask。
其中切片规划: InputFormat(默认为TextInputFormat)通过getSplits 方法对输入目录中的文件进行逻辑切片,并序列化成job.split文件。默认情况下,HDFS上的一个block对应一个InputSplit,一个InputSplit对应开启一个MapTask。
MapTask阶段
1、Read阶段:由RecordReader对象(默认是LineRecordReader)进行读取,以换行符 (\n) 作为分隔符,每读取一行数据,就返回一对<Key,Value>供Mapper使用。Key表示该行的起始字节偏移量,Reduce表示这一行的内容。
2、Map阶段: 将解析出的<Key,Value>交给用户重写的map()函数处理,每一行数据会调用一次map()函数。
3、Collect阶段:map()函数中将数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value进行分区处理(调用Partitioner,默认为HashPartitioner),并写入一个环形内存缓冲区中。
4、Spill阶段(溢写):当环形缓冲区的数据达到溢写比例时(80%),会将数据溢写到本地磁盘上,生成一个临时文件。溢写之前,还会对数据进行排序,必要时进行合并、压缩操作。
5、Merge阶段:当Mapper输出全部文件后,产生多个临时文件。MapTask将所有临时文件以分区为单位,进行归并排序,最终得到一个大文件,等待Reduce端的拉取。
ReduceTask阶段
1、Copy阶段:每个ReduceTask从各个MapTask上拉取对应分区的数据。拉取数据后先存储到内存中,内存不够时,再刷写到磁盘。
2、Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
3、Sort阶段:用户编写的reduce()函数的输入数据是按Key进行聚集的一组数据。为了将相同Key的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经对自己的处理结果进行了分区内局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
4、Reduce阶段:相同Key的一组键值对调用一次Reduce方法,进行聚合处理。之后通过context.write,默认以TextOutputFormat格式经RecordWriter写入到HDFS文件中。
溢写阶段详情
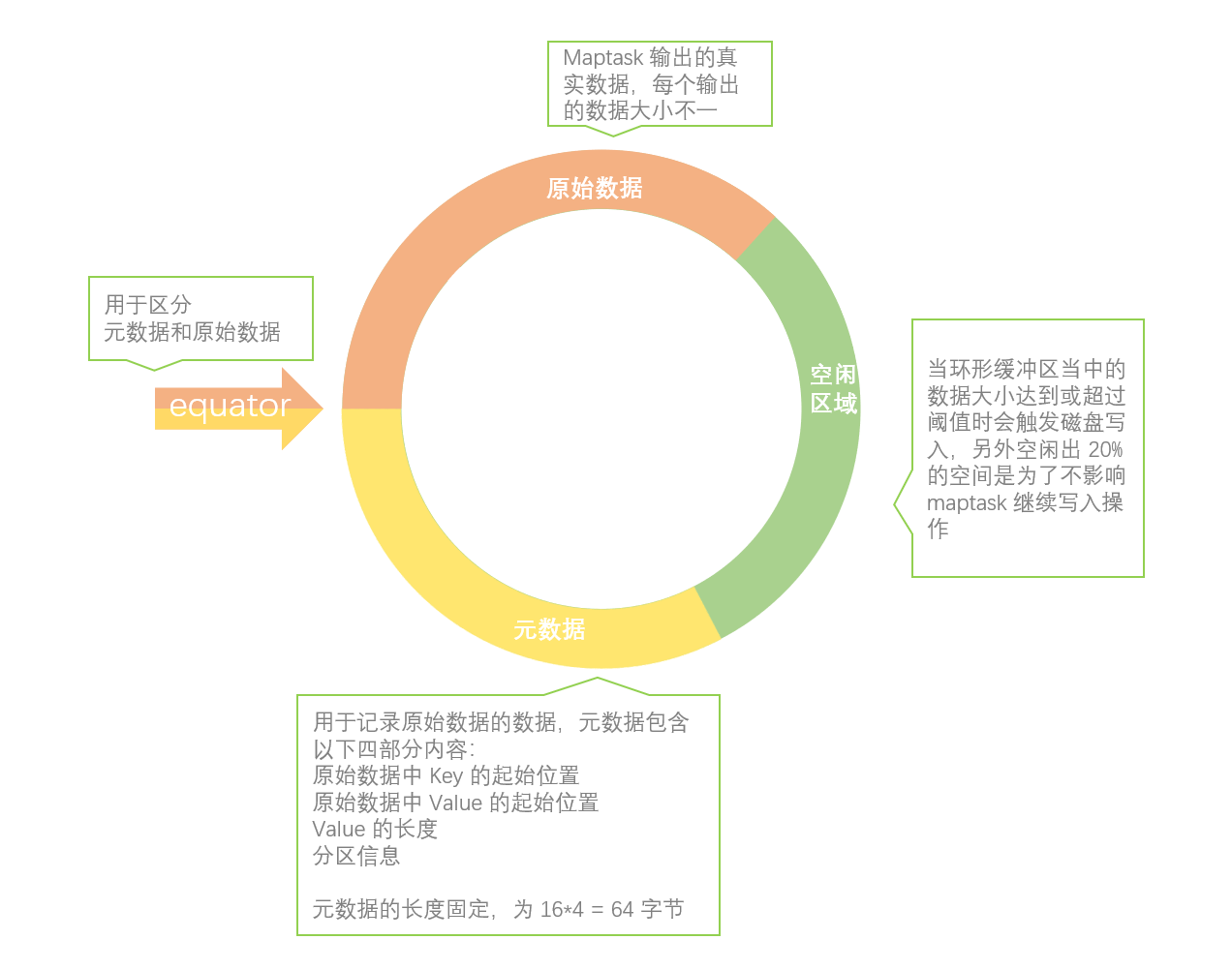
1、每个 MapTask都有一个环形内存缓冲区(默认大小为100M)用于批量收集Mapper结果,以减少磁盘IO的开销。当缓冲区的数据达到溢写比例时(默认为80%),溢写线程启动。此时MapTask仍继续将结果写入缓冲区,如果缓冲区被写满,MapTask就会阻塞直到溢出线程结束。如果数据量很小,达不到80M溢写的话,就等所有文件都读完后完成一次溢写。
2、在溢写之前,会采取快速排序算法对缓冲区内的数据按照Key进行字典顺序排序:先把数据划分到相应的分区(Partition),然后按照key进行排序。经过排序后,相同分区的数据聚集在一起,同一分区内的数据按照key有序。
3、如果设置了Combiner 函数,则在排序后,溢写前对每个分区中的数据进行局部聚合操作,以减轻 Shuffle 过程中网络传输压力。
4、开始溢写:按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。每次内存缓冲区达到溢出阈值,就会新建一个溢出文件(spill file),当Mapper输出全部文件时,会产生多个溢写文件,最终会被合并成一个已分区且已排序的输出文件。
图文详解MapReduce工作机制的更多相关文章
- MapReduce工作原理图文详解 (炼数成金)
MapReduce工作原理图文详解 1.Map-Reduce 工作机制剖析图: 1.首先,第一步,我们先编写好我们的map-reduce程序,然后在一个client 节点里面进行提交.(一般来说可以在 ...
- Android 异步通信:图文详解Handler机制工作原理
前言 在Android开发的多线程应用场景中,Handler机制十分常用 今天,我将图文详解 Handler机制 的工作原理,希望你们会喜欢 目录 1. 定义 一套 Android 消息传递机制 2. ...
- MapReduce 1工作原理图文详解
MapReduce工作原理图文详解 一 MapReduce程序执行流程 程序执行流程图如下: 流程分析:1.在客户端启动一个作业.2.向JobTracker请求一个Job ID.3.将运行作业所需要的 ...
- Hadoop MapReduce 一文详解MapReduce及工作机制
@ 目录 前言-MR概述 1.Hadoop MapReduce设计思想及优缺点 设计思想 优点: 缺点: 2. Hadoop MapReduce核心思想 3.MapReduce工作机制 剖析MapRe ...
- 图文详解 Android Binder跨进程通信机制 原理
图文详解 Android Binder跨进程通信机制 原理 目录 目录 1. Binder到底是什么? 中文即 粘合剂,意思为粘合了两个不同的进程 网上有很多对Binder的定义,但都说不清楚:Bin ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- Linux NFS服务器的安装与配置方法(图文详解)
这篇文章主要介绍了Linux NFS服务器的安装与配置方法(图文详解),需要的朋友可以参考下(http://xb.xcjl0834.com) 一.NFS服务简介 NFS 是Network File S ...
- APNS推送服务证书制作 图文详解教程(新)
iOS消息推送的工作机制可以简单的用下图来概括: Provider是指某个iPhone软件的Push服务器,APNS是Apple Push Notification Service的缩写,是苹果的服务 ...
随机推荐
- Android地图化实现
今天在Android上实现了地图化,可以通过记录用户位置和体温是否异常来实现地图区域变色,并显示正常人数,与体温是否异常,且可以地图下钻. 效果展示:
- Servlet 3.0以上版本使用@WebServlet注解配置映射
以前的Servlet都是在web.xml中进行配置,导致web.xml中各个Servlet的映射非常杂乱无章,后期也很难维护 本篇文章将详细阐述如何使用Servlet 3.0的新特性使用@WebSer ...
- js 生成 pdf 文件
话不多说好吧, 直接上demo图: 直接上代码好吧:(要引入的两个js 链接我放最后) <!DOCTYPE html> <html> <head> <met ...
- openlayers离线瓦片地图开发
近期业务繁忙...待更新
- uni-app中 未收藏和已收藏功能展示
效果图如下: 未收藏: 已收藏: 代码实现: 1 <view class="jichu"> 2 <view class="name">x ...
- SpringMVC 解析(四)编程式路由
多数情况下,我们在使用Spring的Controller时,会使用@RequestMapping的形式把请求按照URL路由到指定方法上.Spring还提供了一种编程的方式去实现请求和路由方法之间的路由 ...
- OllyDbg---call和ret指令
call和ret call指令 cal指令是转移到指定的子程序处,后面紧跟的操作数就是给定的地址. 例如,call 401362表示转移到地址401362处,调用401362处的子程序,当子程序调用完 ...
- LC-35
题目地址:https://leetcode-cn.com/problems/search-insert-position/ 一样的二分条件,多一个限制插入. 所以思考插入什么位置? 在 [left, ...
- /application/zabbix/sbin/zabbix_server: error while loading shared libraries: libmysqlclient.so.20: cannot open shared object file: No such file or directory
在启动/usr/local/zabbix/sbin/zabbix_server 时报错如下 此时需要配置一个软连接指向该位置. ln -s /usr/local/mysql/lib/libmysqlc ...
- 搭建MySQL集群-注意版本
系统环境采样(来自其他机器,直接copy过来的,在安装的机器上,按照步骤查看即可,当然这些还不够实际,后续补充) 检查系统内是否有其他mysql rpm -qa | grep mysql 是否存在my ...