图文详解MapReduce工作机制
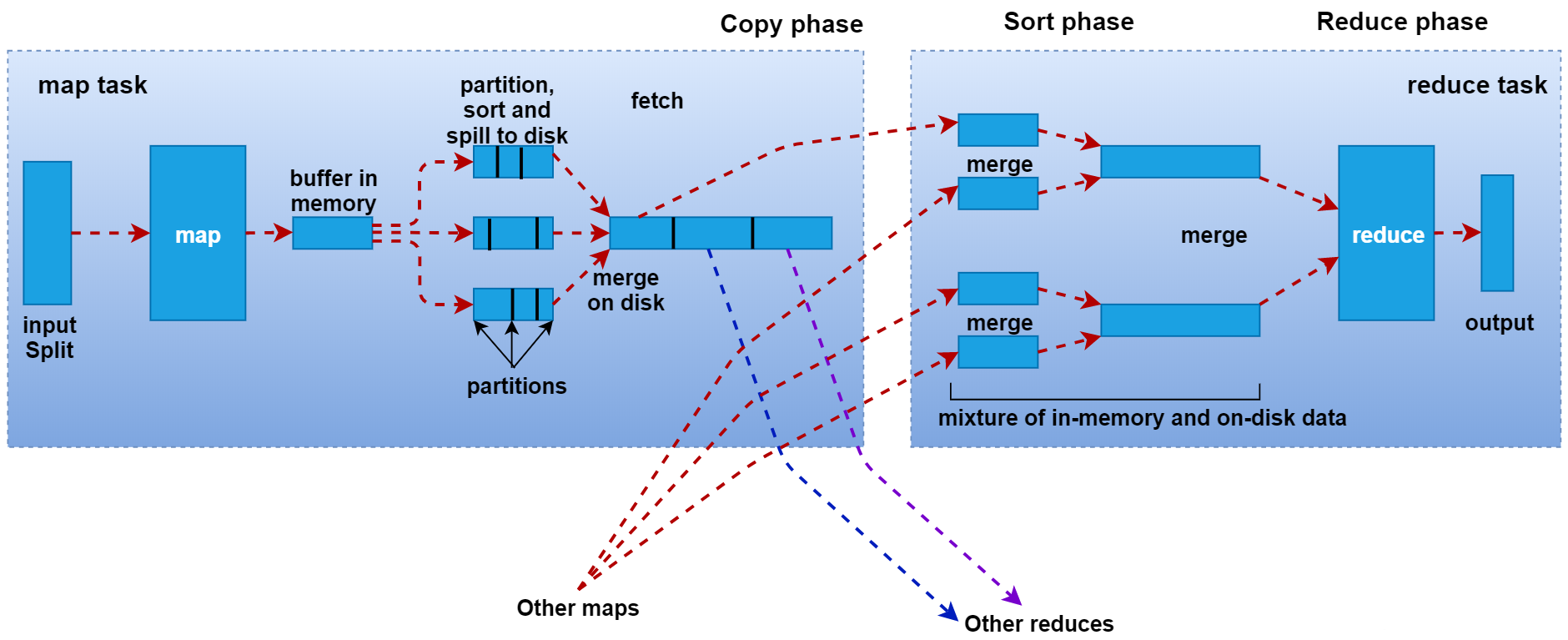
job提交阶段
1、准备好待处理文本。
2、客户端submit()前,获取待处理数据的信息,然后根据参数配置,形成一个任务分配的规划。
3、客户端向Yarn请求创建MrAppMaster并提交切片等相关信息:job.split、wc.jar、job.xml。Yarn调用ResourceManager来创建MrAppMaster,而MrAppMaster则会根据切片的个数来创建MapTask。
其中切片规划: InputFormat(默认为TextInputFormat)通过getSplits 方法对输入目录中的文件进行逻辑切片,并序列化成job.split文件。默认情况下,HDFS上的一个block对应一个InputSplit,一个InputSplit对应开启一个MapTask。
MapTask阶段
1、Read阶段:由RecordReader对象(默认是LineRecordReader)进行读取,以换行符 (\n) 作为分隔符,每读取一行数据,就返回一对<Key,Value>供Mapper使用。Key表示该行的起始字节偏移量,Reduce表示这一行的内容。
2、Map阶段: 将解析出的<Key,Value>交给用户重写的map()函数处理,每一行数据会调用一次map()函数。
3、Collect阶段:map()函数中将数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value进行分区处理(调用Partitioner,默认为HashPartitioner),并写入一个环形内存缓冲区中。
4、Spill阶段(溢写):当环形缓冲区的数据达到溢写比例时(80%),会将数据溢写到本地磁盘上,生成一个临时文件。溢写之前,还会对数据进行排序,必要时进行合并、压缩操作。
5、Merge阶段:当Mapper输出全部文件后,产生多个临时文件。MapTask将所有临时文件以分区为单位,进行归并排序,最终得到一个大文件,等待Reduce端的拉取。
ReduceTask阶段
1、Copy阶段:每个ReduceTask从各个MapTask上拉取对应分区的数据。拉取数据后先存储到内存中,内存不够时,再刷写到磁盘。
2、Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
3、Sort阶段:用户编写的reduce()函数的输入数据是按Key进行聚集的一组数据。为了将相同Key的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经对自己的处理结果进行了分区内局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
4、Reduce阶段:相同Key的一组键值对调用一次Reduce方法,进行聚合处理。之后通过context.write,默认以TextOutputFormat格式经RecordWriter写入到HDFS文件中。
溢写阶段详情
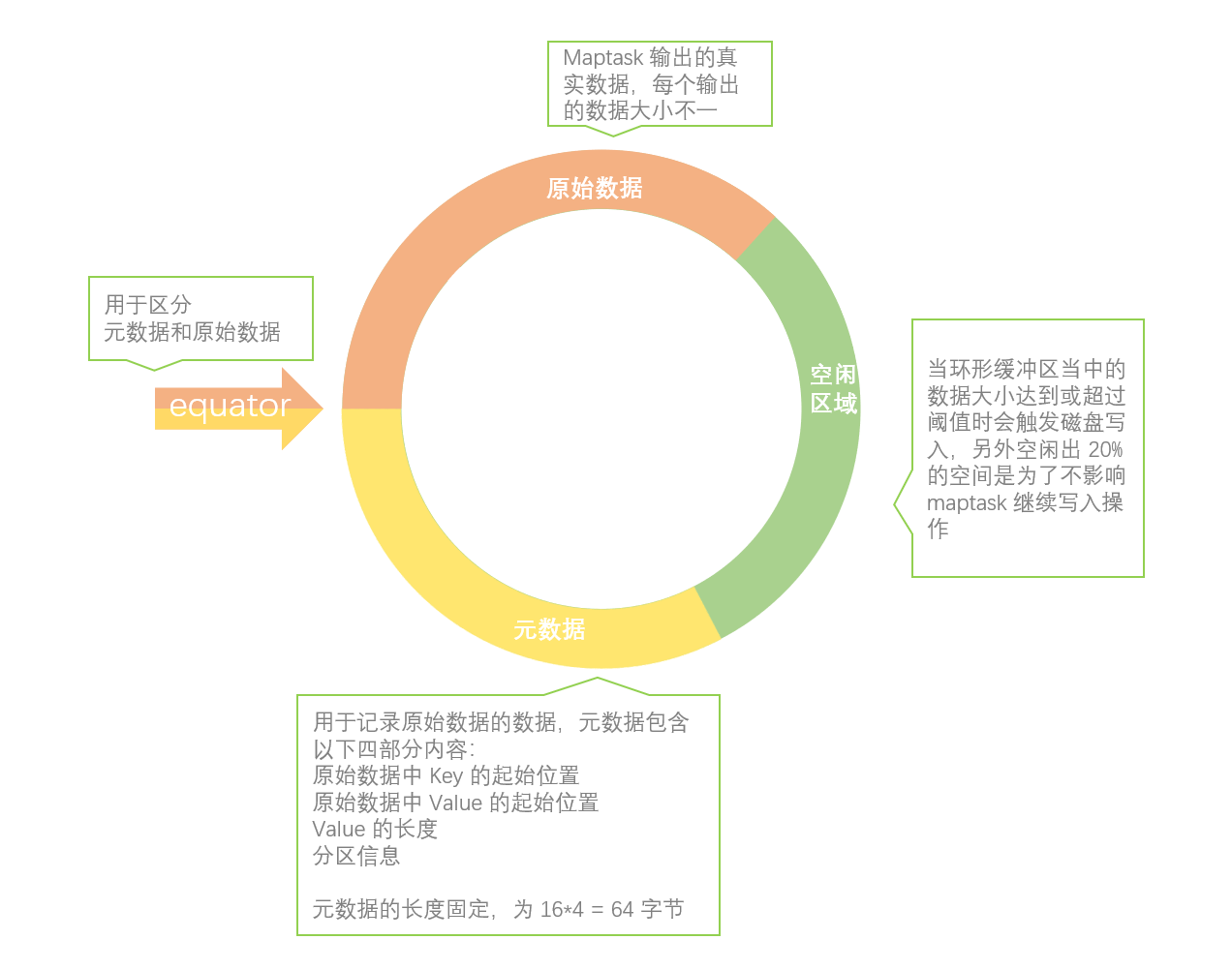
1、每个 MapTask都有一个环形内存缓冲区(默认大小为100M)用于批量收集Mapper结果,以减少磁盘IO的开销。当缓冲区的数据达到溢写比例时(默认为80%),溢写线程启动。此时MapTask仍继续将结果写入缓冲区,如果缓冲区被写满,MapTask就会阻塞直到溢出线程结束。如果数据量很小,达不到80M溢写的话,就等所有文件都读完后完成一次溢写。
2、在溢写之前,会采取快速排序算法对缓冲区内的数据按照Key进行字典顺序排序:先把数据划分到相应的分区(Partition),然后按照key进行排序。经过排序后,相同分区的数据聚集在一起,同一分区内的数据按照key有序。
3、如果设置了Combiner 函数,则在排序后,溢写前对每个分区中的数据进行局部聚合操作,以减轻 Shuffle 过程中网络传输压力。
4、开始溢写:按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。每次内存缓冲区达到溢出阈值,就会新建一个溢出文件(spill file),当Mapper输出全部文件时,会产生多个溢写文件,最终会被合并成一个已分区且已排序的输出文件。
图文详解MapReduce工作机制的更多相关文章
- MapReduce工作原理图文详解 (炼数成金)
MapReduce工作原理图文详解 1.Map-Reduce 工作机制剖析图: 1.首先,第一步,我们先编写好我们的map-reduce程序,然后在一个client 节点里面进行提交.(一般来说可以在 ...
- Android 异步通信:图文详解Handler机制工作原理
前言 在Android开发的多线程应用场景中,Handler机制十分常用 今天,我将图文详解 Handler机制 的工作原理,希望你们会喜欢 目录 1. 定义 一套 Android 消息传递机制 2. ...
- MapReduce 1工作原理图文详解
MapReduce工作原理图文详解 一 MapReduce程序执行流程 程序执行流程图如下: 流程分析:1.在客户端启动一个作业.2.向JobTracker请求一个Job ID.3.将运行作业所需要的 ...
- Hadoop MapReduce 一文详解MapReduce及工作机制
@ 目录 前言-MR概述 1.Hadoop MapReduce设计思想及优缺点 设计思想 优点: 缺点: 2. Hadoop MapReduce核心思想 3.MapReduce工作机制 剖析MapRe ...
- 图文详解 Android Binder跨进程通信机制 原理
图文详解 Android Binder跨进程通信机制 原理 目录 目录 1. Binder到底是什么? 中文即 粘合剂,意思为粘合了两个不同的进程 网上有很多对Binder的定义,但都说不清楚:Bin ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- Linux NFS服务器的安装与配置方法(图文详解)
这篇文章主要介绍了Linux NFS服务器的安装与配置方法(图文详解),需要的朋友可以参考下(http://xb.xcjl0834.com) 一.NFS服务简介 NFS 是Network File S ...
- APNS推送服务证书制作 图文详解教程(新)
iOS消息推送的工作机制可以简单的用下图来概括: Provider是指某个iPhone软件的Push服务器,APNS是Apple Push Notification Service的缩写,是苹果的服务 ...
随机推荐
- Java/C++实现备忘录模式--撤销操作
改进课堂上的"用户信息操作撤销"实例,使得系统可以实现多次撤销(可以使用HashMap.ArrayList等集合数据结构实现). 类图: Java代码: import java.u ...
- JavaScript 中 append()、prepend()、after()、before() 的区别
内容 append().prepend().after().before() 的区别 jQuery 操作 DOM 之添加节点 方法名 作用 $(selector).append() 指定元素内部添加, ...
- 控制反转 IOC 理论推导
控制反转 IOC 理论推导 按照我们传统的开发,我们会先去 dao 层创建一个接口,在接口中定义方法. public interface UserDao { void getUser(); } 然后再 ...
- 【转】shim.ChaincodeStubInterface用法
作为记录 shim.ChaincodeStubInterface用法
- Metalama简介3.自定义.NET项目中的代码分析
本系列其它文章 使用基于Roslyn的编译时AOP框架来解决.NET项目的代码复用问题 Metalama简介1. 不止是一个.NET跨平台的编译时AOP框架 Metalama简介2.利用Aspect在 ...
- thinkphp6事件监听event-listene
事件系统可以看成是行为系统的升级版,相比行为系统强大的地方在于事件本身可以是一个类,并且可以更好的支持事件订阅者. 事件相比较中间件的优势是事件比中间件更加精准定位(或者说粒度更细),并且更适合一些业 ...
- Ubuntu 下 Apache2 和 PHP 服务器环境配置
Ubuntu 下 Apache2 和 PHP 服务器环境配置 1.简介 本文主要是 Ubuntu 下 Apache2 和 PHP 服务器环境配置方法,同样适用于 Debian 系统:Ubuntu 20 ...
- MySQL基础合集
我的小站 1.MySQL的优势 运行速度快 使用成本低 可移植性强 适用用户广 2.MySQL的运行机制 一个SQL语句,如select * from tablename ,从支持接口进来后,进入连 ...
- Unity实现A*寻路算法学习2.0
二叉树存储路径节点 1.0中虽然实现了寻路的算法,但是使用List<>来保存节点性能并不够强 寻路算法学习1.0在这里:https://www.cnblogs.com/AlphaIcaru ...
- Python技法:用re模块实现简易tokenizer
一个简单的tokenizer 分词(tokenization)任务是Python字符串处理中最为常见任务了.我们这里讲解用正则表达式构建简单的表达式分词器(tokenizer),它能够将表达式字符串从 ...