微服务 Zipkin 链路追踪原理(图文详解)

一个看起来很简单的应用,可能需要数十或数百个服务来支撑,一个请求就要多次服务调用。
当请求变慢、或者不能使用时,我们是不知道是哪个后台服务引起的。
这时,我们使用 Zipkin 就能解决这个问题。
由于业务访问量的增大,业务复杂度增加,以及微服务架构和容器技术的兴起,要对系统进行各种拆分。
微服务系统拆分后,我们可以使用 Zipkin 链路,来快速定位追踪有故障的服务点。
今天重点讲解 Zipkin 链路追踪的原理与使用 @mikechen
目录
Zipkin 基本概述
Zipkin 是一款开源的分布式实时数据追踪系统(Distributed Tracking System),能够收集服务间调用的时序数据,提供调用链路的追踪。
Zipkin 其主要功能是聚集来自各个异构系统的实时监控数据,在微服务架构下,十分方便地用于服务响应延迟等问题的定位。
Zipkin 每一个调用链路通过一个 trace id 来串联起来,只要你有一个 trace id ,就能够直接定位到这次调用链路,并且可以根据服务名、标签、响应时间等进行查询,过滤那些耗时比较长的链路节点。
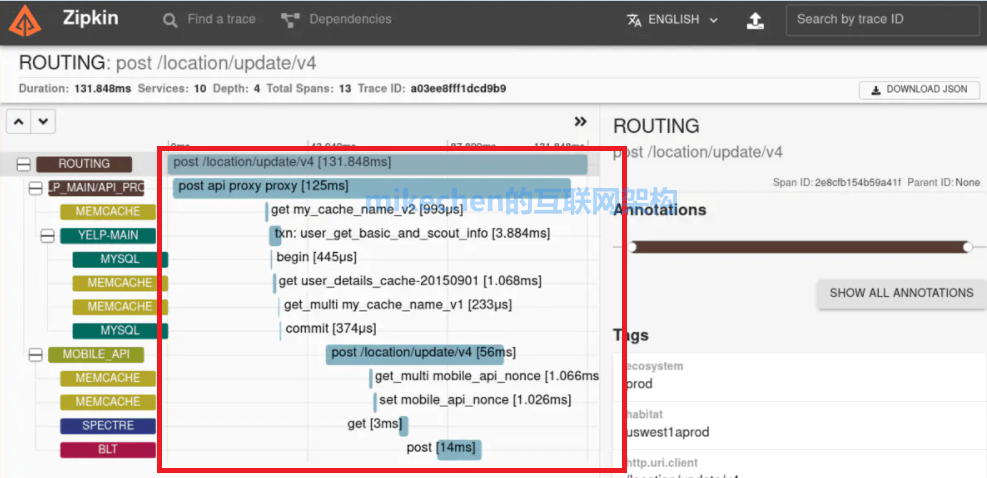
为什么用 Zipkin ?
大型互联网公司为什么需要分布式跟踪系统?
随着业务访问量越来越大。例如:比较典型的是淘宝,淘宝从早期的单体开始往分布式微服务演变,系统也随之进行各种拆分,看似简单的一个应用,后台可能有几十个甚至几百个服务在支撑。
一个客户端的请求,例如:一次下订单请求,可能需要多次的服务调用(商品、用户、店铺等系统调用过程),最后才能完成。
当请求变慢、或者不能正常使用时,我们不知道是哪个后台服务引起的,这时,我们就要想办法快速定位服务故障点。
Zipkin 分布式跟踪系统就能非常好地解决该问题,主要解决以下3点问题:
1. 动态展示服务的链路;
2. 分析服务链路的瓶颈并对其进行调优;
3. 快速进行服务链路的故障发现。
这就是 Zipkin 服务跟踪系统存在的目的和意义。
当然了,除了 Zipkin 分布式跟踪系统以外,我们还可以使用其他比较成熟的实现,例如:
- Naver 的 Pinpoint
- Apache 的 HTrace
- 阿里的鹰眼 Tracing
- 京东的 Hydra
- 新浪的 Watchman
- 美团点评的 CAT
- skywalking
- ......
知道了 Zipkin 的使用原因、使用场景和作用,接下来,我们来了解 Zipkin 的原理。
Zipkin 的原理
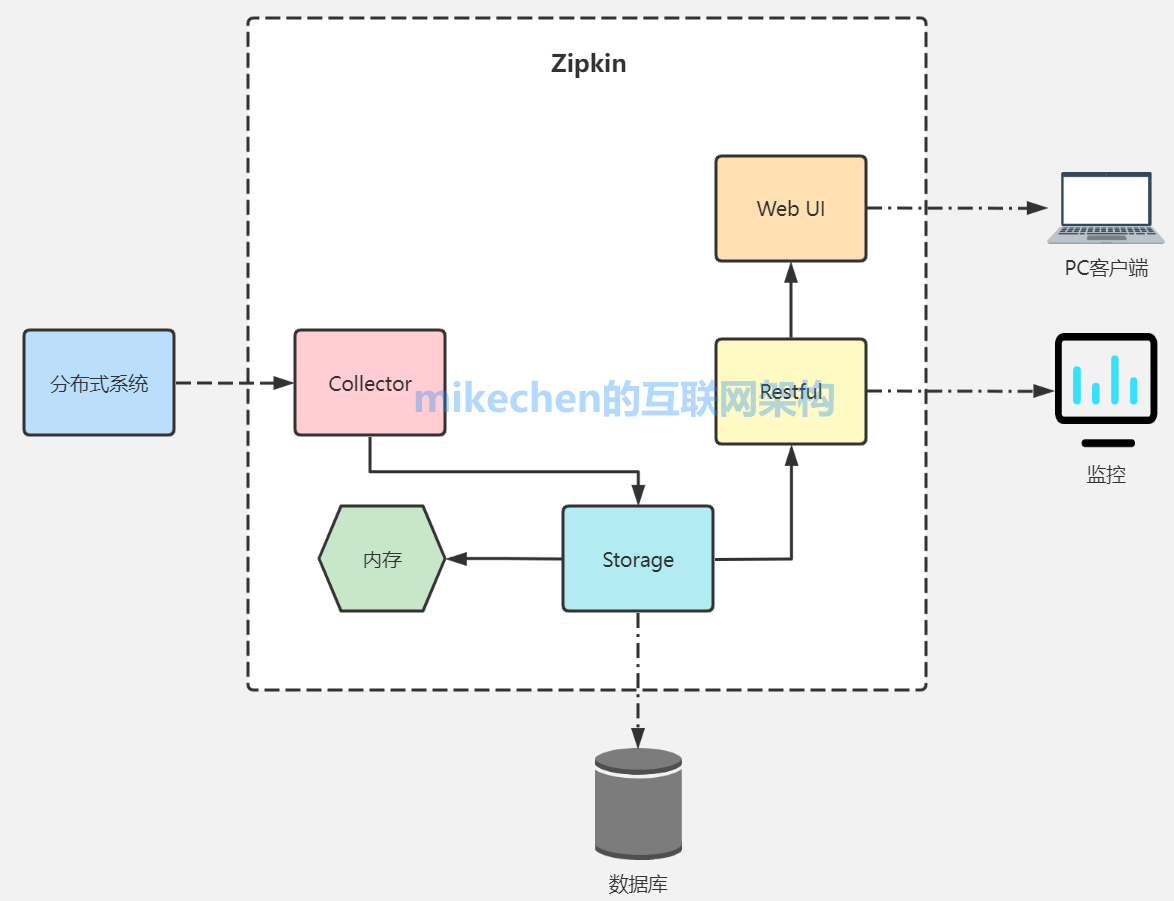
1. ZipKin 架构
ZipKin 可以分为两部分:
- ZipKin Server :用来作为数据的采集存储、数据分析与展示;
- ZipKin Client :基于不同的语言及框架封装的一些列客户端工具,这些工具完成了追踪数据的生成与上报功能。
整体架构如下:
2. Zipkin 核心组件
Zipkin (服务端)包含四个组件,分别是 collector、storage、search、web UI。
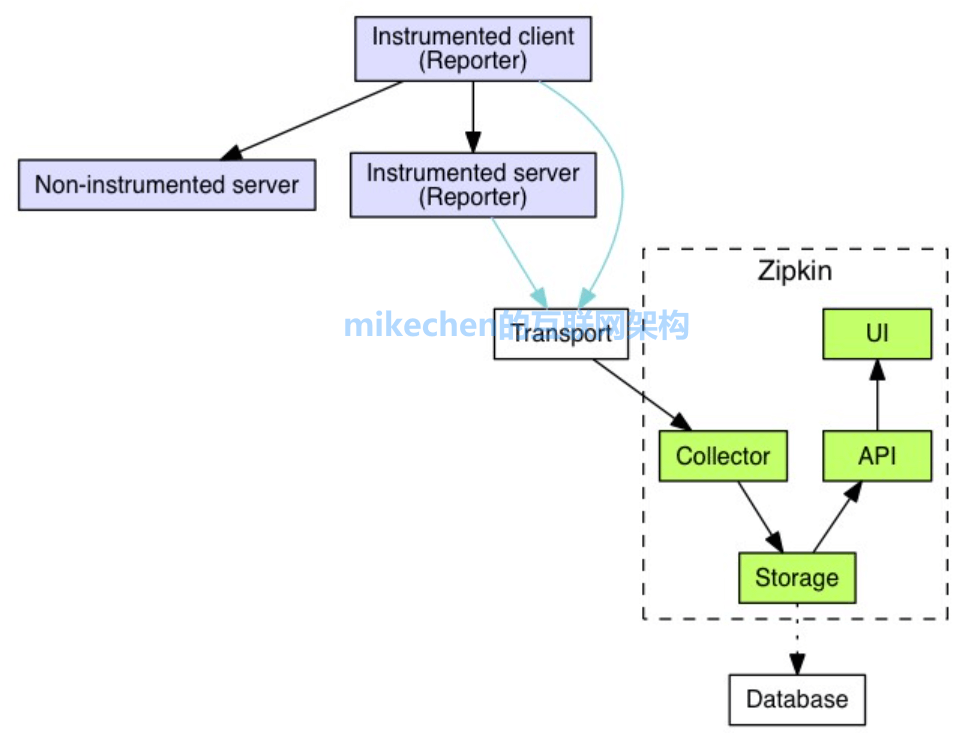
1) collector 信息收集器
collector 接受或者收集各个应用传输的数据。
2) storage 存储组件
zipkin 默认直接将数据存在内存中,此外支持使用 Cassandra、ElasticSearch 和 Mysql 。
3) search 查询进程
它提供了简单的 JSON API 来供外部调用查询。
4) web UI 服务端展示平台
主要是提供简单的 web 界面,用图表将链路信息清晰地展示给开发人员。
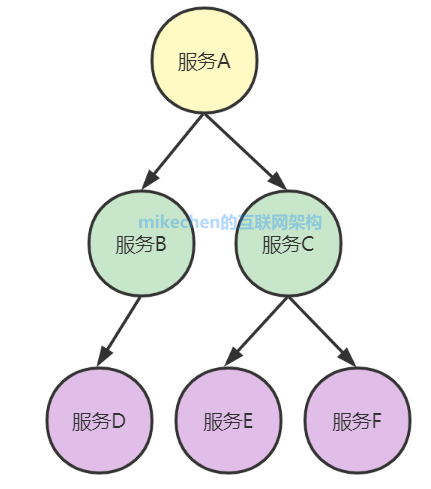
3. Zipkin 核心结构
当用户发起一次调用时,Zipkin 的客户端会在入口处为整条调用链路生成一个全局唯一的 trace id,并为这条链路中的每一次分布式调用生成一个 span id。
一个 trace 由一组 span 组成,可以看成是由 trace 为根节点,span 为若干个子节点的一棵树,如下图所示:
4. Zipkin 的工作流程
一个应用的代码发起 HTTP get 请求,经过 Trace 框架拦截,大致流程如下图所示:
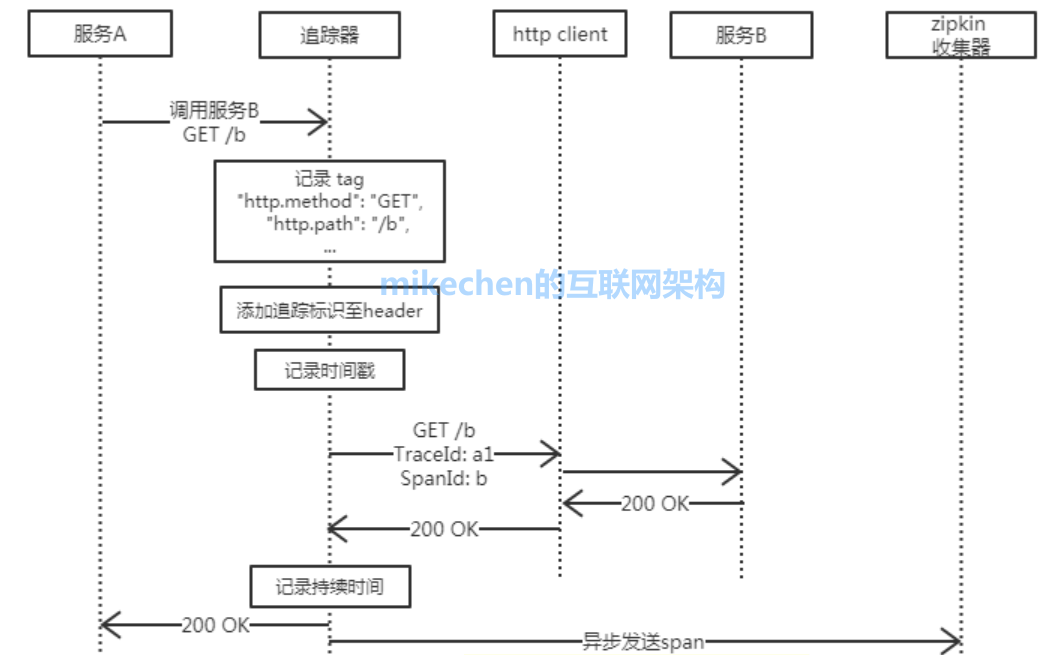
1)把当前调用链的 Trace 信息,添加到 HTTP Header 里面;
2)记录当前调用的时间戳;
3)发送 HTTP 请求,把 trace 相关的 header 信息携带上;
4)调用结束之后,记录当前调用话费的时间;
5)把上面流程产生的信息,汇集成一个 span,再把这个 span 信息上传到 zipkin 的 Collector 模块。
Zipkin 的部署与运行
Zipkin 的 github 地址:https://github.com/apache/incubator-zipkin
Zipkin 支持的存储类型有 inMemory、MySql、Cassandra、以及 ElasticsSearch 几种方式,正式环境推荐使用 Cassandra 和 ElasticSearch。
总结
通过本文,我们知道了 Zipkin 的作用、使用场景、架构、核心组件,以及 Zipkin 的工作流程等,希望对大家掌握微服务有所帮助。
作者简介
陈睿 | mikechen , 10年+大厂架构经验,「mikechen 的互联网架构」系列文章作者,专注于互联网架构技术。
阅读「mikechen 的互联网架构」40W 字技术文章合集
Java并发 | JVM | MySQL | Spring | Redis | 分布式 | 高并发
微服务 Zipkin 链路追踪原理(图文详解)的更多相关文章
- SpringBoot之微服务日志链路追踪
SpringBoot之微服务日志链路追踪 简介 在微服务里,业务出现问题或者程序出的任何问题,都少不了查看日志,一般我们使用 ELK 相关的日志收集工具,服务多的情况下,业务问题也是有些难以排查,只能 ...
- MapReduce工作原理图文详解 (炼数成金)
MapReduce工作原理图文详解 1.Map-Reduce 工作机制剖析图: 1.首先,第一步,我们先编写好我们的map-reduce程序,然后在一个client 节点里面进行提交.(一般来说可以在 ...
- MapReduce 1工作原理图文详解
MapReduce工作原理图文详解 一 MapReduce程序执行流程 程序执行流程图如下: 流程分析:1.在客户端启动一个作业.2.向JobTracker请求一个Job ID.3.将运行作业所需要的 ...
- 详解ElasticAPM实现微服务的链路追踪(NET)
前言 Elastic APM实现链路追踪,首先要引用开源的APMAgent(APM代理),然后将监控的信息发送到APMServer,然后在转存入ElasticSearch,最后有Kibana展示:具体 ...
- SpringCloud微服务项目实战 - API网关Gateway详解实现
前面讲过zuul的网关实现,那为什么今天又要讲Spring Cloud Gateway呢?原因很简单.就是Spring Cloud已经放弃Netflix Zuul了.现在Spring Cloud中引用 ...
- Spring Boot (九): 微服务应用监控 Spring Boot Actuator 详解
1. 引言 在当前的微服务架构方式下,我们会有很多的服务部署在不同的机器上,相互是通过服务调用的方式进行交互,一个完整的业务流程中间会经过很多个微服务的处理和传递,那么,如何能知道每个服务的健康状况就 ...
- 微服务架构:Eureka参数配置项详解
版权声明:本文为博主原创文章,转载请注明出处,欢迎交流学习! Eureka涉及到的参数配置项数量众多,它的很多功能都是通过参数配置来实现的,了解这些参数的含义有助于我们更好的应用Eureka的各种功能 ...
- 【SpringCloud构建微服务系列】Feign的使用详解
一.简介 在微服务中,服务消费者需要请求服务生产者的接口进行消费,可以使用SpringBoot自带的RestTemplate或者HttpClient实现,但是都过于麻烦. 这时,就可以使用Feign了 ...
- vue内置组件——transition简单原理图文详解
基本概念 Vue 在插入.更新或者移除 DOM 时,提供多种不同方式的应用过渡效果 在 CSS 过渡和动画中自动应用 class 可以配合使用第三方 CSS 动画库,如 Animate.css 在过渡 ...
随机推荐
- ASP.NET Core 5.0中的Host.CreateDefaultBuilder执行过程
通过Rider调试的方式看了下ASP.NET Core 5.0的Web API默认项目,重点关注Host.CreateDefaultBuilder(args)中的执行过程,主要包括主机配置.应用程 ...
- CF208E Blood Cousins(DSU,倍增)
倍增求出祖先,\(\text{DSU}\)统计 本来想用树剖求\(K\)祖,来条链复杂度就假了 #include <cstring> #include <cstdio> #in ...
- 用Socket套接字发送和接收文件(中间用数组存取)
创建服务端: public class TcpFileServer { public static void main(String[] args) throws Exception { //1创建S ...
- 一次客户需求引发的K8S网络探究
前言 在本次案例中,我们的中台技术工程师遇到了来自客户提出的打破k8s产品功能限制的特殊需求,面对这个极具挑战的任务,攻城狮最终是否克服了重重困难,帮助客户完美实现了需求?且看本期K8S技术案例分享! ...
- Android序列化的几种实现方式
一.Serializable序列化 Serializable是java提供的一种序列化方式,其使用方式非常简单,只需要实现Serializable接口就可以实现序列化. public interfac ...
- MQ系列5:RocketMQ消息的发送模式
MQ系列1:消息中间件执行原理 MQ系列2:消息中间件的技术选型 MQ系列3:RocketMQ 架构分析 MQ系列4:NameServer 原理解析 在之前的篇章中,我们学习了RocketMQ的原理, ...
- ClickHouse(05)ClickHouse数据类型详解
ClickHouse属于分析型数据库,ClickHouse提供了许多数据类型,它们可以划分为基础类型.复合类型和特殊类型.其中基础类型使ClickHouse具备了描述数据的基本能力,而另外两种类型则使 ...
- noip2018提高组初赛试题
一.单项选择题(共 10 题,每题 2 分,共计 20 分: 每题有且仅有一个正确选项) \2. 下列属于解释执行的程序设计语言是( ). A. C B. C++ C. Pascal D. Pytho ...
- C++ 初识函数模板
1. 前言 什么是函数模板? 理解什么是函数模板,须先搞清楚为什么需要函数模板. 如果现在有一个需求,要求编写一个求 2 个数字中最小数字的函数,这 2 个数字可以是 int类型,可以是 float ...
- MySQL8.0报错:Access denied; you need (at least one of) the SYSTEM_USER privilege(s) for this operation
MySQL8.0.16版本中新增了一个system_user帐户类型,当新增用户并赋予权限时 mysql> create user 'proxysql'@'192.168.20.%' ident ...