【大数据面试】Hbase:数据、模型结构、操作、读写数据流程、集成、优化
一、概述
1、概念
分布式、可扩展、海量数据存储的NoSQL数据库
2、模型结构
(1)逻辑结构
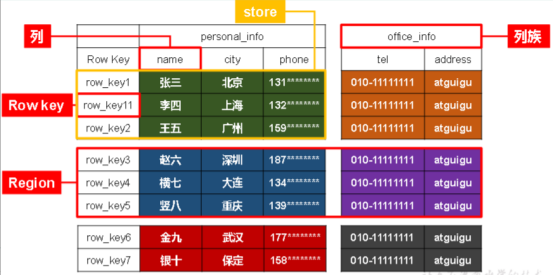
store相当于某张表中的某个列族
(2)存储结构
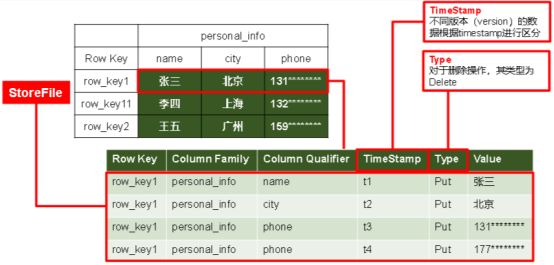
(3)模型介绍
Name Space:相当于数据库,包含很多张表
Region:类似于表,定义表时只需要声明列族,不需要声明具体的列。【字段可以动态、按需指定】
Row:每行数据按RowKey字典序存储,且只能根据RowKey检索
Column:由Column Family(列族)和Column Qualifier(列限定符,即列名,无需预先定义)进行限定,例如info:name,info:age。
Column Family:列族
Time Stamp:标识数据的不同版本
Cell:由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元/记录?
3、Hbase架构
(1)结构图
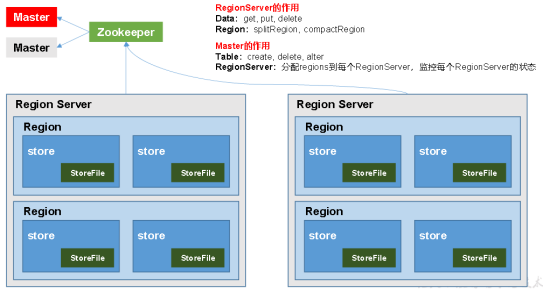
(2)架构角色
Region Server:Region的管理者,其实现类为HRegionServer,可以实现对数据的操作(get, put, delete)和对Region的操作(splitRegion、compactRegion)
Master:Region Server的管理者,实现类为HMaster,可以实现对表的操作(create, delete, alter)和对Region Server的操作(分配regions、监控ser的状态、负载均衡和故障转移)
Zookeeper:Master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护
HDFS:底层数据存储、HBase的高可用
二、操作及进阶
1、入门操作
(1)启动
分别启动:bin/hbase-daemon.sh start master及regionserver
共同启动:bin/start-hbase.sh,查看页面:http://hadoop102:16010
配置HMaster的HA高可用:backup-masters文件并同步scp
(2)常见操作
进入命令行:bin/hbase shell
表的操作:create、put、scan、describe、count、delete、truncate清空表、get 'student','1001'指定行,'info:name'指定列族: 列、drop删除表、
2、架构原理
StoreFile:实际保存的物理文件,以HFile的形式存储在HDFS上,数据有序
MemStore:写缓存,先存储在MemStore中,排好序再刷写到StoreFile
WAL:写内存容易数据丢失,先写在一个叫做Write-Ahead logfile的文件中,然后再写入MemStore中;系统出现故障的时候,数据可以通过这个日志文件重建。
3、写数据流程
Client通过zk获取Region Server地址
(追加)到WAL,写入对应的MemStore
向client发送ack,等到刷写时机后,将数据刷写到HFile
4、MemStore Flush数据刷写
memstore的总大小达到java_heapsize时
到达自动刷写的时间,也会触发memstore flush
5、StoreFile Compaction
memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile
为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。
Minor Compaction:临近的HFile合并,但不会清理删除
Major Compaction:Store下的所有HFile合并,同时会清理和删除
6、Region Split拆分
每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分
由于负载均衡,可能会将当前table的region转移到其他region server上
7、读数据流程
访问zk,获取hbase:meta表位于哪个Region Server
根据读请求的namespace:table/rowkey获取region并缓存到meta cache
查询目标数据并合并
8、RowKey设计
(1)设计原则
1)rowkey长度原则
2)rowkey散列原则
3)rowkey唯一原则
(2)设计方式
1)生成随机数、hash、散列值
2)字符串反转
三、集成
1、集成Phoenix
(1)Phoenix介绍
使用标准JDBC API代替HBase客户端API
特点:容易集成、操作简单、支持二级索引
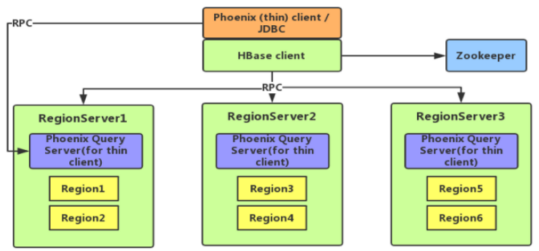
(2)常见操作
安装:server和client拷贝
显示所有表:!tables
建表:表名等会自动转换为大写,加双引号可以指定小写
插入数据:upsert into student values
退出命令行:!quit
(3)视图&表映射
创建关联test表的视图:create view "test"(id varchar primary key,"info1"."name" varchar, "info2"."address" varchar);
删除视图:drop view "test";
(4)二级索引
二级索引配置文件
全局二级索引:创建新表,适用于多读少写的业务场景
本地二级索引:Local Index适用于写操作频繁
2、集成Hive
(1)HBase与Hive的对比



(2)Hive插入数据后影响Hbase
Hive中创建临时中间表,用于load文件中的数据
insert命令将中间表中的数据导入到Hive关联Hbase的那张表中
(3)借助Hive分析HBase表
Hive中创建外部表
使用Hive函数进行分析操作
四、优化
1、region预分区
提前规划region分区,提高性能
create 'staff1','info','partition1',SPLITS => ['1000','2000','3000','4000']
方式:手工设定、生成16进制序列、按文件规则、使用java api
2、基础优化,配置hbase-site.xml
允许在HDFS的文件中追加内容
优化DataNode允许的最大文件打开数
优化延迟高的数据操作的等待时间
优化数据的写入效率
设置RPC监听数量
优化HStore文件大小
指定scan.next扫描HBase所获取的行数
flush、compact、split机制
【大数据面试】Hbase:数据、模型结构、操作、读写数据流程、集成、优化的更多相关文章
- 随想:目标识别中,自适应样本均衡设计,自适应模型结构(参数可变自适应,模型结构自适应,数据类别or分布自适应)
在现在的机器学习中,很多人都在研究自适应的参数,不需要人工调参,但是仅仅是自动调参就不能根本上解决 ai识别准确度达不到实际生产的要求和落地困难的问题吗?结论可想而知.如果不改变参数,那就得从算法的结 ...
- mysql数据表的基本操作:表结构操作,字段操作
本节介绍: 表结构操作 创建数据表. 查看数据表和查看字段. 修改数据表结构 删除数据表 字段操作 新增字段. 修改字段数据类型.位置或属性. 重命名字段 删除字段 首发时间:2018-02-18 ...
- 第六章 Odoo 12开发之模型 - 结构化应用数据
在本系列文章第三篇Odoo 12 开发之创建第一个 Odoo 应用中,我们概览了创建 Odoo 应用所需的所有组件.本文及接下来的一篇我们将深入到组成应用的每一层:模型层.视图层和业务逻辑层. 本文中 ...
- osg fbx 模型结构操作
osg::Node* TeslaManage::findOsgNodeByName(QString &nodeNme) { osg::Node* findNode = NULL; std::v ...
- 大数据(10) - HBase的安装与使用
HBaes介绍 HBase是什么? 数据库 非关系型数据库(Not-Only-SQL) NoSQL 强依赖于HDFS(基于HDFS) 按照BigTable论文思想开发而来 面向列来存储 可以用来存储: ...
- 大数据学习day34---spark14------1 redis的事务(pipeline)测试 ,2. 利用redis的pipeline实现数据统计的exactlyonce ,3 SparkStreaming中数据写入Hbase实现ExactlyOnce, 4.Spark StandAlone的执行模式,5 spark on yarn
1 redis的事务(pipeline)测试 Redis本身对数据进行操作,单条命令是原子性的,但事务不保证原子性,且没有回滚.事务中任何命令执行失败,其余的命令仍会被执行,将Redis的多个操作放到 ...
- Sqoop将mysql数据导入hbase的血与泪
Sqoop将mysql数据导入hbase的血与泪(整整搞了大半天) 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: https://my.oschina.net/yunsh ...
- Hbase单机安装及使用hbase shell进行简单操作
一,配置环境变量 在etc/prifile中加入java环境变量及hbase环境变量: #set java environment JAVA_HOME=/usr/local/lhc/jdk1.8.0_ ...
- 大数据入门第十四天——Hbase详解(三)hbase基本原理与MR操作Hbase
一.基本原理 1.hbase的位置 上图描述了Hadoop 2.0生态系统中的各层结构.其中HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持, MapReduce为HBas ...
- 大数据查询——HBase读写设计与实践
导语:本文介绍的项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询.原实现基于 Oracle 提供存储查询服务,随着数据量的 ...
随机推荐
- ProxySQL结构
Qurey Processor 用于匹配查询规则并根据规则决定是否缓存查询或者将查询加入黑名单或者重新路由.重写查询或者镜像查询到其他hostgroup. User Auth 为底层后端数据库认证提供 ...
- Kubernetes Operator: Operator
Operator 就可以看成是 CRD 和 Controller 的一种组合特例,Operator 是一种思想,它结合了特定领域知识并通过 CRD 机制扩展了 Kubernetes API 资源,使用 ...
- kibana启动停止命令
前提条件:kibana文件是属于kibana用户的 注意:路径根据具体实际情况修改 更改日志所属用户和用户组 chown kibana:kibana /usr/local/kibana-7.5.1-l ...
- docker方式安装Redash
之前使用的项目GitHub地址是https://github.com/dazdata/redash.git,这个是直接复制国外的项目的,地址:https://github.com/getredash/ ...
- 【golang】json数据解析 - 嵌套json解析
@ 目录 1. 通过结构体映射解析 2. 嵌套json解析-map 1. 通过结构体映射解析 原数据结构 解析 // 结构体 type contractJson struct { Data []tra ...
- RabbitMQ原理和架构图解(附6大工作模式)
为什么要使用RabbitMQ? 1.解耦 系统A在代码中直接调用系统B和系统C的代码,如果将来D系统接入,系统A还需要修改代码,过于麻烦. 2.异步 将消息写入消息队列,非必要的业务逻辑以异步的方式运 ...
- P7114 [NOIP2020] 字符串匹配 (字符串hash+树状数组)
好多题解用的扩展KMP(没学过,所以不用这种方法). 我们按照题目要求记F(s)表示s串的权值,可以预处理出前缀权值(用于A)和后缀权值(用于C),枚举AB的长度i=2~n-1,不需要分开枚举,我们只 ...
- git记不住用户名跟密码,每次提交拉取都需要再次输入
问题:之前为了测试git提交的一个问题,选择不记住用户名跟密码,输入如下命令即可不记住 git credential-manager uninstall git update-git-for-wind ...
- Sentinel安装教程【Linux+windows】
一.Sentinel的简介 Sentinel是阿里巴巴出品的一款流控组件,它以流量为切入点,在流量控制.断路.负载保护等多个领域开展工作,保障服务可靠性. 如果你学过netflix公司旗下的Hystr ...
- MyBatisPlus 常用知识点总结
@ 目录 完整的Mybatis-Plus项目 常用注解 设置表名(@TableName) 设置实体类字段 (@TableField) 通过 @TableField(fill=FieldFill.INS ...