【大数据面试】Hbase:数据、模型结构、操作、读写数据流程、集成、优化
一、概述
1、概念
分布式、可扩展、海量数据存储的NoSQL数据库
2、模型结构
(1)逻辑结构
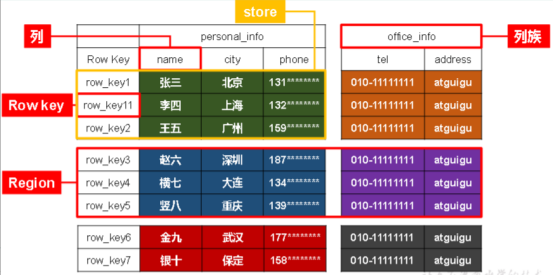
store相当于某张表中的某个列族
(2)存储结构
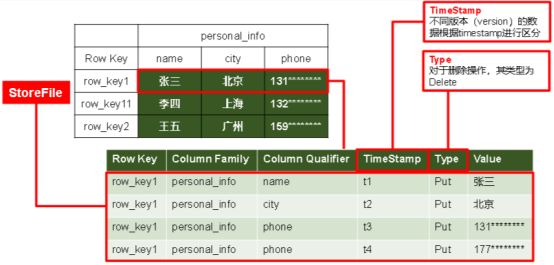
(3)模型介绍
Name Space:相当于数据库,包含很多张表
Region:类似于表,定义表时只需要声明列族,不需要声明具体的列。【字段可以动态、按需指定】
Row:每行数据按RowKey字典序存储,且只能根据RowKey检索
Column:由Column Family(列族)和Column Qualifier(列限定符,即列名,无需预先定义)进行限定,例如info:name,info:age。
Column Family:列族
Time Stamp:标识数据的不同版本
Cell:由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元/记录?
3、Hbase架构
(1)结构图
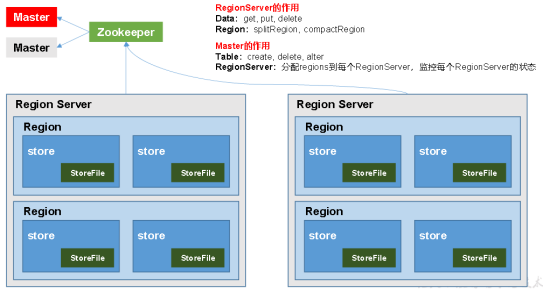
(2)架构角色
Region Server:Region的管理者,其实现类为HRegionServer,可以实现对数据的操作(get, put, delete)和对Region的操作(splitRegion、compactRegion)
Master:Region Server的管理者,实现类为HMaster,可以实现对表的操作(create, delete, alter)和对Region Server的操作(分配regions、监控ser的状态、负载均衡和故障转移)
Zookeeper:Master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护
HDFS:底层数据存储、HBase的高可用
二、操作及进阶
1、入门操作
(1)启动
分别启动:bin/hbase-daemon.sh start master及regionserver
共同启动:bin/start-hbase.sh,查看页面:http://hadoop102:16010
配置HMaster的HA高可用:backup-masters文件并同步scp
(2)常见操作
进入命令行:bin/hbase shell
表的操作:create、put、scan、describe、count、delete、truncate清空表、get 'student','1001'指定行,'info:name'指定列族: 列、drop删除表、
2、架构原理
StoreFile:实际保存的物理文件,以HFile的形式存储在HDFS上,数据有序
MemStore:写缓存,先存储在MemStore中,排好序再刷写到StoreFile
WAL:写内存容易数据丢失,先写在一个叫做Write-Ahead logfile的文件中,然后再写入MemStore中;系统出现故障的时候,数据可以通过这个日志文件重建。
3、写数据流程
Client通过zk获取Region Server地址
(追加)到WAL,写入对应的MemStore
向client发送ack,等到刷写时机后,将数据刷写到HFile
4、MemStore Flush数据刷写
memstore的总大小达到java_heapsize时
到达自动刷写的时间,也会触发memstore flush
5、StoreFile Compaction
memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile
为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。
Minor Compaction:临近的HFile合并,但不会清理删除
Major Compaction:Store下的所有HFile合并,同时会清理和删除
6、Region Split拆分
每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分
由于负载均衡,可能会将当前table的region转移到其他region server上
7、读数据流程
访问zk,获取hbase:meta表位于哪个Region Server
根据读请求的namespace:table/rowkey获取region并缓存到meta cache
查询目标数据并合并
8、RowKey设计
(1)设计原则
1)rowkey长度原则
2)rowkey散列原则
3)rowkey唯一原则
(2)设计方式
1)生成随机数、hash、散列值
2)字符串反转
三、集成
1、集成Phoenix
(1)Phoenix介绍
使用标准JDBC API代替HBase客户端API
特点:容易集成、操作简单、支持二级索引
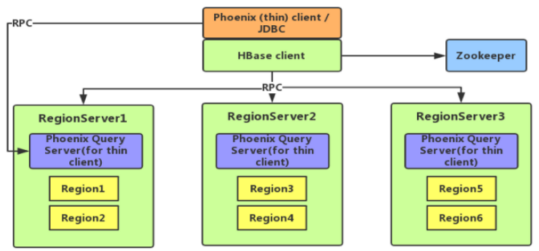
(2)常见操作
安装:server和client拷贝
显示所有表:!tables
建表:表名等会自动转换为大写,加双引号可以指定小写
插入数据:upsert into student values
退出命令行:!quit
(3)视图&表映射
创建关联test表的视图:create view "test"(id varchar primary key,"info1"."name" varchar, "info2"."address" varchar);
删除视图:drop view "test";
(4)二级索引
二级索引配置文件
全局二级索引:创建新表,适用于多读少写的业务场景
本地二级索引:Local Index适用于写操作频繁
2、集成Hive
(1)HBase与Hive的对比



(2)Hive插入数据后影响Hbase
Hive中创建临时中间表,用于load文件中的数据
insert命令将中间表中的数据导入到Hive关联Hbase的那张表中
(3)借助Hive分析HBase表
Hive中创建外部表
使用Hive函数进行分析操作
四、优化
1、region预分区
提前规划region分区,提高性能
create 'staff1','info','partition1',SPLITS => ['1000','2000','3000','4000']
方式:手工设定、生成16进制序列、按文件规则、使用java api
2、基础优化,配置hbase-site.xml
允许在HDFS的文件中追加内容
优化DataNode允许的最大文件打开数
优化延迟高的数据操作的等待时间
优化数据的写入效率
设置RPC监听数量
优化HStore文件大小
指定scan.next扫描HBase所获取的行数
flush、compact、split机制
【大数据面试】Hbase:数据、模型结构、操作、读写数据流程、集成、优化的更多相关文章
- 随想:目标识别中,自适应样本均衡设计,自适应模型结构(参数可变自适应,模型结构自适应,数据类别or分布自适应)
在现在的机器学习中,很多人都在研究自适应的参数,不需要人工调参,但是仅仅是自动调参就不能根本上解决 ai识别准确度达不到实际生产的要求和落地困难的问题吗?结论可想而知.如果不改变参数,那就得从算法的结 ...
- mysql数据表的基本操作:表结构操作,字段操作
本节介绍: 表结构操作 创建数据表. 查看数据表和查看字段. 修改数据表结构 删除数据表 字段操作 新增字段. 修改字段数据类型.位置或属性. 重命名字段 删除字段 首发时间:2018-02-18 ...
- 第六章 Odoo 12开发之模型 - 结构化应用数据
在本系列文章第三篇Odoo 12 开发之创建第一个 Odoo 应用中,我们概览了创建 Odoo 应用所需的所有组件.本文及接下来的一篇我们将深入到组成应用的每一层:模型层.视图层和业务逻辑层. 本文中 ...
- osg fbx 模型结构操作
osg::Node* TeslaManage::findOsgNodeByName(QString &nodeNme) { osg::Node* findNode = NULL; std::v ...
- 大数据(10) - HBase的安装与使用
HBaes介绍 HBase是什么? 数据库 非关系型数据库(Not-Only-SQL) NoSQL 强依赖于HDFS(基于HDFS) 按照BigTable论文思想开发而来 面向列来存储 可以用来存储: ...
- 大数据学习day34---spark14------1 redis的事务(pipeline)测试 ,2. 利用redis的pipeline实现数据统计的exactlyonce ,3 SparkStreaming中数据写入Hbase实现ExactlyOnce, 4.Spark StandAlone的执行模式,5 spark on yarn
1 redis的事务(pipeline)测试 Redis本身对数据进行操作,单条命令是原子性的,但事务不保证原子性,且没有回滚.事务中任何命令执行失败,其余的命令仍会被执行,将Redis的多个操作放到 ...
- Sqoop将mysql数据导入hbase的血与泪
Sqoop将mysql数据导入hbase的血与泪(整整搞了大半天) 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: https://my.oschina.net/yunsh ...
- Hbase单机安装及使用hbase shell进行简单操作
一,配置环境变量 在etc/prifile中加入java环境变量及hbase环境变量: #set java environment JAVA_HOME=/usr/local/lhc/jdk1.8.0_ ...
- 大数据入门第十四天——Hbase详解(三)hbase基本原理与MR操作Hbase
一.基本原理 1.hbase的位置 上图描述了Hadoop 2.0生态系统中的各层结构.其中HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持, MapReduce为HBas ...
- 大数据查询——HBase读写设计与实践
导语:本文介绍的项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询.原实现基于 Oracle 提供存储查询服务,随着数据量的 ...
随机推荐
- ProxySQL Cluster 高可用集群 + MySQL MGR环境部署 (多写模式) 部署记录
文章转载自:https://blog.51cto.com/u_6215974/4937192 ProxySQL 在早期版本若需要做高可用,需要搭建两个实例,进行冗余.但两个ProxySQL实例之间的数 ...
- Traefik知识点
Traefik 的各种 Providers Traefik 中的配置发现是通过下面的一些 providers 来实现的. providers 是现有的一些基础架构组件,可以是编排工具,容器引擎,云提供 ...
- 智能工厂的ERP和MES之间的区别?
无论在哪里,ERP(Enterprise Resource Planning,企业资源计划)和MES(Manufacturing Execution System,即制造执行系统)系统都不是同样的东西 ...
- [题解] Codeforces 438 E The Child and Binary Tree DP,多项式,生成函数
题目 首先令\(f_i\)表示权值和为\(i\)的二叉树数量,\(f_0=1\). 转移为:\(f_k=\sum_{i=0}^n \sum_{j=0}^{k-c_i}f_j f_{k-c_i-j}\) ...
- Petrozavodsk Winter Training Camp 2016: Moscow SU Trinity Contest
题目列表 A.ABBA E.Elvis Presley G. Biological Software Utilities J. Burnished Security Updates A.ABBA 题意 ...
- Linux命令全解
strace 获取某个可执行文件执行过程中用到的所有系统调用 :strace -f g++ main.cpp &| vim 查看g++编译过程调用了哪些系统调用,通过管道符用vim接收 :%! ...
- httpd常用配置之虚拟主机
httpd常用配置 目录 httpd常用配置 虚拟主机: 相同IP不同端口 不同IP相同端口 相同IP相同端口不同域名 切换使用MPM(编辑/etc/httpd/conf.modules.d/00-m ...
- ExceptionHandler配合RestControllerAdvice全局处理异常
Java全局处理异常 引言 对于controller中的代码,为了保证其稳定性,我们总会对每一个controller中的代码进行try-catch,但是由于接口太多,try-catch会显得太冗杂,s ...
- Application保存作用域
Application保存作用域,作用范围:一次应用程序范围有效.Application属性范围值,只要设置一次,则所有的网页窗口都可以取得数据. ServletContext在服务器启动时创建,在服 ...
- reportportal 集成 robotframework 自动化执行及结果可视化
前言: 最近领导想了个需求,想把目前组内在linux平台上执行的自动化脚本搞成可视化,如果是web站点相关日志可视化倒是简单了,ELK就是不错的选择,大部分可视化项目这种的,可以做的开起来很炫. 我们 ...