HBase海量数据高效入仓解决方案
一、方案背景
现阶段部分业务数据存储在HBase中,这部分数据体量较大,达到数十亿。大数据需要增量同步这部分业务数据到数据仓库中,进行离线分析,目前主要的同步方式是通过HBase的hive映射表来实现的。该种方式具有以下痛点:
需要对HBase表进行全表扫描,对HBase库有一定压力,同步数据同步速度慢。
业务方对HBase表字段变更之后,需要重建hive映射表,给权限维护带来一定的困难。
业务方对HBase表字段的变更无法得到有效监控,无法及时感知字段的新增,对数仓的维护带来一定的困难。
业务方更新数据时未更新时间戳,导致通过时间戳字段增量抽取时数据缺失。
业务方对表字段的更新新增无法及时感知,导致字段不全需要回溯数据。
基于以上背景,对HBase数据增量同步到数仓的场景,给出了通用的解决方案,解决了以上这些痛点。
二、方案简述
2.1 数据入仓构建流程
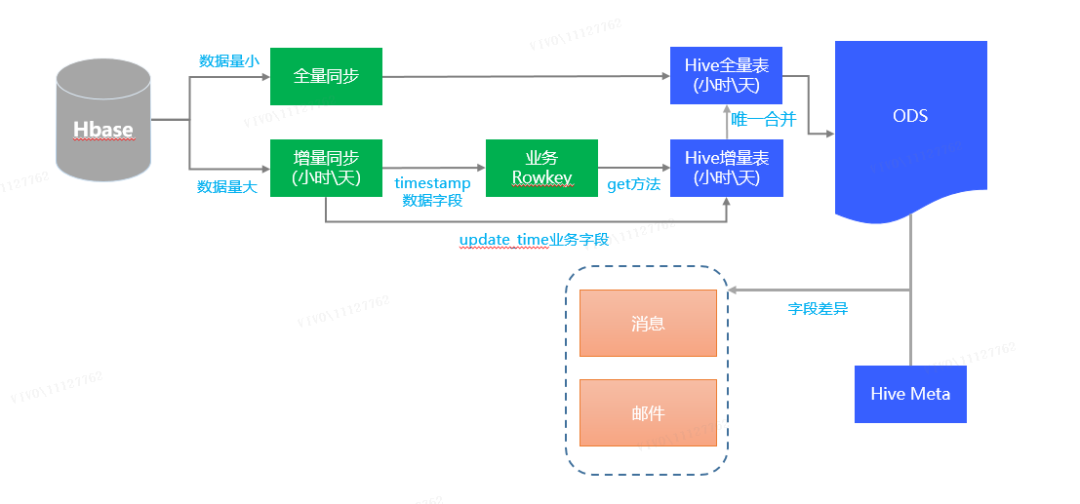
2.2 HBase数据入仓方案实验对比

分别对以上三种实现方案进行合理性分析。
2.2.1 方案一
使用HBase的hive映射表。此种方案实现方式简单,但是不符合数仓的实现机制,主要原因有:
HBase表虽然是Hadoop生态体系的NoSQL数据库,但是其作为业务方的数据库,直接通过hive映射表读取,就类比于直接读取业务方Mysql中的视图,可能会对业务方数据库造成一定压力,甚至会影响业务的正常运行,违反数仓尽可能低的影响业务运行原则。
通过hive映射表的方式,从实现方式上来讲,增加了与业务方的耦合度,违反数仓建设解耦原则。
所以此种方案在此实际应用场景中,是不应该采取的方案。
2.2.2 方案二
根据业务表中的时间戳字段,抓取增量数据。由于HBase是基于rowKey的NoSQL数据库,所以会存在以下几个问题:
需要通过Scan全表,然后根据时间戳(updateTime)过滤出当天的增量,当数据量达到千万甚至亿级时,这种执行效率就很低,运行时长很长。
由于HBase表更新数据时,不像MySQL一样,能自动更新时间戳,会导致业务方没有及时更新时间戳,那么在增量抽取数据的时候,会造成数据缺失的情况。
所以此种方案存在一定的风险。
2.2.3 方案三
根据HBase的timeRange特性(HBase写入数据的时候会记录时间戳,使用的是服务器时间),首先过滤出增量的rowKey,然后根据这些rowKey去HBase查询对应的数据。这种实现方案同时解决了方案一、方案二的问题。同时,能够有效监控业务方对HBase表字段的新增情况,避免业务方未及时通知而导致的数据缺失问题,能够最大限度的减少数据回溯的频率。
综上,采用方案三作为实现HBase海量数据入仓的解决方案。
2.3 方案选择及实现原理
基于HBase数据写入时会更新TimeRange的特性,scan的时候如果指定TimeRange,那么就不需要扫描全表,直接根据TimeRange获取到对应的rowKey,然后再根据rowKey去get出增量信息,能够实现快速高效的获取增量数据。
为什么scan之后还要再去get呢?主要是因为通过timeRanme出来的数据,只包含这个时间范围内更新的列,而无法查询到这个rowkey对应的所有字段。比如一个rowkey有name,age两个字段,在指定时间范围内只更新了age字段,那么在scan的时候,只能查询出age字段,而无法查询出name字段,所以要再get一次。同时,获取增量数据对应的columns,跟hive表的meta数据进行比对,对字段的变更进行及时预警,减少后续因少同步字段内容而导致全量初始化的情况发生。其实现的原理图如下:
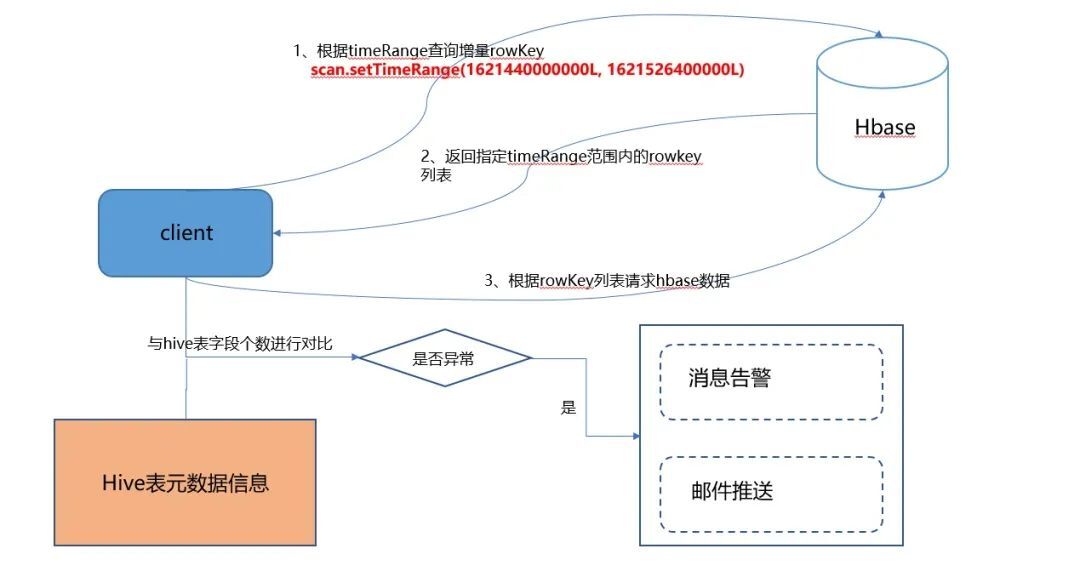
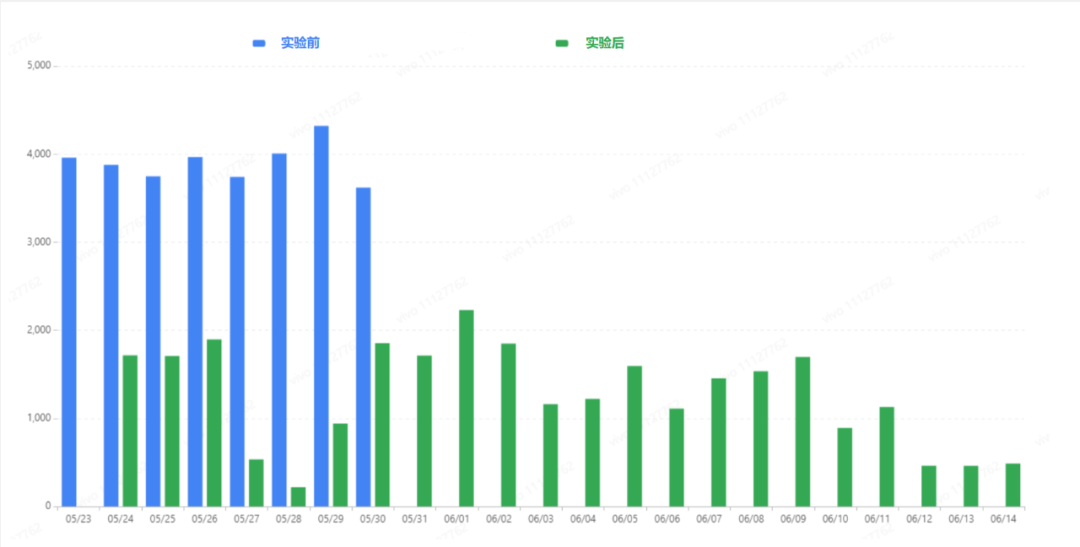
三、效果对比
运行时间对比如下(单位:秒):
四、总结与展望
数据仓库的数据来源于各方业务系统,高效准确的将业务系统的数据同步到数仓,是数仓建设的根本。通过该解决方案,主要解决了数据同步过程中的几大痛点问题,能够较好的保证数据入仓的质量问题,为后续的数仓建设打下一个较好的基础。
另外,通过多次实验对比,及对各种方案的可行性分析,将数据同步方案同步给一站式大数据开发平台,推动大数据开发平台支持基于timeRange的增量同步功能,实现此功能的平台化、配置化,解决了HBase海量数据入仓的痛点。
同时,除了以上这几种解决方案之外,还可以尝试结合Phoenix使用二级索引,然后通过查询Phoenix表的方式同步到数仓,这个将在后期进行性能测试。
作者:vivo互联网大数据团队-Tang Xicheng
HBase海量数据高效入仓解决方案的更多相关文章
- Data Warehouse 业务系统不入仓表
根据数据仓库的实施经验,凡符合如下特征的表,建议不入仓. ① 备份数据表 此类表是对现有表中某个时点数据的一份拷贝,根据需要进行数据恢复使用.因此,只需取当前表中的数据即可. ② 冗余数据表 同一类数 ...
- 运维相关指标数据采集并ES入仓 - 运维笔记
为了进行数字化IT治理,需要对一些应用进程相关指标进行采集并入库.收集到的应用指标数据最好要进行ES入仓,入到Kafka里面,并通过Kibana可视化展示. 需要进行采集的应用进程相关指标如下: ES ...
- 华为云Stack南向开放框架,帮助生态伙伴高效入云
摘要:CloudBonder的生态社区通过一系列生态项目,解决提交叉组合.架构分层不清晰.运维界面不清晰等问题,简化对接流程,降低生态伙伴对接成本,缩短对接时间. 本文分享自华为云社区<[华为云 ...
- HBase海量数据存储
1.简介 HBase是一个基于HDFS的.分布式的.面向列的非关系型数据库. HBase的特点 1.海量数据存储,HBase表中的数据能够容纳上百亿行*上百万列. 2.面向列的存储,数据在表中是按照列 ...
- ld: framework not found AGCommon 关于三方库到入 问题解决方案!!
ld: framework not found AGCommon clang:error:linker command failed with exit code 1 (use -v to see ...
- ERROR:org.apache.hadoop.hbase.PleaseHoldException: Master is initializing 解决方案
我尝试的过程如下 1. 时间没有同步 用date命令看一下每个机器 如果时间差距大 说明确实有问题 ** 配置时间服务器 ** 检查时区 $ d ...
- php个人博客搭建第二阶段②
网站正文部分:热门博客的推荐: html代码: <!-- 网站正文部分 --> <div class="content"> < ...
- 华为云FusionInsight湖仓一体解决方案的前世今生
摘要:华为云发布新一代智能数据湖华为云FusionInsight时再次提到了湖仓一体理念,那我们就来看看湖仓一体的来世今生. 伴随5G.大数据.AI.IoT的飞速发展,数据呈现大规模.多样性的极速增长 ...
- 浅析HBase:为高效的可扩展大规模分布式系统而生
什么是HBase Apache HBase是运行在Hadoop集群上的数据库.为了实现更好的可扩展性(scalability),HBase放松了对ACID(数据库的原子性,一致性,隔离性和持久性)的要 ...
随机推荐
- Unsupported major.minor version 52.0报错问题解决方案
感谢原文:https://blog.csdn.net/wangmaohong0717/article/details/82869359 1.问题描述 工程启动的时候,报错如下: nested exce ...
- Springboot原理
1. SpringBoot特点 一个starter导入所有 依赖管理 父项目做依赖管理:声明了所需依赖的版本号 依赖管理 <parent> <groupId>org.sprin ...
- sqli-labs 1-22关
Page-1(Basic Challenges) Less 1-4 Less-(1-4)是最常规的SQL查询,分别采用单引号闭合.无引号.括号单引号闭合.括号双引号闭合,没有过滤:可以采用and '1 ...
- Web渗透测试入门之SQL注入(上篇)
题记: 本来今天想把白天刷的攻防世界Web进阶的做个总结,结果估计服务器抽疯环境老报错,然后想了下今天用到了SQL注入,文件上传等等,写写心得.相信很多朋友都一直想学好渗透,然后看到各种入门视频,入门 ...
- 【基础篇】js对本地文件增删改查--删
前置条件: 1. 本地有安装node,点击传送门 项目目录: 1. msg.json内容 { "data": [ { "id": 1, "name&q ...
- vulhub漏洞环境
0x00 vulhub介绍 Vulhub是一个基于docker和docker-compose的漏洞环境集合,进入对应目录并执行一条语句即可启动一个全新的漏洞环境,让漏洞复现变得更加简单,让安全研究者更 ...
- windows消息机制框架原理【简单版本】
windows消息机制框架原理 结合两张图理解 窗口和窗口类 Windows UI 应用程序 (e) 具有一个主线程 (g).一个或多个窗口 (a) 和一个或多个子线程 (k) [工作线程或 UI 线 ...
- 网络中delay和latency的区别
时序分析基本概念是Latency, 时钟传播延迟.主要指从Clock源到时序组件Clock输入端的延迟时间.它可以分为两个部分:时钟源插入延迟(source latency)和时钟网络延迟(netwo ...
- Scala学习笔记(详细)
第2章 变量 val,var,声明变量必须初始化:变量类型确定后不可更改 数据类型:与java有相同的数据类型,在scala中数据类型都是对象 特殊类型:Unit:表示无值,只有一个实例值写出(),相 ...
- 服务器CPU很高-怎么办(Windbg使用坑点)
最近,碰到了一个线上CPU服务器很高的问题,并且也相当紧急,接到这个任务后,我便想到C#性能分析利器,Windbg. 终于在折腾半天之后,找出了问题,成功解决,这里就和大家分享一下碰到的问题. 问题1 ...