python之路--关于线程的一些方法
一 . 线程的两种创建方式
from threading import Thread
# 第一种创建方式
def f1(n):
print('%s号线程任务'%n)
def f2(n):
print('%s号线程任务'%n)
if __name__ == '__main__':
t1 = Thread(target=f1,args=(1,))
t2 = Thread(target=f2,args=(2,))
t1.start()
t2.start()
print('主线程')
# 第二种创建方式
class MyThread(Thread):
def __init__(self,name):
# super(MyThread, self).__init__() 和下面super是一样的
super().__init__()
self.name = name
def run(self):
print('hello girl :' + self.name)
if __name__ == '__main__':
t = MyThread('alex')
t.start()
print('主线程结束')
二 . 查看线程的pid
import os
from threading import Thread
def f1(n):
print('1号=>',os.getpid())
print('%s号线程任务' % n)
def f2(n):
print('2号=>',os.getpid())
print('%s号线程任务' % n)
if __name__ == '__main__':
t1 = Thread(target=f1,args=(1,))
t2 = Thread(target=f2,args=(2,))
t1.start()
t2.start()
print('主线程', os.getpid())
print('主线程') # 由于这些线程都是在一个进程中的,所以pid一致
三 . 验证线程之间的数据共享
import time
from threading import Thread
num = 100
def f1(n):
global num
num = 3
time.sleep(1)
print('子线程的num', num) # 子线程的num 3
if __name__ == '__main__':
thread = Thread(target=f1,args=(1,))
thread.start()
thread.join() # 等待thread执行完在执行下面的代码
print('主线程的num', num) # 主线程的num 3
四. 多进程与多线程的效率对比
import time
from threading import Thread
from multiprocessing import Process
def f1():
# io密集型
# time.sleep(1) # 计算型:
n = 10
for i in range(10000000):
n = n + i
if __name__ == '__main__':
#查看一下20个线程执行20个任务的执行时间
t_s_time = time.time()
t_list = []
for i in range(5):
t = Thread(target=f1,)
t.start()
t_list.append(t)
[tt.join() for tt in t_list]
t_e_time = time.time()
t_dif_time = t_e_time - t_s_time
#查看一下20个进程执行同样的任务的执行时间
p_s_time = time.time()
p_list = []
for i in range(5):
p = Process(target=f1,)
p.start()
p_list.append(p)
[pp.join() for pp in p_list]
p_e_time = time.time()
p_dif_time = p_e_time - p_s_time
# print('多线程的IO密集型执行时间:',t_dif_time) # 1.0017869472503662 还需要减1秒的time.sleep
# print('多进程的IO密集型执行时间:',p_dif_time) # 1.2237937450408936 也需要减1秒的time.sleep print('多线程的计算密集型执行时间:', t_dif_time) # 3.58754563331604
print('多进程的计算密集型执行时间:', p_dif_time) # 2.1555309295654297
# 从上述代码中的执行效率可以看出来,多线程在执行IO密集型的程序的时候速度非常快,但是执行计算密集型的程序的时候很慢,所以说python这门语言不适合做大数据.
五 . 互斥锁,同步锁
import time
from threading import Lock, Thread
num = 100
def f1(loc):
# 加锁
with loc:
global num
tmp = num
tmp -= 1
time.sleep(0.001)
num = tmp
# 上面的代码相当于 num -= 1
if __name__ == '__main__':
t_loc = Lock()
t_list = []
for i in range(10):
t = Thread(target=f1,args=(t_loc,))
t.start()
t_list.append(t)
[tt.join() for tt in t_list]
print('主线的num',num)
六 . 死锁现象
import time
from threading import Thread,Lock,RLock
def f1(locA,locB):
locA.acquire()
print('f1>>1号抢到了A锁')
time.sleep(1)
locB.acquire()
print('f1>>1号抢到了B锁')
locB.release()
locA.release()
def f2(locA,locB):
locB.acquire()
print('f2>>2号抢到了B锁')
time.sleep(1)
locA.acquire()
print('f2>>2号抢到了A锁')
locA.release()
locB.release()
if __name__ == '__main__':
# locA = locB = Lock() # 不能这么写,这么写相当于这两个是同一把锁
locA = Lock()
locB = Lock()
t1 = Thread(target=f1,args=(locA,locB))
t2 = Thread(target=f2,args=(locA,locB))
t1.start()
t2.start()
# 上面的代码表示f1 先抢到了A锁,同时f2 抢到了B锁,一秒后f1想去想B锁,同时f2想去抢A锁,
# 由于锁需要先放开才能继续抢,导致了死锁现象
七.递归锁
import time
from threading import Thread, Lock, RLock
def f1(locA, locB):
locA.acquire()
print('f1>>1号抢到了A锁')
time.sleep(1)
locB.acquire()
print('f1>>1号抢到了B锁')
locB.release()
locA.release()
def f2(locA, locB):
locB.acquire()
print('f2>>2号抢到了B锁')
locA.acquire()
time.sleep(1)
print('f2>>2号抢到了A锁')
locA.release()
locB.release()
if __name__ == '__main__':
locA = locB = RLock() #递归锁,维护一个计数器,acquire一次就加1,release就减1 , acquire等于0的时候才可以抢
t1 = Thread(target=f1, args=(locA, locB))
t2 = Thread(target=f2, args=(locA, locB))
t1.start()
t2.start()
# 递归锁解决了死锁现象,会让代码继续执行.
八. 守护线程
守护线程会等到所有的非守护线程运行结束后才结束
import time
from threading import Thread
from multiprocessing import Process #守护进程:主进程代码执行运行结束,守护进程随之结束 #守护线程:守护线程会等待所有非守护线程运行结束才结束 def f1():
time.sleep(2)
print('1号线程')
def f2():
time.sleep(3)
print('2号线程')
if __name__ == '__main__':
t1 = Thread(target=f1,)
t2 = Thread(target=f2,)
# t1.daemon = True # 1号进程 和 2 号进程都会打印
t2.daemon = True # 不会打印2号进程
t1.start()
t2.start()
print('主线程结束')
# 与进程对比
p1 = Process(target=f1, )
p2 = Process(target=f2, )
p1.daemon = True # 只会打印 2号进程
p2.daemon = True # 只会打印1号进程
p1.start()
p2.start()
print('主进程结束')
九 . GIL锁的解释
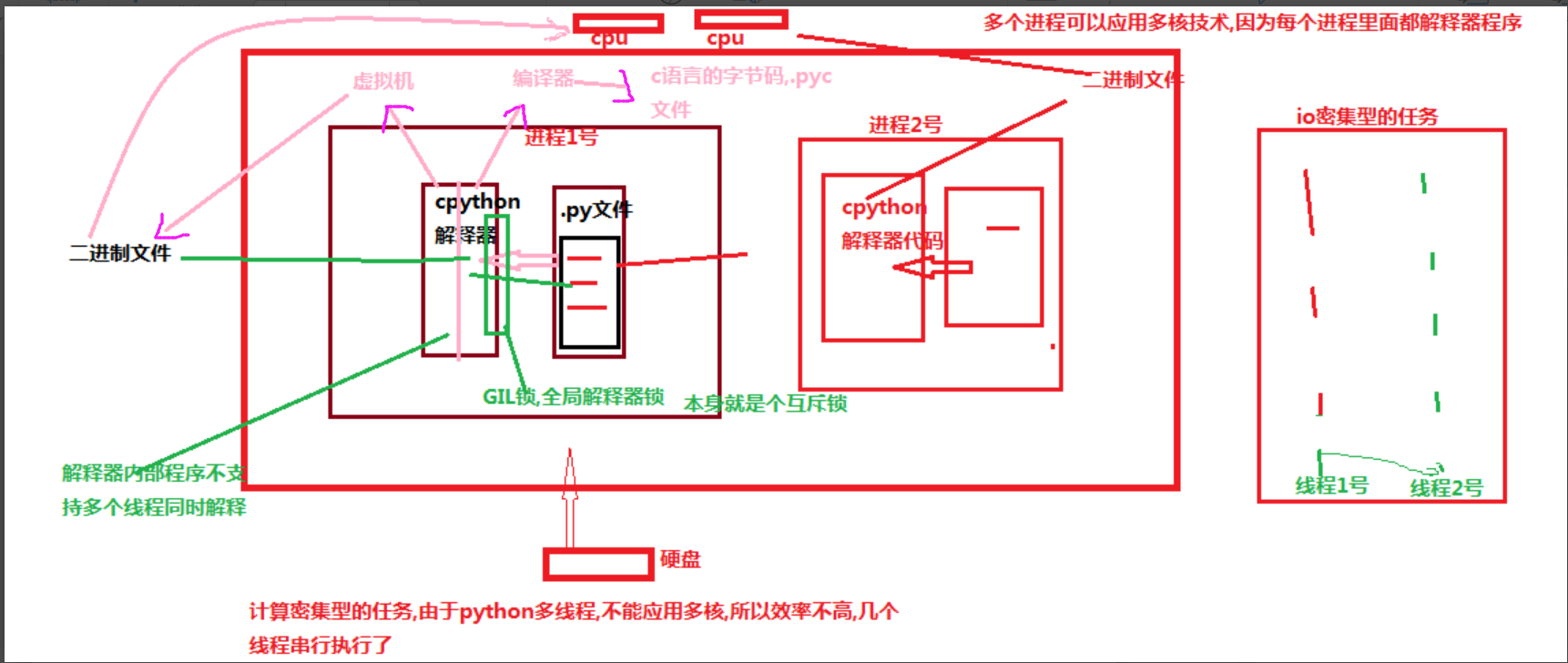
python之路--关于线程的一些方法的更多相关文章
- python之路: 线程、进程和协程
进程和线程 既然看到这一章,那么你肯定知道现在的系统都是支持“多任务”的操作,比如: Mac OS X,UNIX,Linux,Windows等. 多任务:简单地说就是同时运行多个任务.譬如:你可以一边 ...
- python之路之线程,进程,协程2
一.线程 1.创建线程 2.主线程是否等待子线程 t.setDaemon(Ture/False):默认是false,等待子线程完成,ture,表示不等待子线程结束 3.主线程等待,子线程执行 join ...
- python 收录集中实现线程池的方法
概念: 什么是线程池? 诸如web服务器.数据库服务器.文件服务器和邮件服务器等许多服务器应用都面向处理来自某些远程来源的大量短小的任务.构建服务器应用程序的一个过于简单的模型是:每当一个请求到达就创 ...
- PYTHON之路,线程
关于多任务的理解, 代码要执行,首先得变成机器认识的东西执行,那么需要解释器.那么执行按道理,一段程序在这里就具体来说一段代码的执行吧,我们知道代码的执行是从上至下按顺序执行,那么这里有条件分支结构, ...
- Python之路,Day9 - 线程、进程、协程和IO多路复用
参考博客: 线程.进程.协程: http://www.cnblogs.com/wupeiqi/articles/5040827.html http://www.cnblogs.com/alex3714 ...
- 百万年薪python之路 -- 面向对象之所有属性及方法
1.私有成员公有成员 1.1 类的私有属性 # class A: # # name = '周道镕' # __name = 'zdr' # 私有类的属性 # # def func(self): # pr ...
- python之路之线程,进程,协程
一.线程和进程概述 1.python线程的Event 2.python线程其他和队列以及生产者消费者 3. 使用multprocessing创建进程 4.进程间数据共享方式——sharedmeory( ...
- Python之路:线程池
版本一 #!/usr/bin/env python # --*--coding:utf-8 --*-- import Queue import threading class ThreadPool( ...
- Python之路(第四十六篇)多种方法实现python线程池(threadpool模块\multiprocessing.dummy模块\concurrent.futures模块)
一.线程池 很久(python2.6)之前python没有官方的线程池模块,只有第三方的threadpool模块, 之后再python2.6加入了multiprocessing.dummy 作为可以使 ...
随机推荐
- RandomAccess
在List集合中,我们经常会用到ArrayList以及LinkedList集合,但是通过查看源码,就会发现ArrayList实现RandomAccess接口,但是RandomAccess接口里面是空的 ...
- mysql创建索引的原则
在mysql中使用索引的原则有以下几点: 1. 对于查询频率高的字段创建索引: 2. 对排序.分组.联合查询频率高的字段创建索引: 3. 索引的数目不宜太多 原因:a.每创建一个索引都会占用相应的物理 ...
- Python:Day25 成员修饰符、特殊成员、反射、单例
一.成员修饰符 共有成员 私有成员,__字段名,__方法 - 无法直接访问,只能间接访问 class Foo: def __init__(self,name,age): self.name = nam ...
- 18.JAVA经典编程题(50题及答案)
用oop做一个进销存系统:1.货物对象属性:编号(唯一),名称,单价,类别,厂家,厂家地址,厂家联系方式,库存,最后进货时间2.功能:登录,入库,出库,库存查询,操作记录查询3.功能描述:登录:管理员 ...
- Ubuntu16.04之Solr7.7.1环境搭建
Solr的版本一直都在变化(比如之前我在博客园写的关于Linux安装solr,那个solr为7.6版本,此时已经不在了).大家可以去这个地址下载对应的版本:http://mirror.bit.edu. ...
- 2018-2019-3《Java程序设计》第二周学习总结
学号20175329 2018-2019-3<Java程序设计>第二周学习总结 教材学习内容总结 第二三章与我们所学习的C语言有很多的相似点,在这里我想主要就以我所学习的效果来讨 ...
- Java多线程(六)——线程让步
一.yield()介绍 yield()的作用是让步.它能让当前线程由“运行状态”进入到“就绪状态”,从而让其它具有相同优先级的等待线程获取执行权:但是,并不能保证在当前线程调用yield()之后,其它 ...
- python魔法方法、构造函数、序列与映射、迭代器、生成器
在Python中,所有以__双下划线包起来的方法,都统称为"魔术方法".比如我们接触最多的__init__,魔法方法也就是具有特殊功能的方法. 构造函数 构造函数不同于普通方法,将 ...
- mac sourcetree push分支选中所有tag的时候报错
错误信息: ....... ! [rejected] 573_0811_stable -> 573_0811_stable (already exists)updating local trac ...
- 十分钟学会Java8:lambda表达式和Stream API
Java8 的新特性:Lambda表达式.强大的 Stream API.全新时间日期 API.ConcurrentHashMap.MetaSpace.总得来说,Java8 的新特性使 Java 的运行 ...