python爬虫解析库学习
一、xpath库使用:
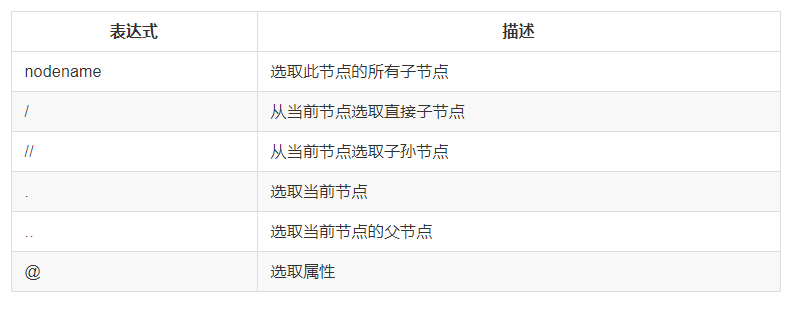
1、基本规则:
2、将文件转为HTML对象:
html = etree.parse('./test.html', etree.HTMLParser())
result = etree.tostring(html)
print(result.decode('utf-8'))
3、属性多值匹配:
//a[contains(@class,'li')]
4、多属性匹配:
//a[@class="a" and @font="red"]
5、按序选择:

二、beautifulsoup库学习:
1、基本初始化:
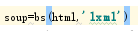
将HTML字符串用lxml格式来解析,并补全标签,创建html处理对象。
2、获取信息:
(1)获取title的name属性:
soup.title.name
(2)获取多属性:
(3)children返回孩子节点:
(4)find_all函数:查找所有的节点。
·通过节点名称来查找:
soup.find_all(name='li')
·通过属性名来查找:
soup.find_all(attrs={'id':'link1'})
··通过文本来查找:
soup.find_all(text='') 用来匹配网页节点中的文本内容。
3、css选择器:
.select() 方法。参数内容和jquery相似。
返回内容为列表,类型是tag类型。
三、pyquery库:
1、初始化:
·通过HTML字符串
·通过url
·通过文件名。需要指出文件名。
2、常用函数:
(1)find() 方法
(2)children()查找子结点
(3)查找父节点: parent()
(4)查找祖先节点:
parents()
(5)兄弟节点:
siblings() 方法
(6)对查找结果进行遍历:
.items()返回每一个节点。
(7) 获取节点信息:
·获取属性:
.attrs(‘属性名’)
python爬虫解析库学习的更多相关文章
- Python 爬虫 解析库的使用 --- XPath
一.使用XPath XPath ,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言.它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索. 所 ...
- Python 爬虫 解析库的使用 --- Beautiful Soup
知道了正则表达式的相关用法,但是一旦正则表达式写的有问题,得到的可能就不是我们想要的结果了.而且对于一个网页来说,都有一定的特殊结构和层级关系,而且有很多节点都有id或class来做区分,所以借助它们 ...
- python爬虫解析库之Beautifulsoup模块
一 介绍 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会 ...
- python爬虫解析库之re模块
re模块 一:什么是正则? 正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法.或者说:正则就是用来描述一类事物的规则.(在Python中)它内嵌在Python中, ...
- python爬虫---selenium库的用法
python爬虫---selenium库的用法 selenium是一个自动化测试工具,支持Firefox,Chrome等众多浏览器 在爬虫中的应用主要是用来解决JS渲染的问题. 1.使用前需要安装这个 ...
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python网页解析库:用requests-html爬取网页
Python网页解析库:用requests-html爬取网页 1. 开始 Python 中可以进行网页解析的库有很多,常见的有 BeautifulSoup 和 lxml 等.在网上玩爬虫的文章通常都是 ...
- Python爬虫Urllib库的基本使用
Python爬虫Urllib库的基本使用 深入理解urllib.urllib2及requests 请访问: http://www.mamicode.com/info-detail-1224080.h ...
- Python爬虫—requests库get和post方法使用
目录 Python爬虫-requests库get和post方法使用 1. 安装requests库 2.requests.get()方法使用 3.requests.post()方法使用-构造formda ...
随机推荐
- IDEA将项目上传至码云/GitHub托管
怎么将本地的项目放到码云或者GitHub去托管了?(以码云为例) 一.创建远程项目 第一步:点击创建项目 第二步:填写项目相关信息 第三步:复制远程的项目地址,注意:此处码云官方已经给出上传项目方法, ...
- vue 动态插入组件
HTML代码: <div id="app"> <p>{{ message }}</p> <button @click="add( ...
- @Param注解
关于mybatis的@Param注解和参数 引用 https://www.cnblogs.com/whisper527/p/6568028.html 薇飘意 1,使用@Param注解 当以下面的方式进 ...
- 关于controller的书写
private Logger log = LoggerFactory.getLogger(ReportFormController.class); // 读取配置文件 ResourceBundle r ...
- MySQL系列:视图基本操作(3)
1. 视图简介 1.1 视图定义 视图是一种虚拟的表,是从数据库中一个或多个表中导出来的表. 视图可以从已存在的视图的基础上定义. 数据库中只存放视图的定义,并没有存放视图中的数据,数据存放在原来的表 ...
- JavaScript之Json的使用
Json字符串转JavaScript对象 <html> <body> <h3>通过 JSON 字符串来创建对象</h3> <p> First ...
- Learning to Rank for IR的评价指标—MAP,NDCG,MRR
转自: https://www.cnblogs.com/eyeszjwang/articles/2368087.html MAP(Mean Average Precision):单个主题的平均准确率是 ...
- 关于SQL查询语句中的LIKE模糊查询的解释
LIKE语句的语法格式为: select * from 表名 where 字段名 like 对应值(字符串) 注:主要是针对字符型字段的,它的作用是在一个字符型字段列中检索包含对应字符串的. 下面列举 ...
- Python——Radiobutton,Checkbutton参数说明
anchor : 文本位置: background(bg) : 背景色: foreground(fg) :前景色: borderwidth : 边框宽度: width : 组件的宽度: hei ...
- Linux 学习 (二) 文件处理命令
Linux达人养成计划 I 学习笔记 ls [选项] [文件或目录] -a: 显示所有文件,包括隐藏文件 -l: 显示详细信息 -d: 查看目录属性 -h: 人性化显示文件大小 -i: 显示inode ...