SQL Server 深入解析索引存储(非聚集索引)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/非聚集索引
概述
非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点:
- 基础表的数据行不按非聚集键的顺序排序和存储。
- 非聚集索引的叶层是由索引页而不是由数据页组成。
既可以使用聚集索引来为表或视图定义非聚集索引,也可以根据堆来定义非聚集索引。非聚集索引中的每个索引行都包含非聚集键值和行定位符。此定位符指向聚集索引或堆中包含该键值的数据行。
非聚集索引行中的行定位器或是指向行的指针,或是行的聚集索引键,如下所述:
- 如果表是堆(意味着该表没有聚集索引),则行定位器是指向行的指针。该指针由文件标识符 (ID)、页码和页上的行数生成。整个指针称为行 ID
(RID)。 - 如果表有聚集索引或索引视图上有聚集索引,则行定位器是行的聚集索引键。如果聚集索引不是唯一的索引,SQL Server
将添加在内部生成的值(称为唯一值)以使所有重复键唯一。此四字节的值对于用户不可见。仅当需要使聚集键唯一以用于非聚集索引中时,才添加该值。SQL
Server 通过使用存储在非聚集索引的叶行内的聚集索引键搜索聚集索引来检索数据行。
对于索引使用的每个分区,非聚集索引在 index_id >0 的 sys.partitions
中都有对应的一行。默认情况下,一个非聚集索引有单个分区。如果一个非聚集索引有多个分区,则每个分区都有一个包含该特定分区的索引行的 B
树结构。例如,如果一个非聚集索引有四个分区,那么就有四个 B 树结构,每个分区中一个。
根据非聚集索引中数据类型的不同,每个非聚集索引结构会有一个或多个分配单元,在其中存储和管理特定分区的数据。每个非聚集索引至少有一个针对每个分区的
IN_ROW_DATA 分配单元(存储索引 B 树页)。如果非聚集索引包含大型对象 (LOB) 列,则还有一个针对每个分区的 LOB_DATA
分配单元。此外,如果非聚集索引包含的可变长度列超过 8,060 字节行大小限制,则还有一个针对每个分区的 ROW_OVERFLOW_DATA
分配单元。有关分配单元的详细信息,请参阅表组织和索引组织。B 树的页集合由
sys.system_internals_allocation_units 系统视图中的 root_page 指针定位。
要很好的理解这篇文章的内容之前需要先阅读我前面写的上中部分的两篇文章:
正文
非聚集索引结构

生成测试数据
CREATE TABLE Torder
(ID INT IDENTITY(1,1) NOT NULL,
NAME CHAR(100) NOT NULL,
pro VARCHAR(8000) NULL,
Statu INT NOT NULL,
IDATE DATETIME DEFAULT(GETDATE())
)
GO
---插入1000条测试数据
DECLARE @ID INT=1
WHILE(@ID<=1000)
BEGIN
INSERT INTO Torder(NAME,pro,Statu)VALUES('商品'+CONVERT(CHAR(20),@ID),REPLICATE(1,8000),LEFT(@ID,1))
SET @ID=@ID+1
END
GO
---创建非聚集索引
CREATE INDEX IX_Torder ON Torder
(NAME,Statu
)
INCLUDE(IDATE) SELECT DISTINCT so.name, so.object_id,sp.index_id,internals.type_desc,internals.total_pages, internals.used_pages, internals.data_pages,first_iam_page, first_page, root_page
FROM sys.objects so
INNER JOIN sys.partitions sp ON so.object_id = sp.object_id
INNER JOIN sys.allocation_units sa ON sa.container_id = sp.hobt_id
INNER JOIN sys.system_internals_allocation_units internals ON internals.container_id = sa.container_id
WHERE so.object_id = object_id('Torder')

由于创建的表只有非聚集索引,所以整个表的页存储中有三部分数据:堆页面、溢出页面、索引页面;
堆中共有20个数据页和一个IAM页;
溢出单元有1001个页面包括一个IAM页;
索引中共有20个页其中18个数据页一个ROOT页和一个IAM页.
一个堆页对应多个溢出页,因为Pro有8000个字节所以一行占一页,而表的其它字段只有116个字节一个堆页可以存50条记录,所以并不是一个溢出页就唯一对应一个堆页
分析页的存储信息
---开启跟踪标志
DBCC TRACEON(3604,2588)
--DBCC TRACEOFF(3604,2588)
---获取对象的数据页,结构:数据库、对象、显示
DBCC IND(Ixdata,Torder,-1)
上一章中已经讲过了堆页面和溢出页面,所以现在就讲非聚集索引页
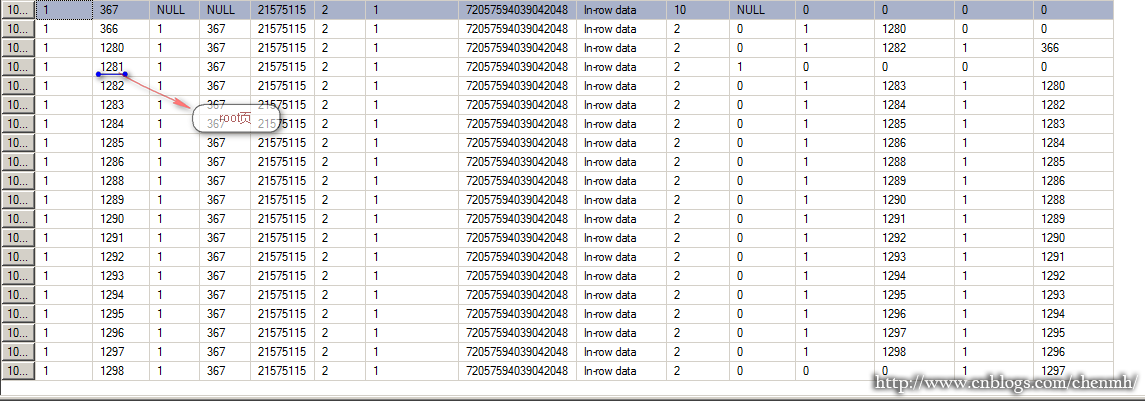
看过前面的文章应该一眼就能看出1281页是ROOT页,现在就分析1281页
分析非聚集索引根页
DBCC page(Ixdata,1,1281,3)

现在来分析行定位指针是怎样的:0x6801000001002F00
除去开头的16进制标示,剩下总共8个字节,从右往左其中行号2个字节,文件标示ID2个字节,剩下的4个字节就是页号了,所以
行号(002f)=47
文件页(0001)=1
页号(00000168)=360页
现在查看360页的信息
DBCC page(Ixdata,1,360,3)

47行的记录正好是“商品150”
分析非聚集索引索引页
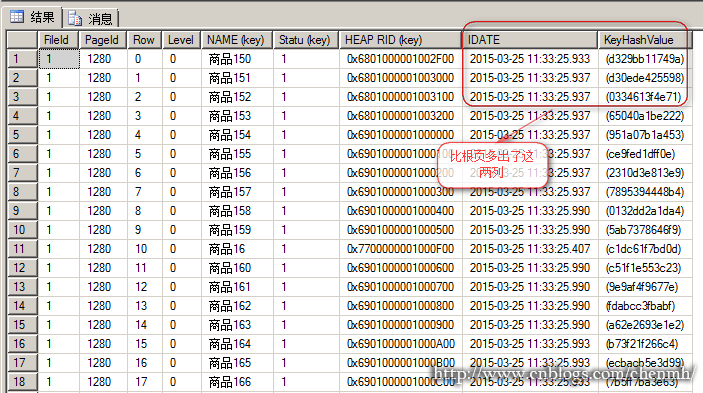
通过对比会发现索引页比根页多出了索引包含列值和键的哈希值,这个里面的keyhashvalue应该是NAME和statu字段的值通过某种方法算出来的,这里只是猜测通过平时的查询你会产生这样的猜测。
测试简单的查询
这里的'商品150'和'商品153'都是1280页中的记录,1280页是索引页,其中'商品150'是该页的第一条记录
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
BEGIN TRAN
SELECT [ID]
,[NAME]
,[pro]
,[Statu]
,[IDATE]
FROM [Ixdata].[dbo].[Torder]
WHERE NAME='商品153' --COMMIT 另开一个窗口
SELECT
[request_session_id],
c.[program_name],
DB_NAME(c.[dbid]) AS dbname,
[resource_type],
[request_status],
[request_mode],
[resource_description],OBJECT_NAME(p.[object_id]) AS objectname,
p.[index_id]
FROM sys.[dm_tran_locks] AS a LEFT JOIN sys.[partitions] AS p
ON a.[resource_associated_entity_id]=p.[hobt_id]
LEFT JOIN sys.[sysprocesses] AS c ON a.[request_session_id]=c.[spid]
WHERE c.[dbid]=DB_ID('Ixdata') AND a.[request_session_id]=58 ----要查询申请锁的数据库
ORDER BY [request_session_id],[resource_type]



从上面的查询过程可以知道页面总共读取了三次(索引叶一次堆页一次溢出页一次)。
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
GO
BEGIN TRAN
SELECT
[ID]
,[NAME]
,[pro]
,[Statu]
,[IDATE]
FROM [Ixdata].[dbo].[Torder]
WHERE NAME='商品150'



通过对比查询'商品150'和'商品153'可以看到如果查找的页面的第一条记录,它需要再读取该索引页的前一个页面,如果该索引页是第一页就无需再读除本身的其他索引页了,文章写到后面反过来思考才知道为什么非聚集索引还需要多查找一个页面了。因为非聚集索引是允许存在重复值所以才需要再往前查找,如果前面一个页查找不到则结束,如果前面一个页还没查完会再往前一个页进行查,当然查询商品153的时候就已经判断了前一条记录的键值是不一样的否则也是要再查询前一个页,这也是非聚集索引的一个特殊情况吧!
索引扫描
update Torder
set statu=100
where id=1 SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
GO
BEGIN TRAN
SELECT
[ID]
,[NAME]
,[pro]
,[Statu]
,[IDATE]
FROM [Ixdata].[dbo].[Torder]
WHERE [Statu]=100
该查询总共扫描了18个索引页+1个堆页+1个溢出页.
创建聚集索引
ALTER TABLE dbo.Torder ADD CONSTRAINT
PK_Torder PRIMARY KEY CLUSTERED
(
ID
) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] SELECT DISTINCT so.name, so.object_id,sp.index_id,internals.type_desc,internals.total_pages, internals.used_pages, internals.data_pages,first_iam_page, first_page, root_page
FROM sys.objects so
INNER JOIN sys.partitions sp ON so.object_id = sp.object_id
INNER JOIN sys.allocation_units sa ON sa.container_id = sp.hobt_id
INNER JOIN sys.system_internals_allocation_units internals ON internals.container_id = sa.container_id
WHERE so.object_id = object_id('Torder')

非聚集索引数据页比之前少了一页

由于现在的指针比之前的16进制指针要所占有的字节要少,所以只需要17个页面就可以存下。
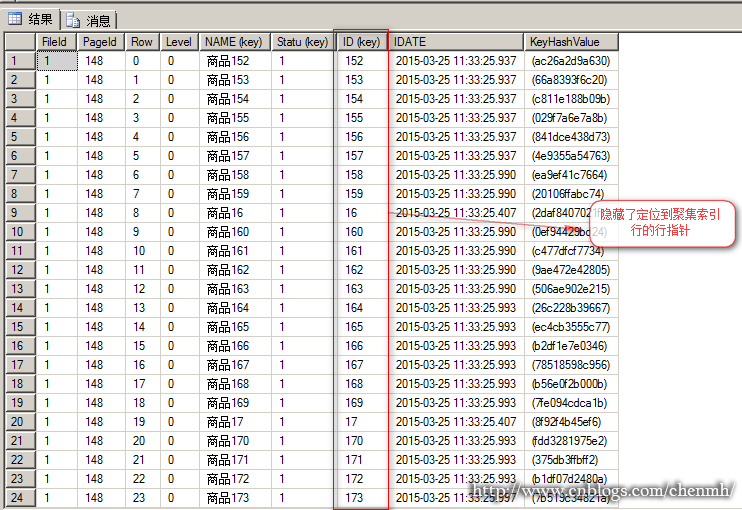
分析索引页148
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
BEGIN TRAN
SELECT [ID]
,[NAME]
,[pro]
,[Statu]
,[IDATE]
FROM [Ixdata].[dbo].[Torder]
WHERE NAME='商品152' 在另一个窗口打开
SELECT
[request_session_id],
c.[program_name],
DB_NAME(c.[dbid]) AS dbname,
[resource_type],
[request_status],
[request_mode],
[resource_description],OBJECT_NAME(p.[object_id]) AS objectname,
p.[index_id]
FROM sys.[dm_tran_locks] AS a LEFT JOIN sys.[partitions] AS p
ON a.[resource_associated_entity_id]=p.[hobt_id]
LEFT JOIN sys.[sysprocesses] AS c ON a.[request_session_id]=c.[spid]
WHERE c.[dbid]=DB_ID('Ixdata') AND a.[request_session_id]=58 ----要查询申请锁的数据库
ORDER BY [request_session_id],[resource_type]
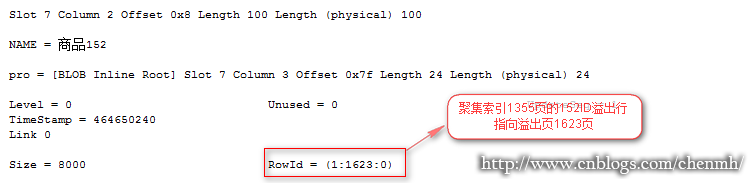


从上面的逻辑读取和查询步骤可以证实前面的猜测,应该是隐藏了一张行定位表。
如果表有聚集索引或索引视图上有聚集索引,则行定位器是行的聚集索引键。如果聚集索引不是唯一的索引,SQL Server 将添加在内部生成的值(称为唯一值)以使所有重复键唯一。此四字节的值对于用户不可见。仅当需要使聚集键唯一以用于非聚集索引中时,才添加该值。SQL Server 通过使用存储在非聚集索引的叶行内的聚集索引键搜索聚集索引来检索数据行。
查看索引统计信息
DBCC SHOW_STATISTICS ("dbo.Torder", IX_Torder);

前面建的包含索引有这三种组合方式,所以组合索引的第二个字段不被用来单独做查找。
总结
非聚集索引和聚集索引不一样,聚集索引索引页的键值指向数据页的具体行;而非聚集索引不存在数据页,非聚集索引的索引页中的记录行指向聚集索引或者堆的具体数据页的数据行然后来获取记录,如果堆或聚集索引还存在溢出的话,从堆或者聚集索引的数据记录还有指向溢出页面的指针。
补充一下在非聚集索引中存在聚集索引与堆的优点,看完上文你会发现非聚集索引的数据页记录的行定位指针分别指向聚集索引或堆的行,但是指向聚集索引的行定位是逻辑值而指向堆的是实际的rid值,逻辑值的好处就是在聚集索引发生分页的情况下,逻辑值不用改变也就无需更新非聚集索引的指针。
花了四天时间终于把这个系列的写完了,重新去理解一遍把以前的一些不理解的知识点给弄明白了,还是收获很多。
如果文章对大家有帮助,希望大家能给个推荐,谢谢!!!
|
备注: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站点所有随笔都是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接,否则保留追究责任的权利。 《欢迎交流讨论》 |
SQL Server 深入解析索引存储(非聚集索引)的更多相关文章
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- SQL Server性能优化(9)聚集索引的存储结构
一.索引的概念和分类 索引的概念大家都知道,日常开发中我们也会使用常见的聚集索引.非聚集索引.但是除了这两者以外,sqlserver中还提供其他的索引,如: a. 唯一索引:不包含重复键的索引,聚集索 ...
- SQL SERVER 索引之聚集索引和非聚集索引的描述
索引是与表或视图关联的磁盘上结构,可以加快从表或视图中检索行的速度. 索引包含由表或视图中的一列或多列生成的键. 这些键存储在一个结构(B 树)中,使 SQL Server 可以快速有效地查找与键值关 ...
- SQL Server索引 - 聚集索引、非聚集索引、非聚集唯一索引 <第八篇>
聚集索引.非聚集索引.非聚集唯一索引 我们都知道建立适当的索引能够提高查询速度,优化查询.先说明一下,无论是聚集索引还是非聚集索引都是B树结构. 聚集索引默认与主键相匹配,在设置主键时,SQL Ser ...
- SQL Server - 索引详细教程 (聚集索引,非聚集索引)
转载自:https://www.cnblogs.com/hyd1213126/p/5828937.html 作者:爱不绝迹 (一)必读:深入浅出理解索引结构 实际上,您可以把索引理解为一种特殊的目录. ...
- 浅谈sql server聚集索引与非聚集索引
今天同事的服务程序在执行批量插入数据操作时,会超时失败,代码debug了几遍一点问题都没有,SQL单条插入也可以正常录入数据,调试了一上午还是很迷茫,场面一度很尴尬,最后还是发现了问题的根本,原来是另 ...
- SQL Server的聚集索引和非聚集索引
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引.簇集索引)和非聚集索引(nonclustered index,也称非聚类索引.非簇集索引)…… (一) ...
- SQL存储原理及聚集索引、非聚集索引、唯一索引、主键约束的关系(补)
索引类型 1. 唯一索引:唯一索引不允许两行具有相同的索引值 2. 主键索引:为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型.主键索引要求主键中的 ...
- SQL Server中的联合主键、聚集索引、非聚集索引、mysql 联合索引
我们都知道在一个表中当需要2列以上才能确定记录的唯一性的时候,就需要用到联合主键,当建立联合主键以后,在查询数据的时候性能就会有很大的提升,不过并不是对联合主键的任何列单独查询的时候性能都会提升,但我 ...
随机推荐
- 求数组中两数之和等于target的两个数的下标
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标. 你可以假设每种输入只会对应一个答案.但是,你不能重复利用这个数组中同样的元 ...
- 【算法】BM算法
目录 BM算法 一. 字符串比较的分析 二.BM算法的思想 三.算法实现 BM算法 @ 一. 字符串比较的分析 如果要判定长度为\(n\)两个字符串相等,比较中要进行\(n\)比较,但是如果要判定两个 ...
- Vue源码学习(一)———数据双向绑定 Observer
从最简单的案例,来学习Vue.js源码. <body> <div id='app'> <input type="text" v-model=" ...
- 泛型List去除重复指定字段
泛型List去除重复指定字段ID var list=listTemp.Distinct(new IDComparer ()).ToList(); 重写比较的方法: public class IDCom ...
- JavaSE基础知识(7)—常用类
一.包装类 1.理解 java为八大基本数据类型一一对应提供了引用类型,方便使用里面的属性和方法 2.包装类型 byte——>Byteshort——>Shortint——>Integ ...
- PCB设计基本流程
[PCB设计基本流程]1.准备原理图和网络表2.电路板规划3.参数设置4.导入网标5.布局6.布线7.规则检查与手工调整8.输出文件 [具体步骤]1.在原理图环境下:Tool——>Footpri ...
- Asp.net core 向Consul 注册服务
Consul服务发现的使用方法:1. 在每台电脑上都以Client Mode的方式运行一个Consul代理, 这个代理只负责与Consul Cluster高效地交换最新注册信息(不参与Leader的选 ...
- c# maiform父窗体改变动态的gridew 奇偶行变色的快捷方法
无需在每个usercontrol里边单个指定控件内gridview 隔行换色.只需要在主窗体内改成统一就好了 做到这点要明白.gridcontrol 是usercontrol 的子控件 , grid ...
- java之数据库相关
这篇还是在回顾知识.主要是关于java连接Sqlserver2012数据库的一些方式记录,以便以后查询. 十一之内复习完这些知识就可以新学Hibernate啦(*^▽^*) 1.普通方式 注意,在连接 ...
- luogu P1064|| 01背包||金明的预算
题目描述如下 金明今天很开心,家里购置的新房就要领钥匙了,新房里有一间金明自己专用的很宽敞的房间.更让他高兴的是,妈妈昨天对他说:“你的房间需要购买哪些物品,怎么布置,你说了算,只要不超过 NNN 元 ...