洗礼灵魂,修炼python(90)-- 知识拾遗篇 —— 协程
协程
1.定义
协程,顾名思义,程序协商着运行,并非像线程那样争抢着运行。协程又叫微线程,一种用户态轻量级线程。协程就是一个单线程(一个脚本运行的都是单线程)
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。
协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置,看到这



是的,就是生成器,后面再实例更会充分的利用到生成器,但注意:生成器 != 协程
2.特性
优点:
- 无需线程上下文切换的开销
- 无需原子操作锁定及同步的开销
- 方便切换控制流,简化编程模型
- 高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
注:比如修改一个数据的整个操作过程下来只有两个结果,要嘛已修改,要嘛未修改,中途出现任何错误都会回滚到操作前的状态,这种操作模式就叫原子操作,"原子操作(atomic operation)是不需要synchronized",不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程)。原子操作可以是一个步骤,也可以是多个操作步骤,但是其顺序是不可以被打乱,或者切割掉只执行部分。视作整体是原子性的核心。
缺点:
- 无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。
- 进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序
3.实例
1)用生成器实现伪协程:
在这之前,相信很多朋友已经把生成器是什么忘了吧,这里简单复习一下。
创建生成器有两个放法:
A:使用列表生成器:

B:使用yield创建生成器:

访问生成器数据,使用next()或者__next__()方法:
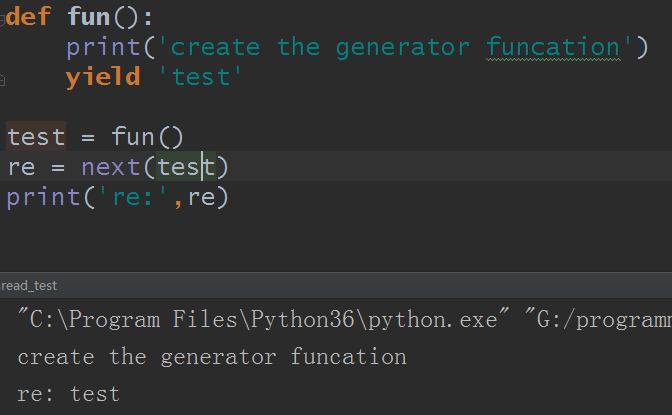
好的,既然说到这里,就说下,yield可以暂存数据并转发:
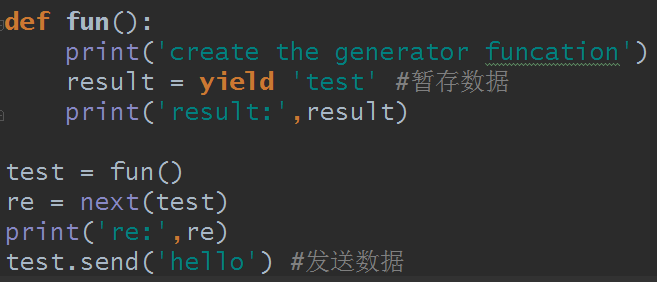
传是传入了,但结果却报错:

为什么报错呢?首先要说一个知识点,使用next()和send()方法都会取出一个数据,不同的是send即发送数据又取出上一数据,并且如果要发送数据必须是第二次发送,如果第一次就是用send,必须写为send(None)才行,不然报错。next(obj) = obj.send(None).
因为yield是暂存数据,每次next()时将会在结束时的此处阻塞住,下一次又从这里开始,而发送完,send取数据发现已经结束了,数据已经没了,所以修改报错,
那么稍作修改得:

完美!
好的,进入正题了,有了上面的现钞,现在现卖应该没问题了:
依然是前面的生产者消费者模型
import time
import queue
def consumer(name):
print("--->starting eating baozi...")
while True:
new_baozi = yield
print("[%s] is eating baozi %s" % (name,new_baozi))
#time.sleep(1)
def producer():
r = con.__next__()
r = con2.__next__()
n = 0
while n < 5:
n +=1
con.send(n)
con2.send(n)
print("\033[32;1m[producer]\033[0m is making baozi %s" %n )
if __name__ == '__main__':
con = consumer("c1")
con2 = consumer("c2")
p = producer()
运行结果:

首先我们知道使用yield创建了一个生成器对象,然后每次使用时利用new_baozi做一个中转站来缓存数据。这就是实现协程效果了对吧?
前面我提了一句,yield下是伪协程,那么什么是真正的协程呢?
需要具备以下条件:
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 一个协程遇到IO操作自动切换到其它协程
- 用户程序里自己保存多个控制流的上下文栈
2)gevent协程
首先其实python提供了一个标准库Greenlet就是用来搞协程的
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
from greenlet import greenlet
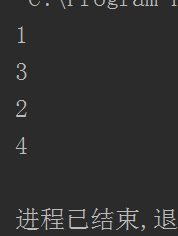
def test1():
print(1)
gr2.switch() #switch方法作为协程切换
print(2)
gr2.switch()
def test2():
print(3)
gr1.switch()
print(4)
gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch()
运行结果:
但是效果不好,无法满足IO阻塞,所以一般情况都用第三方库gevent来实现协程:
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import gevent,time
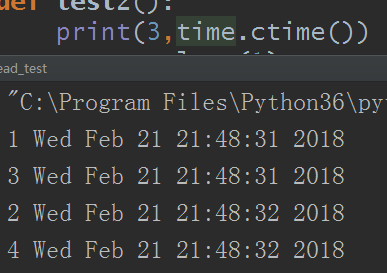
def test1():
print(1,time.ctime())
gevent.sleep(1) #模拟IO阻塞,注意此时的sleep不能和time模块下的sleep相提并论
print(2,time.ctime())
def test2():
print(3,time.ctime())
gevent.sleep(1)
print(4,time.ctime())
gevent.joinall([
gevent.spawn(test1), #激活协程对象
gevent.spawn(test2)
])
运行结果:
那么如果函数带有参数怎么搞呢?
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import gevent
def test(name,age):
print('name:',name)
gevent.sleep(1) #模拟IO阻塞
print('age:',age)
gevent.joinall([
gevent.spawn(test,'yang',21), #激活协程对象
gevent.spawn(test,'ling',22)
])
运行结果:

如果你对这个协程的速度觉得不理想,可以添加下面这一段,其他不变:
这个patch_all()相当于一个检测机制,发现IO阻塞就立即切换,不需等待什么。这样可以节省一些时间
好的,协程解析完毕。
洗礼灵魂,修炼python(90)-- 知识拾遗篇 —— 协程的更多相关文章
- Python PEP 492 中文翻译——协程与async/await语法
原文标题:PEP 0492 -- Coroutines with async and await syntax 原文链接:https://www.python.org/dev/peps/pep-049 ...
- python单线程,多线程和协程速度对比
在某些应用场景下,想要提高python的并发能力,可以使用多线程,或者协程.比如网络爬虫,数据库操作等一些IO密集型的操作.下面对比python单线程,多线程和协程在网络爬虫场景下的速度. 一,单线程 ...
- Python 线程和进程和协程总结
Python 线程和进程和协程总结 线程和进程和协程 进程 进程是程序执行时的一个实例,是担当分配系统资源(CPU时间.内存等)的基本单位: 进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其 ...
- python并发编程之gevent协程(四)
协程的含义就不再提,在py2和py3的早期版本中,python协程的主流实现方法是使用gevent模块.由于协程对于操作系统是无感知的,所以其切换需要程序员自己去完成. 系列文章 python并发编程 ...
- python并发编程之asyncio协程(三)
协程实现了在单线程下的并发,每个协程共享线程的几乎所有的资源,除了协程自己私有的上下文栈:协程的切换属于程序级别的切换,对于操作系统来说是无感知的,因此切换速度更快.开销更小.效率更高,在有多IO操作 ...
- Python 多线程、进程、协程上手体验
浅谈 Python 多线程.进程.协程上手体验 前言:浅谈 Python 很多人都认为 Python 的多线程是垃圾(GIL 说这锅甩不掉啊~):本章节主要给你体验下 Python 的两个库 Thre ...
- Python的异步编程[0] -> 协程[0] -> 协程和 async / await
协程 / Coroutine 目录 生产者消费者模型 从生成器到异步协程– async/await 协程是在一个线程执行过程中可以在一个子程序的预定或者随机位置中断,然后转而执行别的子程序,在适当的时 ...
- python并发编程之线程/协程
python并发编程之线程/协程 part 4: 异步阻塞例子与生产者消费者模型 同步阻塞 调用函数必须等待结果\cpu没工作input sleep recv accept connect get 同 ...
- 洗礼灵魂,修炼python(85)-- 知识拾遗篇 —— 深度剖析让人幽怨的编码
编码 这篇博文的主题是,编码问题,老生常谈的问题了对吧?从我这一套的文章来看,前面已经提到好多次编码问题了,的确这个确实很重要,这可是难道了很多能人异士的,当你以为你学懂了,在研究爬虫时你发现你错了, ...
随机推荐
- java设计模式之——工厂模式
对于java的设计模式,我还是第一次认认真真的总结,以前用的时候都不曾留意细节,现在回头再看只知道该怎么设计,却忘记当时为嘛要用它了, 所以这次就做一个demo来再次复习总结一下,希望从中能学到新体悟 ...
- Spring cloud的Maven插件(一):repackage目标
简介 Spring Boot Maven Plugin插件提供spring boot在maven中的支持.允许你打包可运行的jar包或war包. 插件提供了几个maven目标和Spring Boot ...
- python datetime模块详解
datetime是python当中比较常用的时间模块,用于获取时间,时间类型之间转化等,下文介绍两个实用类. 一.datetime.datetime类: datetime.datetime.now() ...
- 翻译:CONCURRENT INSERTS(已提交到MariaDB官方手册)
本文为mariadb官方手册:CONCURRENT INSERTS的译文. 原文:https://mariadb.com/kb/en/concurrent-inserts/我提交到MariaDB官方手 ...
- Go Web:RESTful web service示例
RESTful架构的简介 web服务的架构模式主要有2种:SOAP和REST.SOAP和REST都回答了同一个问题:如何访问web服务. SOAP风格的程序是功能驱动的,要借助xml来传递数据,明确表 ...
- OJ:访问 const 成员函数问题
Description 补足程序使得其输出结果是: 40 #include <iostream> #include <string> using namespace std; ...
- python模块之random
python的随机数模块为random模块,可以产生随机的整数或浮点数.但是这是伪随机数,python解释器会维护一些种子数,然后根据算法算出随机数.linux维护了一个熵池,这个熵池收集噪音的信息, ...
- 利用aiohttp制作异步爬虫
asyncio可以实现单线程并发IO操作,是Python中常用的异步处理模块.关于asyncio模块的介绍,笔者会在后续的文章中加以介绍,本文将会讲述一个基于asyncio实现的HTTP框架--a ...
- [转]Database Transactions in Laravel
本文转自:https://fideloper.com/laravel-database-transactions Laravel's documentation on Database Transac ...
- 好好耕耘 redis和memcached的区别
观点一: 1.Redis和Memcache都是将数据存放在内存中,都是内存数据库.不过memcache还可用于缓存其他东西,例如图片.视频等等: 2.Redis不仅仅支持简单的k/v类型的数据,同时还 ...