SQL Server 执行计划解析
SELECT <所需列> --列太多,不一一列出
FROM study1
INNER JOIN series1
ON (study1.study_uid_id = series1.study_uid_id) --连接条件1
INNER JOIN image1 image1
ON (series1.series_uid_id = image1.series_uid_id) --连接条件2
where ((study1.user_group &8) != 0) --过滤条件1
and (series1.modality) not in ('PR', 'KO', 'SR', 'AU') --过滤条件2
and study1.study_uid ='xxx' --过滤条件3
order by <排序列>; --列太多,不一一列出
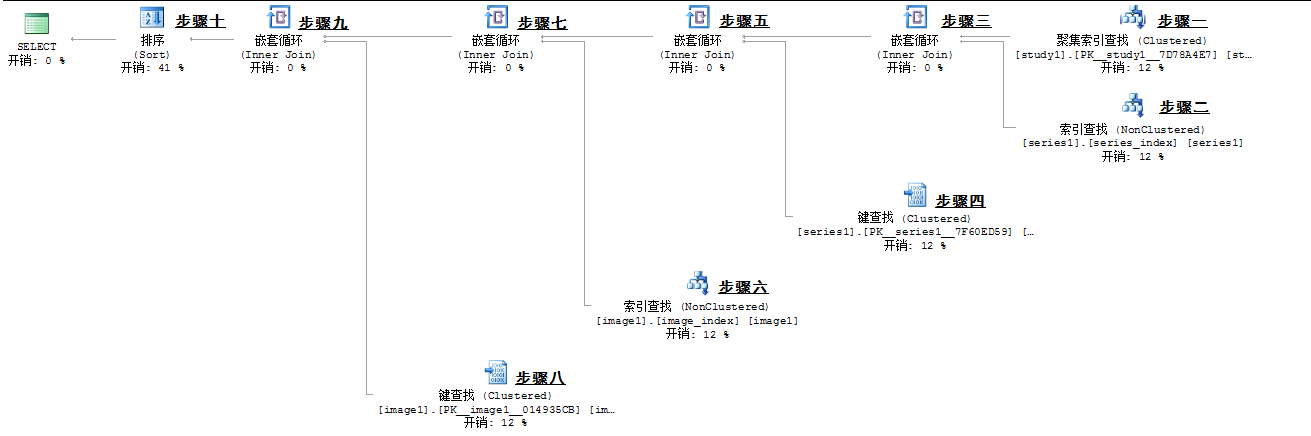
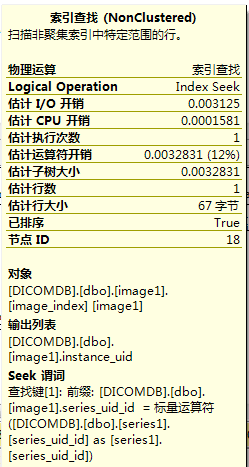
- 物理运算和逻辑运算:
逻辑运算表明了本步骤执行计划做了什么,而物理运算表明用哪种方式做的。一般物理运算和逻辑运算名字相同,也有例外如Aggregate这种逻辑运算就包含流聚合和哈希匹配两种物理实现方式。
- 估计行数
根据统计信息估算出的中间表或结果集的行数。与最终的运行结果记录数比较可以推断出统计信息是否失真。
- 谓词(或seek 谓词,有时两者一起出现)
表示SQL语句的过滤条件或内部过滤条件。
- 估计子树大小(即subtree cost和total subtree cost)
这是最为直观的判断执行计划是否优良的指标,相当于Oracle的cost,默认情况下totalsubtreecost超过5时SQL Server使用并行执行语句。此外也可以查看每个node的subtreecost来判断哪个步骤消耗最多。
SQL Server 执行计划解析的更多相关文章
- SQL Server 执行计划缓存
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/内存池/缓冲区 概述 了解执行计划对数据库性能分析很重要,其中涉及到了语句性能分析与存储,这也是写这篇文章的目的,在了解执行计划之 ...
- sql server 执行计划(execution plan)介绍
大纲:目的介绍sql server 中执行计划的大致使用,当遇到查询性能瓶颈时,可以发挥用处,而且带有比较详细的学习文档和计划,阅读者可以按照我计划进行,从而达到对执行计划一个比较系统的学习. 什么是 ...
- SQL Server 执行计划中的扫描方式举例说明
SQL Server 执行计划中的扫描方式举例说明 原文地址:http://www.cnblogs.com/zihunqingxin/p/3201155.html 1.执行计划使用方式 选中需要执行的 ...
- SQL Server执行计划那些事儿(3)——书签查找
接下来的文章是记录自己曾经的盲点,同时也透漏了自己的发展历程(可能发展也算不上,只能说是瞎混).当然,一些盲点也在工作和探究过程中慢慢有些眉目,现在也愿意发扬博客园的奉献精神,拿出来和大家分享一下. ...
- SQL Server执行计划那些事儿(2)——查找和扫描
接下来的文章是记录自己曾经的盲点,同时也透漏了自己的发展历程(可能发展也算不上,只能说是瞎混).当然,一些盲点也在工作和探究过程中慢慢有些眉目,现在也愿意发扬博客园的奉献精神,拿出来和大家分享一下. ...
- 引用:初探Sql Server 执行计划及Sql查询优化
原文:引用:初探Sql Server 执行计划及Sql查询优化 初探Sql Server 执行计划及Sql查询优化 收藏 MSSQL优化之————探索MSSQL执行计划 作者:no_mIss 最近总想 ...
- SQL Server 执行计划操作符详解(3)——计算标量(Compute Scalar)
接上文:SQL Server 执行计划操作符详解(2)--串联(Concatenation ) 前言: 前面两篇文章介绍了关于串联(Concatenation)和断言(Assert)操作符,本文介绍第 ...
- SQL Server 执行计划操作符详解(2)——串联(Concatenation )
本文接上文:SQL Server 执行计划操作符详解(1)--断言(Assert) 前言: 根据计划,本文开始讲述另外一个操作符串联(Concatenation),读者可以根据这个词(中英文均可)先幻 ...
- 浅析SQL SERVER执行计划中的各类怪相
在查看执行计划或调优过程中,执行计划里面有些现象总会让人有些疑惑不解: 1:为什么同一条SQL语句有时候会走索引查找,有时候SQL脚本又不走索引查找,反而走全表扫描? 2:同一条SQL语句,查询条件的 ...
随机推荐
- leetcode — powx-n
/** * Source : https://oj.leetcode.com/problems/powx-n/ * * Created by lverpeng on 2017/7/18. * * Im ...
- How Tomcat works — 二、tomcat启动(1)
主要介绍tomcat启动涉及到的一些接口和类. 目录 概述 tomcat包含的组件 server和service Lifecycle Container Connector 总结 概述 tomcat作 ...
- 【原创】驱动加载之OpenService
SC_HANDLE WINAPI OpenService( _In_ SC_HANDLE hSCManager, _In_ LPCTSTR lpServiceName, _In_ DWORD dwDe ...
- Spring Boot (四)模板引擎Thymeleaf集成
一.Thymeleaf介绍 Thymeleaf是一种Java XML / XHTML / HTML5模板引擎,可以在Web和非Web环境中使用.它更适合在基于MVC的Web应用程序的视图层提供XHTM ...
- 1.let命令总结
1.let用法类似于var,但是let只在所在代码块有效 { let a = 10; var b = 1; } a // ReferenceError: a is not defined. b // ...
- 修改wampsever中MySql5.7.14默认为空的密码
①打开WAMP找中MySql控制台,提示输入密码,开始密码为空,直接按回车 ②输入[use mysql],控制台提示[Database changed] ③输入[update user set aut ...
- python字典类型
字典类型简介 字典(dict)是存储key/value数据的容器,也就是所谓的map.hash.关联数组.无论是什么称呼,都是键值对存储的方式. 在python中,dict类型使用大括号包围: D = ...
- [转]使用Git Submodule管理子模块
本文转自:https://blog.csdn.net/qq_37788558/article/details/78668345 实例代码: 父项目:https://github.com/jjz/pod ...
- UML 概述
UML统一建模语言 1997年OMG组织(Object Management Group对象管理组织)发布了统一建模语言(Unified Modeling Language,UML).它目标 ...
- SpringMVC表单验证与Velocity整合
阅读本文约“1.2分钟” 定义表单类 以Login为例,有username和password两个字段 import javax.validation.constraints.NotNull; impo ...