Kudu原理-kudu的底层数据模型

Kudu自身的架构,部分借鉴了Bigtable/HBase/Spanner的设计思想。论文的作者列表中,有几位是HBase社区的Committer/PBC成员,因此,在论文中也能很深刻的感受到HBase对Kudu设计的一些影响
Kudu的底层数据文件的存储,未采用HDFS这样的较高抽象层次的分布式文件系统,而是自行开发了一套可基于Table/Tablet/Replica视图级别的底层存储系统。这套实现基于如下的几个设计目标:
• 可提供快速的列式查询。
• 可支持快速的随机更新
• 可提供更为稳定的查询性能保障。
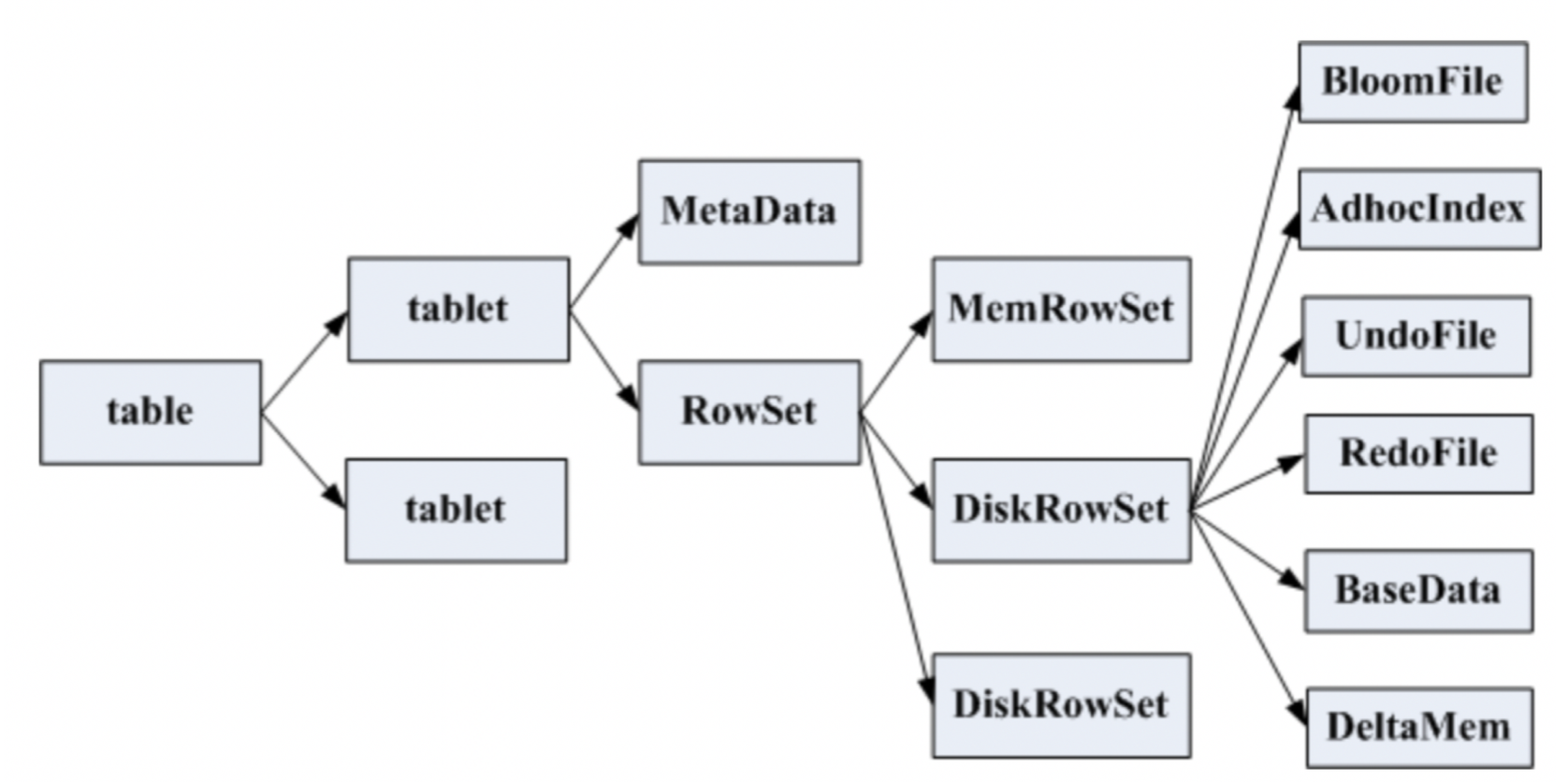
一张表会分成若干个tablet,每个tablet包括MetaData元信息及若干个RowSet,RowSet包含一个MemRowSet及若干个DiskRowSet,DiskRowSet中包含一个BloomFile、Ad_hoc Index、BaseData、DeltaMem及若干个RedoFile和UndoFile(UndoFile一般情况下只有一个)。
MemRowSet:用于新数据insert及已在MemRowSet中的数据的更新,一个MemRowSet写满后会将数据刷到磁盘形成若干个DiskRowSet。(默认是1G或者或者120S) DiskRowSet用于老数据的变更(mutation),后台定期对DiskRowSet做compaction,以删除没用的数据及合并历史数据,减少查询过程中的IO开销。 BloomFile根据一个DiskRowSet中的key生成一个bloom filter,用于快速模糊定位某个key是否在DiskRowSet中存在。 Ad_hocIndex是主键的索引,用于定位key在DiskRowSet中的具体哪个偏移位置。 BaseData是MemRowSet flush下来的数据,按列存储,按主键有序。 UndoFile是基于BaseData之前时间的历史数据,通过在BaseData上apply UndoFile中的记录,可以获得历史数据。 RedoFile是基于BaseData之后时间的变更(mutation)记录,通过在BaseData上apply RedoFile中的记录,可获得较新的数据。 DeltaMem用于DiskRowSet中数据的变更mutation,先写到内存中,写满后flush到磁盘形成RedoFile
为了实现如上目标,Kudu参考了一种类似于Fractured Mirrors的混合列存储架构。Tablet在底层被进一步细分成了一个称之为RowSets的单元:
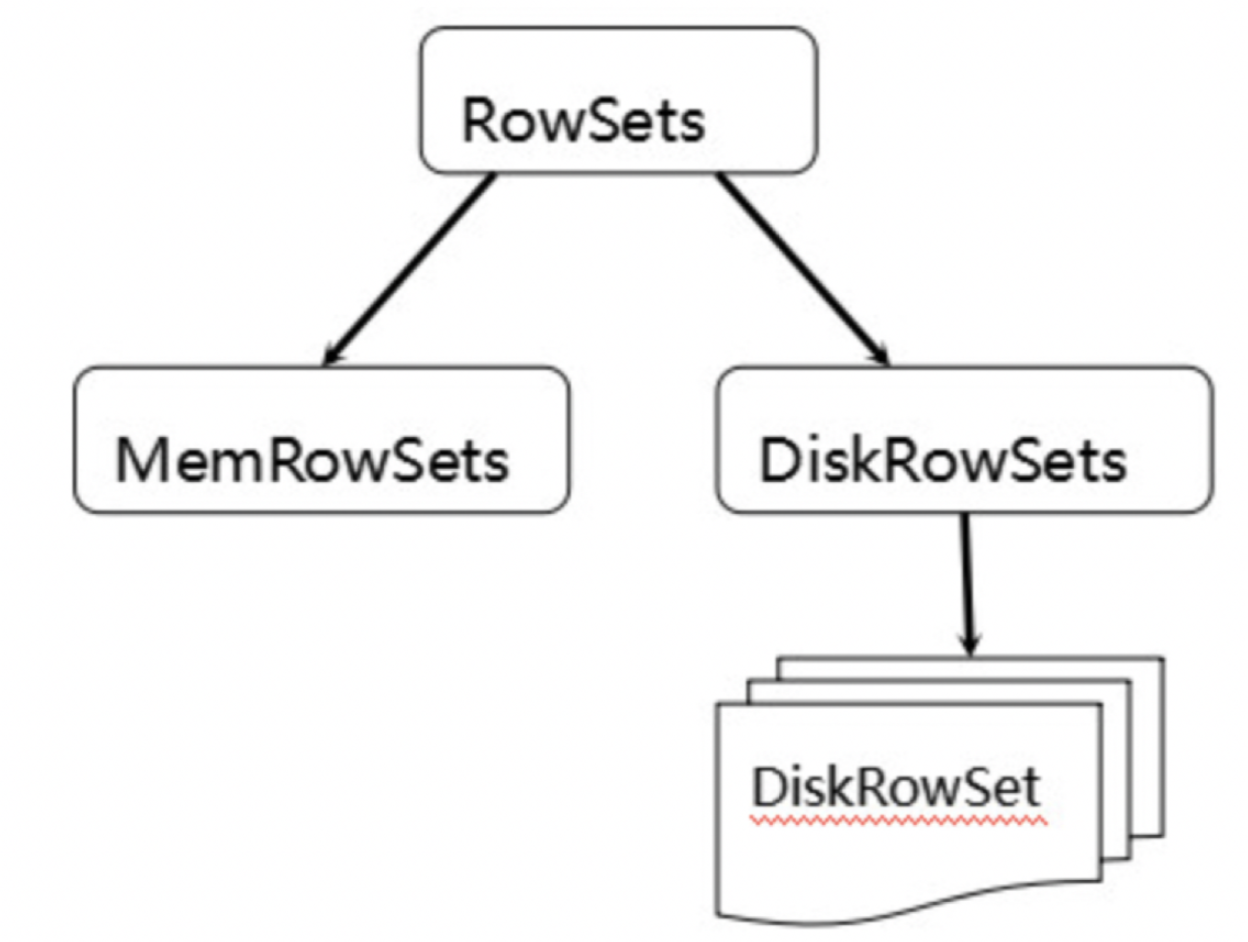
MemRowSets可以对比理解成HBase中的MemStore, 而DiskRowSets可理解成HBase中的HFile。MemRowSets中的数据按照行试图进行存储,数据结构为B-Tree。 MemRowSets中的数据被Flush到磁盘之后,形成DiskRowSets。 DisRowSets中的数据,按照32MB大小为单位,按序划分为一个个的DiskRowSet。
DiskRowSet中的数据按照Column进行组织,与Parquet类似。 这是Kudu可支持一些分析性查询的基础。每一个Column的数据被存储在一个相邻的数据区域,而这个数据区域进一步被细分成一个个的小的Page单元,与HBase File中的Block类似,对每一个Column Page可采用一些Encoding算法,以及一些通用的Compression算法。
既然可对Column Page可采用Encoding以及Compression算法,那么,对单条记录的更改就会比较困难了。 前面提到了Kudu可支持单条记录级别的更新/删除,是如何做到的? 与HBase类似,也是通过增加一条新的记录来描述这次更新/删除操作的。一个DiskRowSet包含两部分数据:基础数据(Base Data),以及变更数据(Delta Stores)。更新/删除操作所生成的数据记录,被保存在变更数据部分。
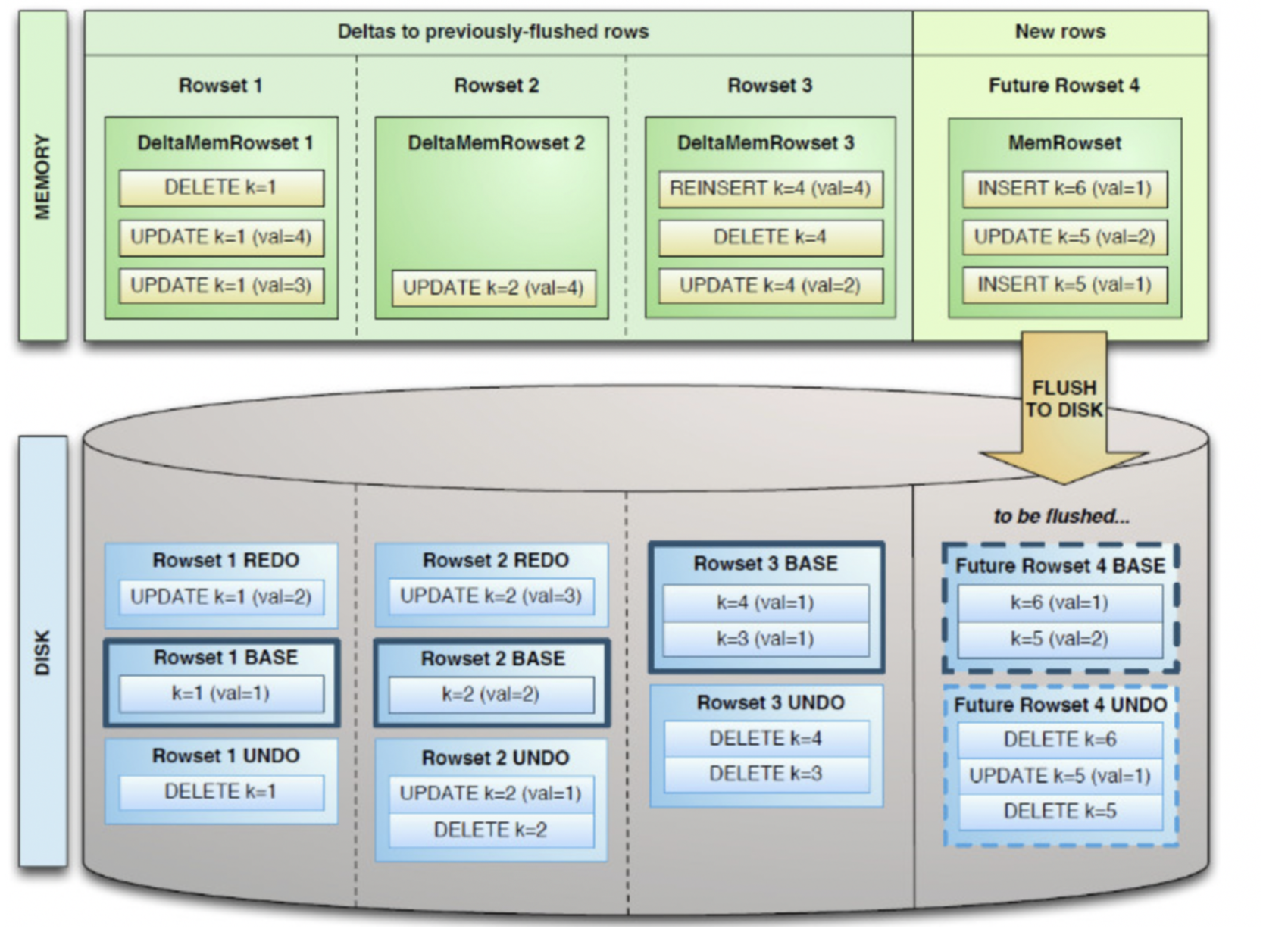
从上图(源自Kudu的源工程文件)来看:
Delta数据部分应该包含REDO与UNDO两部分,这里的REDO与UNDO与关系型数据库中的REDO与UNDO日志类似(在关系型数据库中,REDO日志记录了更新后的数据,可以用来恢复尚未写入Data File的已成功事务更新的数据。
而UNDO日志用来记录事务更新之前的数据,可以用来在事务失败时进行回滚),但也存在一些细节上的差异:
• REDO Delta Files包含了Base Data自上一次被Flush/Compaction之后的变更值。REDO Delta Files按照Timestamp顺序排列。 • UNDO Delta Files包含了Base Data自上一次Flush/Compaction之前的变更值。这样才可以保障基于一个旧Timestamp的查询能够看到一个一致性视图。UNDO按照Timestamp倒序排列。
Kudu原理-kudu的底层数据模型的更多相关文章
- Kudu系列: Kudu主键选择策略
每个Kudu 表必须设置Pimary Key(unique), 另外Kudu表不能设置secondary index, 经过实际性能测试, 本文给出了选择Kudu主键的几个策略, 测试结果纠正了我之前 ...
- kudu记录-kudu原理
1.kudu是什么? 2.kudu基本概念 特点: High availability(高可用性).Tablet server 和 Master 使用 Raft Consensus Algorith ...
- 【Web应用-Kudu】Kudu 管理和诊断 azure web 应用
Azure Kudu是 GitHub 上的一个开源项目,Kudu 站点 (也称为网站控制管理 SCM) 提供了一系列的在线工具,可以帮助用户查看 web 应用的设置,诊断 web 应用,以及安装 w ...
- List、Set集合系列之剖析HashSet存储原理(HashMap底层)
目录 List接口 1.1 List接口介绍 1.2 List接口中常用方法 List的子类 2.1 ArrayList集合 2.2 LinkedList集合 Set接口 3.1 Set接口介绍 Se ...
- 2 weekend110的zookeeper的原理、特性、数据模型、节点、角色、顺序号、读写机制、保证、API接口、ACL、选举、 + 应用场景:统一命名服务、配置管理、集群管理、共享锁、队列管理
在hadoop生态圈里,很多地方都需zookeeper. 启动的时候,都是普通的server,但在启动过程中,通过一个特定的选举机制,选出一个leader. 只运行在一台服务器上,适合测试环境:Zoo ...
- HBase 架构与工作原理1 - HBase 的数据模型
本文系转载,如有侵权,请联系我:likui0913@gmail.com 一.应用场景 HBase 与 Google 的 BigTable 极为相似,可以说 HBase 就是根据 BigTable 设计 ...
- 破败之王杀人戒bug原理剖析(从底层存储来解释)
今儿看到了破败之王的bug,一级团杀了人变成了对面,然后送塔,戒指就变成了很夸张的层数. 视频如下: https://www.bilibili.com/video/BV1yr4y1A7Mo 一开始我也 ...
- Redis核心设计原理(深入底层C源码)
Redis 基本特性 1. 非关系型的键值对数据库,可以根据键以O(1) 的时间复杂度取出或插入关联值 2. Redis 的数据是存在内存中的 3. 键值对中键的类型可以是字符串,整型,浮点型等,且键 ...
- kudu基础入门
1.kudu介绍 1.1 背景介绍 在KUDU之前,大数据主要以两种方式存储: (1)静态数据: 以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景.这类存储的局限性是数据无法进行随机 ...
随机推荐
- 在 mingw32 上编译 libvpx 1.7.0 时的注意事项
in the vp8/common/theading.h Just need to add 1 line:#include <sys/types.h>before the last occ ...
- Sq lServer触发器的使用
创建表: CREATE TABLE [dbo].[GeneralRule]( [ID] [int] NOT NULL, ) NULL, [DeleteFlag] [int] NOT NULL ) CR ...
- python第13天
装饰器 装饰器本质上就是一个python函数,他可以让其他函数在不需要做任何改动的前提下,增加额外的功能,装饰器的返回值也是一个函数对象. 装饰器的应用场景:比如插入日志,性能测试,事务处理,缓存等等 ...
- Dubbo原理解析-Dubbo内核实现之SPI简单介绍
转自:https://blog.csdn.net/quhongwei_zhanqiu/article/details/41577159 Dubbo 采用微内核+插件体系,使得设计优雅,扩展性强.那所谓 ...
- Tornado学习笔记(二) 路由/post/get传参
本章我们学习 Tornado 的路由传参等问题 路由 路由的匹配 Tornado的路由匹配采用的是正则匹配 一般情况下不需要多复杂的正则,正则的基本规则如下(站长之家) 举个例子 (r'/sum/(\ ...
- python与用户交互、数据类型
一.与用户交互 1.什么是用户交互: 程序等待用户输入一些数据,程序执行完毕反馈信息. 2.如何使用 在python3中使用input,input会将用户输入的如何内容存为字符串:在python中分为 ...
- chkconfig: command not found
问题描述 Ubuntu 16.04 下安装 Nginx 服务器,在添加 nginx 服务时出现如下信息 # chkconfig --add nginx chkconfig: command not f ...
- Confluence 6 使用 JConsole 监控本地 Confluence
如果你遇到了一些特定的问题,或者你仅仅是希望在一个很短的时间内监控你 Confluence 的运行,你可以使用本地监控.本地监控将会对你的服务器性能产生影响,所以我们并不推荐你使用本地监控来长时间的监 ...
- Confluence 6 生产环境备份策略
如果你是下面的情况,Confluence 的自动每日 XML 备份可能适合你: 正在评估使用 Confluence 你对数据库的管理并不是非常熟悉同时你的 Confluence 安装实例的数据量并不大 ...
- python并发编程之多进程2-------------数据共享及进程池和回调函数
一.数据共享 1.进程间的通信应该尽量避免共享数据的方式 2.进程间的数据是独立的,可以借助队列或管道实现通信,二者都是基于消息传递的. 虽然进程间数据独立,但可以用过Manager实现数据共享,事实 ...