【CPU微架构设计】利用Verilog设计基于饱和计数器和BTB的分支预测器
在基于流水线(pipeline)的微处理器中,分支预测单元(Branch Predictor Unit)是一个重要的功能部件,它负责收集和分析分支/跳转指令的执行结果,当处理后续分支/跳转指令时,BPU将根据已有的统计结果和当前分支跳转指令的参数,预测其执行结果,进而为流水线取指提供决策依据,从而提高流水线效率。
本文将针对分支预测单元的设计思路进行讨论。在进行设计前,首先需要说明使用分支预测技术的原因及其现实意义。
在流水线处理分支跳转指令时,目标地址往往需要推迟到指令的执行阶段才能运算得出,在此之前处理器无法及时得知下一条指令的取指地址,因此无法继续取指。一种直接的解决方法是在识别分支指令后,令取指流水级及相关的流水级暂停(stall),等待分支目标地址计算完成后再继续取指。这将浪费若干流水线时钟周期,从而降低性能;另一种方法是引入延迟槽(Delay Slot)机制,使得分支指令紧接的下一条指令流入流水线并执行。该指令将先于分支之前执行,因此可作为初始化相关指令。然而在某些情况下,延迟槽指令仍然只能简单地用nop指令填充,同样会造成性能损失。
为便于说明,引入经典四级流水线模型的一个实例。下图显示了分支指令产生流水线气泡周期的过程。(注:在本例中不考虑延迟槽机制。)
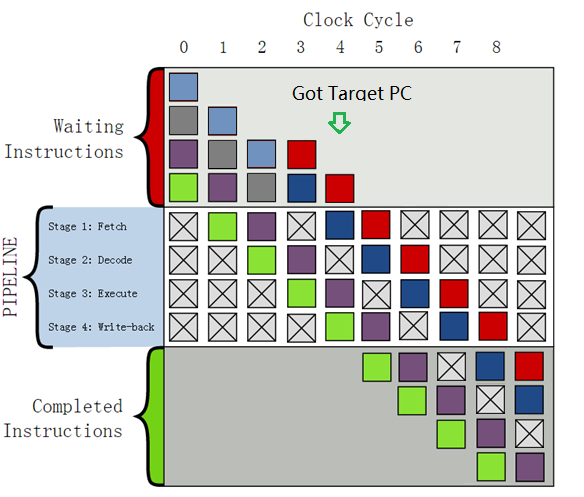
(附图:经典的四级流水线中分支指令引发的流水线暂停示意图。左上紫色方块代表分支指令。由于采用简单的理想流水线,分支指令目标地址在执行阶段即可得出。采用上述方法将浪费一个流水线时钟周期)
为改进以上方法, 我们考虑引进一种静态分支预测机制,即预测分支跳转指令一定不跳转(not taken),则上述情况将成为:默认分支跳转指令之后的指令也流入pipeline,在若干流水级后,分支指令的地址将被计算得出,此时才判断之前流入流水线的指令是否为实际目标地址所指向的指令,若真,流水线可以继续运行而不必暂停;但若假,则之前流入的指令都无效,相关流水级将被冲刷(flush),处理器只能重新从正确的地址开始取值,这将同样降低流水线的效率。
可以看到,采用静态预测后,在处理分支/跳转指令时,流水线在一定概率下将不会因分支而暂停,这就降低了出现流水线气泡周期的可能性。然而,在对性能要求较高的场合,此方法仍旧不能令人满意。
下图显示了采用静态预测后,由于预测失败造成流水线flush,进而产生流水线气泡的过程。
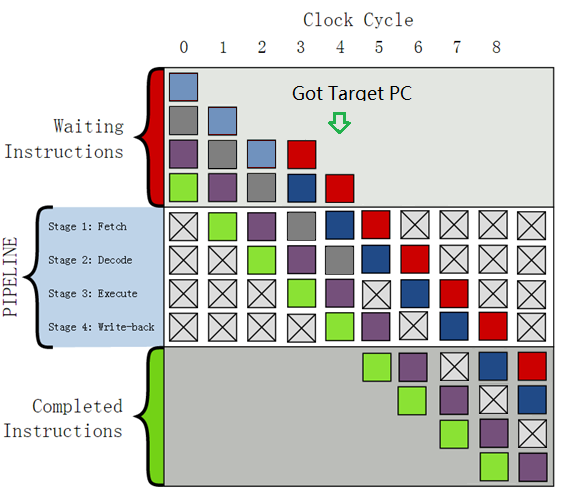
(附图:灰色方块指令处在译码阶段时,分支指令处于执行阶段,得出分支目标地址,并且发现灰色方块指令不是目标地址所指向的指令(应为蓝色方块指令),所以预测失败,灰色方块指令被取消,并在下一周期产生流水线气泡)
为进一步提高效率,我们考虑动态分支预测机制。动态预测基于对分支历史的记录统计,预测出分支跳转的“方向”和“目标地址”。若处理器按照预测结果取指,则一旦预测结果与实际跳转结果相同,之前流入流水线的指令将完全有效,流水线将维持运行。处理器按照预测出的“方向”和“目标地址”进行取值的行为称为预测取值(Speculative Fetch),执行按照预测结果取出的指令的行为称为预测执行(Speculative Execution)
随着预测算法的不断改进,当前分支预测的准确率不断向1逼近,分支预测技术有效提高了流水线的运行效率,被大量运用到主流微处理器架构中。例如,目前新兴的RISC指令集,如openRISC、RISC-V等,基本都取消了延迟槽设计,这种进步得益于分支预测精度的提高。
分支预测的理论依据可参考相关资料,本文不再赘述,接下来重点讨论分支预测单元的设计相关问题。
一、分支预测需要解决的问题
(1)、预测分支是否发生,即预测“方向”的问题;
(2)、预测分支指令设置的取值地址,即预测“目标地址”的问题。
二、分支预测单元的设计实现
常见的分支预测机制主要可分为一级结构和两级结构。对于两级预测器,常见的算法包括gshare和gselect算法,这种算法考虑到分支指令的上下文执行历史,精度相对较高,但实现相对复杂,本文不予讨论。对于一级预测器,其设计是将多个饱和计数器和分支目标缓存器组织成一维向量表,利用分支/跳转指令PC值的hash映射值寻址一维向量表,取出预测结果,或根据执行情况维护状态机。这种预测器结构最为简单,本文将针对这种结构做详细的讨论。
2.1 分支方向的预测
对于分支方向的预测,本文采取一种基于“方向惯性”的原理,即对于一条具体的分支指令,若该指令多次发生跳转,则认为后续执行该指令时仍会发生跳转,反之亦然。若指令预测方向与实际方向相反,则使得预测方向逐步向相反方向运动。
本文采用2bit的饱和计数器,用于寄存4种状态。根据预测结果和实际执行结果,计数器的状态机转移图如下。
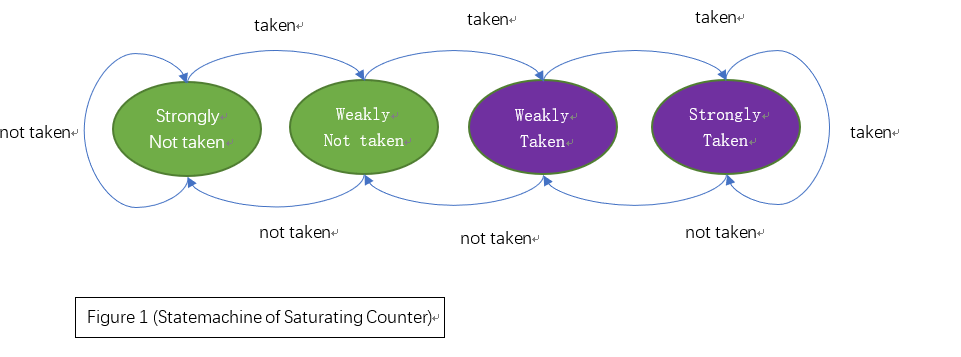
图中跳转(taken)和不跳转(not taken)两种状态分别被进一步细分为强(strong)和弱(weak)共四种状态,并规定strongly taken和weakly taken为“跳转”、strongly not taken和weakly not taken为“不跳转”,且每当预测出错后,计数器会以相反方向更改状态。
为便于饱和计数器的实现,首先对四种状态进行二进制编码。
| SCS_STRONGLY_TAKEN | 2‘b11 |
| SCS_WEAKLY_TAKEN | 2'b10 |
| SCS_WEAKLY_NOT_TAKEN | 2'b01 |
| SCS_STRONGLY_NOT_TAKEN | 2'b00 |
根据编码,在进行状态切换时,我们只需简单地在不溢出的情况下,对计数器进行自增或自减操作:当taken时,若计数值自增后不溢出,则自增;当not taken时,若计数值自减后不溢出,则自减。
同时,易知当计数值最高位为1时,预测结果为taken;当计数值最高位为0时,预测结果为not taken。
以上仅讨论了针对单个分支指令的预测。对于多条位于不同地址的分支指令,首先将若干饱和计数器组织成一维向量表,然后利用每条指令的PC值对该一维向量表进行寻址,这样就找到了每条分支指令对单一饱和计数器的映射关系。
2.2 分支目标地址的预测
为了简化设计,本文主要讨论基于分支目标缓存(Branch Target Buffer)技术的预测器。BTB使用容量有限的缓存寄存最近执行的分支指令的目标地址。对于后续分支指令,预测时直接取出对应表项中寄存的地址作为目标地址预测值。当分支指令被执行后,将实际的目标地址回写入BTB中,为下次预测提供依据。
本设计中,使用使用分支指令PC值的hash映射值寻址BTB表项,使得每条分支跳转指令都能与BTB表项建立起映射关系。
其中,我们定义PC值的hash映射规则如下:
∫ V(PC) → V(hash), f(p) ; f(p) = p & 1111111111b (即取出PC值低10位作为对应的hash映射值)
这种算法同样被用于2.1中所描述的饱和计数器表的寻址。
2.3 组织结构
综上所述,分支预测器的总体框架如下,可以看出,该预测器具有极其简单的结构:

三、硬件描述语言实现
通过以上讨论,容易使用Verilog HDL实现分支预测器。 这里仅对饱和计数器进行非溢出的递增或递减,利用计数值的最高位判断是否发生跳转,1为taken,0为not taken。
module bpu
#(
, // The width of valid PC
, // The width of btb address
)
(/*AUTOARG*/
// Outputs
pre_taken_o, pre_target_o,
// Inputs
clk, rst_n, pc_i, set_i, set_pc_i, set_taken_i, set_target_i
);
// Ports
input clk;
input rst_n;
:] pc_i; // PC of current branch instruction
input set_i;
:] set_pc_i;
input set_taken_i;
:] set_target_i;
output reg pre_taken_o;
:] pre_target_o;
// Local Parameters
'b11;
'b10;
'b01;
'b00;
wire bypass;
:] tb_entry;
:] set_tb_entry;
// PC Address hash mapping
:];
:];
assign bypass = set_i && set_pc_i == pc_i;
// Saturating counters
:] counter[(<<BTBW)-:];
generate begin :counter
integer entry;
always @(posedge clk or negedge rst_n)
if(!rst_n)
; entry < (<<BTBW); entry=entry+) // reset BTB entries
counter[entry] <= 'b00;
else if(set_i && set_taken_i && counter[set_tb_entry] != SCS_STRONGLY_TAKEN) begin
counter[set_tb_entry] <= counter[set_tb_entry] + 'b01;
else if(set_i && !set_taken_i && counter[set_tb_entry] != SCS_STRONGLY_NOT_TAKEN) begin
counter[set_tb_entry] <= counter[set_tb_entry] - 'b01;
end
endgenerate
always @(posedge clk)
pre_taken_o <= bypass ? set_taken_i : counter[tb_entry][];
// BTB vectors
:] btb[(<<BTBW)-:];
generate begin :btb_rst
integer entry;
always @(posedge clk or negedge rst_n)
if(!rst_n)
; entry < (<<BTBW); entry=entry+) begin // reset BTB entries
btb[entry] <= {PCW{'b0}};
end
endgenerate
always @(posedge clk)
pre_target_o <= bypass ? set_pc_i : btb[tb_entry];
always @(posedge clk)
if( set_i )
btb[set_tb_entry] <= set_target_i;
endmodule
对该实现需要做如下说明:
(1)、BPU在每个时钟周期内完成预测和更新操作。pc_i端口输入待预测的指令PC值,set_i端口指示是否在下一个时钟周期到来时更新预测器。
(2)、考虑到特殊的指令流情况,该实现添加了旁路(bypass)机制。对于具体的处理器实现,旁路可能永不发生,因此可以去掉这部分实现。
(3)、对于在BTB中没有记录的分支指令,BPU默认预测目标地址输出为0(BTB在此之前进行过置零复位)。对于具体的处理器实现,可考虑将分支指令的下一条指令的PC值作为目标地址的预测值。
四、总结
通过讨论,我们提出了基于饱和计数器和BTB的分支预测单元的设计思路,并最终利用Verilog实现了该分支预测器的原型。该实现在面积上具有一定优势,可运用于微处理器实验和验证等场合;同时,该设计也存在一些不足之处:
(1)、在求PC值的hash映射值时,仅简单地取PC低10bit的数据作为BTB的索引,这将导致PC值高位相同的分支指令的记录状态互相混淆,从而降低预测精度;
(2)、该设计仅考虑分支指令的全局状态,而没有跟踪分支指令具体的上下文环境;
(3)、对于带条件判断的分支指令、或寄存器直接/间接寻址的跳转指令,由于其操作数保存在寄存器中,而寄存器的值往往是不断变化的,这将导致对分支目标地址的预测精度降低。
===================================================
本博文仅供参考,多有疏漏之处,欢迎提出宝贵意见。
【CPU微架构设计】利用Verilog设计基于饱和计数器和BTB的分支预测器的更多相关文章
- 【CPU微架构设计】分布式多端口(4写2读)寄存器堆设计
寄存器堆(Register File)是微处理的关键部件之一.寄存器堆往往具有多个读写端口,其中写端口往往与多个处理单元相对应.传统的方法是使用集中式寄存器堆,即一个集中式寄存器堆匹配N个处理单元.随 ...
- CPU分支预测器
两篇结合就ok啦 1.https://www.jianshu.com/p/be389eeba589 2.https://blog.csdn.net/edonlii/article/details/87 ...
- ARM架构--CPU的微架构
网上确实有说ARM架构的,但是此架构泛指用ARM指令系统的CPU,而不是CPU的微架构.,硬件电路上,要用ARM指令集系统,必然硬件设计电路上要要遵循,ARM指令的特点和寻址方式,所以说高通和苹果的C ...
- InfoQ一波文章:菜鸟核心技术/Intel发布CPU新架构3D堆栈法/BDL/PaddlePaddle/百度第三代Spider/Tera
菜鸟智慧新物流核心技术全解析 孟靖 阅读数:63192018 年 12 月 14 日 16:00 2018 年天猫双 11 全球狂欢节已正式落下帷幕,最终成交额定格在 2135 亿元,物流订单 ...
- 现代中央处理器(CPU)是怎样进行分支预测的?
人们一直追求CPU分支预测的准确率,论文Simultaneous Subordinate Microthreading (SSMT)中给了一组数据,如果分支预测的准确率是100%,大多数应用的IPC会 ...
- 【操作系统之十二】分支预测、CPU亲和性(affinity)
一.分支预测 当包含流水线技术的处理器处理分支指令时就会遇到一个问题,根据判定条件的真/假的不同,有可能会产生转跳,而这会打断流水线中指令的处理,因为处理器无法确定该指令的下一条指令,直到分支执行完毕 ...
- 从一段 Dubbo 源码到 CPU 分支预测的一次探险之旅
每个时代,都不会亏待会学习的人. 大家好,我是 yes. 这次本来是打算写一篇 RocketMQ 相关文章的,但是被插队了,我也是没想到的. 说来也是巧最近在看 Dubbo 源码,然后发现了一处很奇怪 ...
- 如何在代码层面提供CPU分支预测效率
关于分支预测的基本概念和详细算法可以参考我之前写的知乎回答,基本概念不再阐述了~~ https://www.zhihu.com/question/486239354/answer/2410692045 ...
- 手机服务器微架构设计与实现 之 http server
手机服务器微架构设计与实现 之 http server ·应用 ·传输协议和应用层协议概念 TCP UDP TCP和UDP选择 三次握手(客户端与服务器端建立连接)/四次挥手(断开连接)过程图 · ...
随机推荐
- Difference Between Git and SVN
From: http://www.differencebetween.net/technology/software-technology/difference-between-git-and-svn ...
- elasticSearch 2.3 delete-by-query plugin
The delete-by-query plugin adds support for deleteing all of the documents which match the specified ...
- SQL SERVER2008 数据库日志文件的收缩方法
最近公司的数据库随着业务量的增多,日志文件巨大(超过300G),造成磁盘空间不够用,进而后来的访问数据库请求无法访问. 网上类似的方法也很多,但不可行,如下是我实践过,可行的,将日志文件收缩至任意指定 ...
- iOS安全系列之一:HTTPS
如何打造一个安全的App?这是每一个移动开发者必须面对的问题.在移动App开发领域,开发工程师对于安全方面的考虑普遍比较欠缺,而由于iOS平台的封闭性,遭遇到的安全问题相比于Android来说要少得多 ...
- kali syn洪水攻击实例
kali 172.30.2.241 受攻击:172.30.2.242 syn攻击造成对方cpu跑满 基本上丧失工作能力 攻击语句
- bootstrap 常用class
导航中的折叠菜单 collapse 手机端折叠 navbar-collapse 电脑端展开 navbar-inverse 反色 navbar-default 默认的nav风格 sr-only 专门给屏 ...
- jquery datatable数据初始化
一个datatable的初始化问题,困扰了在下整整半天,最后在网上各位大神的帮助下,终于解决了. 首先分析一下我所遇到的问题: 在HTML上有个下拉框,我需要获取下拉框的值来从后台数据库中获取不同的数 ...
- mvcmovie sample 在window10 下的部署问题(HTTP Error 500.19 - Internal Server Error)
mvcmovie sample 在window10 下的部署问题 使用VS2018配置好了mvcmovie sample,发布到IIS后,打开报错: HTTP Error 500.19 - Inter ...
- T4代码生成脚本从添加注释,添加命名空间开始(一款强大的代码生成工具从看懂脚本,到随心所欲的玩弄代码,本文只是T4的冰山一角,博主将不断深入探索并完善该文章)
精通T4脚本要从读懂脚本的关键代码片段开始 1.1. 给类添加注释-->看懂类对应的代码:<#=codeStringGenerator.EntityClassOpening(entity ...
- 【python】django上传文件
参考:https://blog.csdn.net/zahuopuboss/article/details/54891917 参考:https://blog.csdn.net/zzg_550413470 ...