封装自己的dapper lambda扩展-设计篇
前言
昨天开源了业务业余时间自己封装的dapper lambda扩展,同时写了篇博文《编写自己的dapper lambda扩展-使用篇》简单的介绍了下其使用,今天将分享下它的设计思路
链式编程
其实就是将多个方法通过点(.)将它们串接起来,让代码更加简洁, 可读性更强。
new SqlConnection("").QuerySet<User>()
.Where(a => a.Name == "aasdasd")
.OrderBy(a => a.CreateTime)
.Top(10)
.Select(a => a.Name).ToList();
其原理是类的调用方法的返回值类型为类本身或其基类,选择返回基类的原因是为了做降级约束,例如我希望使用了Top之后接着Select和ToList,无法再用where或orderBy。
UML图

原型代码
CommandSet
public class CommandSet<T> : IInsert<T>, ICommand<T>
{
#region 方法
public int Insert(T entity)
{
throw new NotImplementedException();
} public int Update(T entity)
{
throw new NotImplementedException();
} public int Update(Expression<Func<T, T>> updateExpression)
{
throw new NotImplementedException();
} public int Delete()
{
throw new NotImplementedException();
} public IInsert<T> IfNotExists(Expression<Func<T, bool>> predicate)
{
throw new NotImplementedException();
} public ICommand<T> Where(Expression<Func<T, bool>> predicate)
{
throw new NotImplementedException();
}
#endregion
} public interface ICommand<T>
{
int Update(T entity);
int Update(Expression<Func<T, T>> updateExpression);
int Delete();
} public interface IInsert<T>
{
int Insert(T entity);
} public static class Database
{
public static QuerySet<T> QuerySet<T>(this SqlConnection sqlConnection)
{
return new QuerySet<T>();
} public static CommandSet<T> CommandSet<T>(this SqlConnection sqlConnection)
{
return new CommandSet<T>();
}
}
QuerySet
public class QuerySet<T> : IAggregation<T>
{
#region 方法
public T Get()
{
throw new NotImplementedException();
} public List<T> ToList()
{
throw new NotImplementedException();
} public PageList<T> PageList(int pageIndex, int pageSize)
{
throw new NotImplementedException();
} public List<T> UpdateSelect(Expression<Func<T, T>> @where)
{
throw new NotImplementedException();
} public IQuery<TResult> Select<TResult>(Expression<Func<T, TResult>> selector)
{
throw new NotImplementedException();
} public IOption<T> Top(int num)
{
throw new NotImplementedException();
} public IOrder<T> OrderBy<TProperty>(Expression<Func<T, TProperty>> field)
{
throw new NotImplementedException();
} public IOrder<T> OrderByDescing<TProperty>(Expression<Func<T, TProperty>> field)
{
throw new NotImplementedException();
} public int Count()
{
throw new NotImplementedException();
} public bool Exists()
{
throw new NotImplementedException();
} public QuerySet<T> Where(Expression<Func<T, bool>> predicate)
{
throw new NotImplementedException();
}
#endregion
} public interface IAggregation<T> : IOrder<T>
{
int Count();
bool Exists();
} public interface IOrder<T> : IOption<T>
{
IOrder<T> OrderBy<TProperty>(Expression<Func<T, TProperty>> field);
IOrder<T> OrderByDescing<TProperty>(Expression<Func<T, TProperty>> field);
} public interface IOption<T> : IQuery<T>, IUpdateSelect<T>
{
IQuery<TResult> Select<TResult>(Expression<Func<T, TResult>> selector); IOption<T> Top(int num);
} public interface IUpdateSelect<T>
{
List<T> UpdateSelect(Expression<Func<T, T>> where);
} public interface IQuery<T>
{
T Get(); List<T> ToList(); PageList<T> PageList(int pageIndex, int pageSize);
}
以上为基本的设计模型,具体实现如有问题可以查看我的源码。
表达式树的解析
具体实现的时候会涉及到很多的表达式树的解析,例如where条件、部分字段update,而我实现的时候一共两步:先修树,再翻译。然而无论哪步都得对表达式树进行遍历。
表达式树
百度的定义:也称为“表达式目录树”,以数据形式表示语言级代码,它是一种抽象语法树或者说是一种数据结构。
我对它的理解是,它本质是一个二叉树,节点拥有自己的属性像nodetype。
而它的遍历方式为前序遍历
前序遍历
百度的定义:历首先访问根结点然后遍历左子树,最后遍历右子树。在遍历左、右子树时,仍然先访问根结点,然后遍历左子树,最后遍历右子树,以下图为例
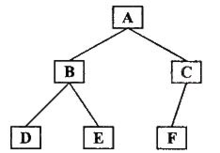
其遍历结果为:ABDECF
以一个实际例子:
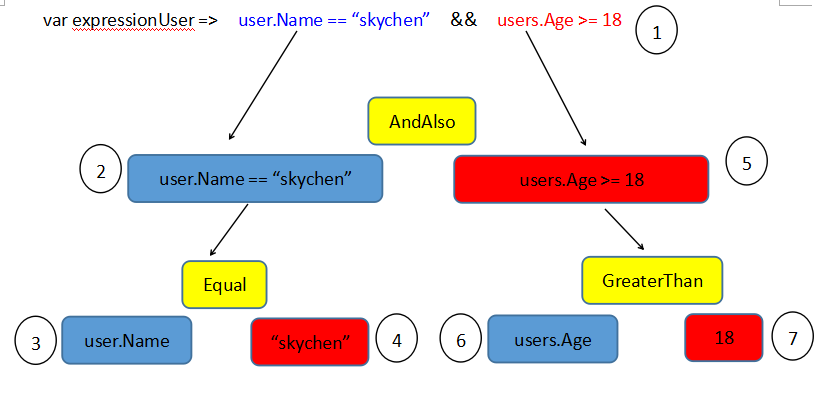
从上图可以看出,我们会先遍历到根节点的NodeType AndAlso翻译为 and ,然后到节点2,NodeType的Equal翻译为 = ,再到3节点翻译为 Name,再到4节点翻译为'skychen',那么将3、4节点拼接起来就为Name = 'skychen',如果类推6、7为Age >= 18,最后拼接这个语句为 Name = 'skychen' and Age >= 18。
修树
修树的目的,为了我们更好的翻译,例如DateTime.Now表达式树里的NodeType为MemberAccess,我希望转换成NodeType为Constant类型,以'2018-06-27 16:18:00'这个值作为翻译。
结束
以上为设计和实现的要点,具体的实现问题可以查看源码,如果有建议和疑问可以在下方留言,如果对您起到作用,希望您点一下推荐作为对我的支持。
再次双手奉上源码:https://github.com/SkyChenSky/Sikiro.DapperLambdaExtension.MsSql
封装自己的dapper lambda扩展-设计篇的更多相关文章
- 【转】.NET(C#):浅谈程序集清单资源和RESX资源 关于单元测试的思考--Asp.Net Core单元测试最佳实践 封装自己的dapper lambda扩展-设计篇 编写自己的dapper lambda扩展-使用篇 正确理解CAP定理 Quartz.NET的使用(附源码) 整理自己的.net工具库 GC的前世与今生 Visual Studio Package 插件开发之自动生
[转].NET(C#):浅谈程序集清单资源和RESX资源 目录 程序集清单资源 RESX资源文件 使用ResourceReader和ResourceSet解析二进制资源文件 使用ResourceM ...
- 编写自己的dapper lambda扩展-使用篇
前言 这是针对dapper的一个扩展,支持lambda表达式的写法,链式风格让开发者使用起来更加优雅.直观.现在暂时只有MsSql的扩展,也没有实现事务的写法,将会在后续的版本补充. 这是个人业余的开 ...
- 开源Dapper的Lambda扩展-Sikiro.Dapper.Extension V2.0
前言 去年我在业余时间,自己整了一套dapper的lambda表达式的封装,原本是作为了一个个人的娱乐项目,当时也只支持了Sql Server数据库.随之开源后,有不少朋友也对此做了试用,也对我这个项 ...
- 基于Dapper的开源Lambda扩展LnskyDB 2.0已支持多表查询
LnskyDB LnskyDB是基于Dapper的Lambda扩展,支持按时间分库分表,也可以自定义分库分表方法.而且可以T4生成实体类免去手写实体类的烦恼. 文档地址: https://lining ...
- 基于Dapper的开源Lambda扩展,且支持分库分表自动生成实体之基础介绍
LnskyDB LnskyDB是基于Dapper的Lambda扩展,支持按时间分库分表,也可以自定义分库分表方法.而且可以T4生成实体类免去手写实体类的烦恼. 文档地址: https://lining ...
- 基于Dapper的开源Lambda扩展LnskyDB 3.0已支持Mysql数据库
LnskyDB LnskyDB是基于Dapper的Lambda扩展,支持按时间分库分表,也可以自定义分库分表方法.而且可以T4生成实体类免去手写实体类的烦恼.,现在已经支持MySql和Sql serv ...
- 《手把手教你》系列基础篇(九十七)-java+ selenium自动化测试-框架设计篇-Selenium方法的二次封装和页面基类(详解教程)
1.简介 上一篇宏哥介绍了如何设计支持不同浏览器测试,宏哥的方法就是通过来切换配置文件设置的浏览器名称的值,来确定启动什么浏览器进行脚本测试.宏哥将这个叫做浏览器引擎类.这个类负责获取浏览器类型和启动 ...
- 深入理解Java 8 Lambda(语言篇——lambda,方法引用,目标类型和默认方法)
作者:Lucida 微博:@peng_gong 豆瓣:@figure9 原文链接:http://zh.lucida.me/blog/java-8-lambdas-insideout-language- ...
- jQuery2.x源码解析(设计篇)
jQuery2.x源码解析(构建篇) jQuery2.x源码解析(设计篇) jQuery2.x源码解析(回调篇) jQuery2.x源码解析(缓存篇) 这一篇笔者主要以设计的角度探索jQuery的源代 ...
随机推荐
- JavaScript中,JSON格式的字符串与JSON格式的对象相互转化
前言:JSON是一个独立于任何语言的数据格式,因此,严格来说,没有“JSON对象”和“JSON字符串”这个说法(然而”菜鸟教程“和”W3school“使用了“JSON对象”和“JSON字符串”这个说法 ...
- Linux平台下RMAN异机恢复总结
下面总结.整理一下RMAN异机恢复这方面的知识点,这篇笔记在个人笔记里面躺了几年了,直到最近偶然被翻看到,遂整理.总结一下.如下所示,个人将整个RMAN异机恢复分为准备工作和操作步骤两大部分.当然,准 ...
- C#-异常处理(十四)
概念 异常处理是指程序在运行过程中,发生错误会导致程序退出,这种错误,就叫做异常 但并不是所有的错误都是异常 而处理这种错误,称为异常处理 异常处理实际是不断去发掘异常.修改异常,使程序更稳定 异常处 ...
- Linux进程调度器概述--Linux进程的管理与调度(十五)
调度器面对的情形就是这样, 其任务是在程序之间共享CPU时间, 创造并行执行的错觉, 该任务分为两个不同的部分, 其中一个涉及调度策略, 另外一个涉及上下文切换. 1 背景知识 1.1 什么是调度器 ...
- JavaScript -- 时光流逝(十二):DOM -- Element 对象
JavaScript -- 知识点回顾篇(十二):DOM -- Element 对象 (1) element.accessKey: 设置或返回accesskey一个元素,使用 Alt + 指定快捷键 ...
- June. 21 2018, Week 25th. Thursday
Summertime is always the best of what might be. 万物最美的一面,总在夏季展现. From Charles Bowden. It was June, an ...
- June 10. 2018, Week 24th, Sunday
There is no friend as loyal as a book. 好书如挚友,情谊永不渝. From Ernest Miller Hemingway. Books are my frien ...
- Nginx使用教程(二):Nginx配置性能优化之worker配置
配置Nginx workers <br\>NGINX根据指定的配置运行固定数量的工作进程. 这些工作进程负责处理所有处理. 在下面的章节中,我们将调整NGINX worker参数. 这些参 ...
- SpringMVC-DispatcherServlet工作流程及web.xml配置
工作流程: Web中,无非是请求和响应: 在SpringMVC中,请求的第一站是DispatcherServlet,充当前端控制器角色: DispatcherServlet会查询一个或多个处理器映射( ...
- jquery中prop()和attr()用法
jquery1.6中新加了一个方法prop(),一直没用过它,官方解释只有一句话:获取在匹配的元素集中的第一个元素的属性值. 大家都知道有的浏览器只要写disabled,checked就可以了,而有的 ...