Windows下CRF++进行中文人名识别的初次尝试
语料来自1998年1月份人民日报语料
1 语料处理
1.1 原始语料数据格式
语料中,句子已经被分词好,并且在人名后以“/”标注了“nr”表示是人名,其他非人名的分词没有进行标注

1.2 CRF++要求语料的格式
训练语料至少应具有两列,列间由空格或制表位间隔,且所有行(空行除外)必须具有相同的列数,句子间使用空行间隔

1.3 对原始数据进行处理
CRF++可以有多个特征,举例如下图

本次实验为了熟悉采用CRF++及进行中文人名标注,故将语料中的每一个单字作为特征,并进行BIEO标注,举例如下图

采用Python将原始数据读入,并将其格式转化为标准的两个列向量的格式,举例如下

代码如下
# coding:utf-8
import codecs
fin = codecs.open("data_to_final.txt", "r", "utf-8")
f = codecs.open("data_to_final_to_crf.txt", "a", "utf-8")
row = 1
while (True):
text = fin.readline()
if (text == ""):
break
tmp = text.split(" ")
n = len(tmp)
for i in range(0, n - 1):
if 'nr' in tmp[i]:
word = tmp[i].split('/')
tmpword = word[0]
wordlist = list(tmpword)
m = len(wordlist)
if m == 1:
f.write(wordlist[0] + ' S\n')
elif m == 2:
f.write(wordlist[0] + ' B\n')
f.write(wordlist[1] + ' E\n')
else:
f.write(wordlist[0] + ' B\n')
for k in range(1, m -1):
f.write(wordlist[k] + ' I\n')
f.write(wordlist[m-1] + ' E\n')
else:
tmpword = tmp[i]
wordlist = list(tmpword)
m = len(wordlist)
for k in range(0, m):
f.write(wordlist[k] + ' O\n')
f.write('\n')
print "当前执行到第", row, "行"
row += 1
f.close()
1.4 遇到的问题及解决办法
问题:由于在处理预料的时候是以空格来取词的,但是每句话的最后由于直接是换行符号(“\n”),缺少一个空格导致每句话的最后的一个词无法被读入而使数据缺失,举例如下


解决办法:再写一个小程序对最原始的语料进行加工,具体的就是在每一行的句尾加上一个空格。再将加工后的数据用于转换格式,解决问题
代码如下
# coding:utf-8
import codecs
fin = codecs.open("data_nr.txt", "r")
f = codecs.open("data_to_final.txt", "a")
row = 1
while (True):
text = fin.readline()
if (text == ""):
break
tmp = list(text)
tmp.insert(-1 ,' ')#每行后加一个空格
f.writelines(tmp)
print "当前执行到第", row, "行"
row += 1
f.close()
2 使用CRF++进行实验
将语料数据集分成两份(8:2的比例),将大的集合定义为训练数据集,小的集合定义为测试数据集合
2.1 构建模板
新建一个名为template的文件用于构建模板,由于本实验只采用了字为特征,所以创建的模板也很简单,如下图

2.2 进行学习
采用相应的命令进行学习
crf_learn template data_nr_train_to_crf.data model
经历了几分钟,模型就已经训练好了,如下图

2.3 进行测试
将事先准备好的测试语料用于CRF++,使用相应命令进行测试,将结果保存到result文件中
crf_test -m model data_nr_test_to_crf.data > result
得到的结果格式是在原有的两列后再增加一列,是通过训练的模型对测试数据中的文字进行的标注结果,举例如下

2.4 遇到的问题及解决办法
问题:在进行第一次学习的时候,出现程序中途停止的问题,如下
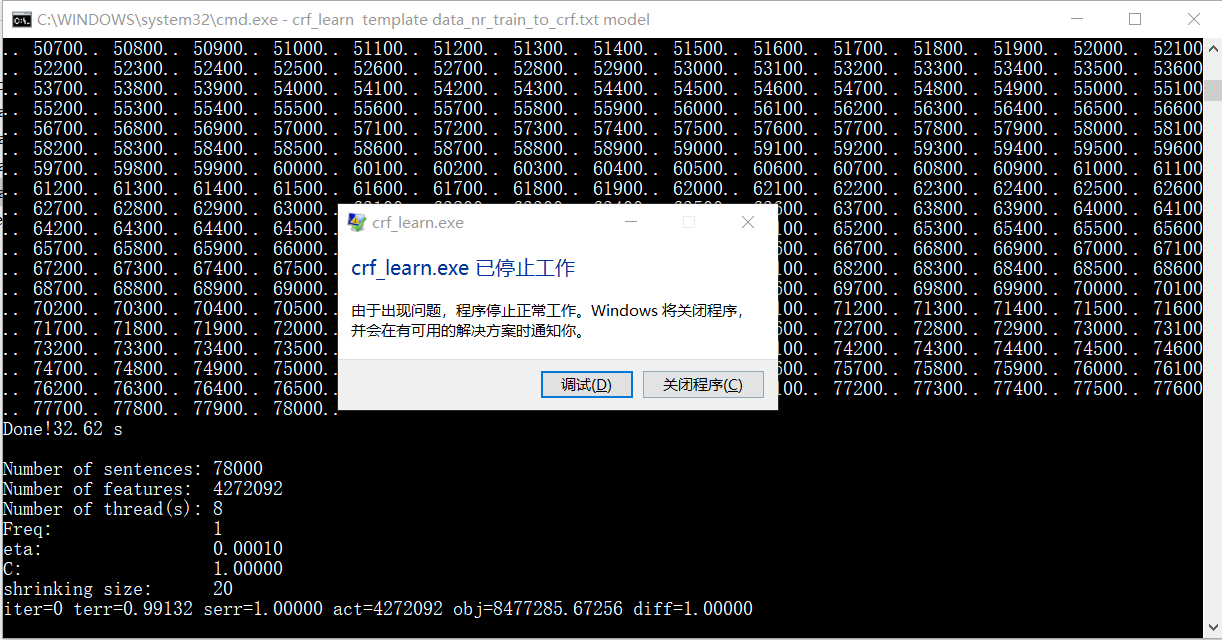
解决办法:通过查阅网络资源与进行小数据集合的实验发现导致此问题的原因应该就是,由于实验环境是在Windows的环境中进行的,数据集太大会导致程序终止。所以几次尝试后,将训练数据集减小为原来的3/4左右,再次进行学习,程序运行成功,解决问题。
3 评估
验证就是比较result文档的后两列数据,统计相同的标签个数或不同的个数,从而得到准确率、召回率、F1值。
3.1 采用conlleval.pl脚本文件进行评估
使用此文件的前提是要在机器上搭建perl环境,是在perl官方网站进行下载并安装。准备好之后,采用相关命令进行验证操作,并将结果写入evaluation中
perl conlleval.pl < result > evaluation
3.2 评估结果
打开evaluation文件,如图3-2所示,可以看到准确率为99.66%,精确率为95.12%,召回率为83.96%,F1值为89.19,导致这样的结果显然就是此次实验只用单字作为特征

3.3 遇到的问题及解决办法
问题:第一次进行评估的时候,程序运行报错,如下

解决办法:查阅相关资料,得知CRF++输出的测试结果中,相邻两行间是制表符(“\t”),而conlleval.pl要求相邻列间必须是空格,于是通过Ultraedit软件的替换功能将所有制表符替换为空格,如图3-4所示。保存文件后进行验证,解决问题。

4 总结
本次实验核心工具是CRF++,用于评估的工具采用了conlleval.pl,在语料预处理阶段采用Python编写的小程序
由于采用的单字特征,导致召回率稍低,后续可以考虑选取更多的特征(比如添加先验概率分布作为另一个特征等),来进行实验
Windows下CRF++进行中文人名识别的初次尝试的更多相关文章
- windows下git bash中文乱码解决办法
一.解决办法1:(直接上图) 1.在git bash下,右键 出现下图,选择options: 2.选择“Text” 3.将“Character set”设置为 UTF-8 转:windows下git ...
- [转]Git for windows 下vim解决中文乱码的有关问题
Git for windows 下vim解决中文乱码的问题 原文链接:Git for windows 下vim解决中文乱码的有关问题 1.右键打开Git bash: 2.cd ~ 3.vim .vim ...
- Windows下Git Bash中文乱码
文章转自:http://ideabean.iteye.com/blog/2007367 打开Git Bash 进入目录:$ cd /etc 1. 编辑 gitconfig 文件:$ vi gitcon ...
- Windows下的bat中文乱码问题
起初拿到一个bat文件,我在修改时看到编码是gb2312,我就直接将其转变为了utf8...但是在执行后的黑窗口出现中文乱码问题,最后网上获取帮助是修改编码为ANSI编码,确实不出现乱码了,ANSI是 ...
- 解决windows下FileZilla server中文乱码问题
最利用cuteftppro FTP做文件夹同步,发现中文的文件夹及文件名都出现了乱码问题, 一开始以为是cuteftppro的问题,谷哥度娘找了一堆的解决方案都没有解决乱码问题,真是头疼啊! 后来终于 ...
- 解决Windows下Tomcat控制台中文乱码
找到${CATALINA_HOME}/conf/logging.properties 添加语句:java.util.logging.ConsoleHandler.encoding = GBK 重启to ...
- VIM、GVIM在WINDOWS下中文乱码的终极解决方案
文章转自:http://www.liuhuadong.com/archives/68 vim.gvim在windows下中文乱码的终极解决方案在windows下vim的中文字体显示并不好,所以我们需要 ...
- vim、gvim 在 windows 下中文乱码的终极解决方案
vim.gvim 在 windows 下中文乱码的终极解决方案 vim ~/.vimrc 然后加入: " Gvim中文菜单乱码解决方案 " 设置文件编码格式 set encodin ...
- 基于分布式的短文本命题实体识别之----人名识别(python实现)
目前对中文分词精度影响最大的主要是两方面:未登录词的识别和歧义切分. 据统计:未登录词中中文姓人名在文本中一般只占2%左右,但这其中高达50%以上的人名会产生切分错误.在所有的分词错误中,与人名有关的 ...
随机推荐
- bzoj1018/luogu4246 堵塞的交通 (线段树)
对于一个区间四个角的点,可以用线段树记下来它们两两的联通情况 区间[l,r]通过两个子区间[l,m],[m+1,r]来更新,相当于合并[l,m],[m+1,r],用(m,m+1)这条边来合并 查询a, ...
- 【codevs2205】等差数列
题目大意:给定一个长度为 N 的序列,求这个序列中等差数列的个数. 题解:根据题意应该是一道序列计数 dp.设 \(dp[i][j]\) 表示以第 i 项结尾,公差为 j 的等差数列的个数,则状态转移 ...
- Oracle 11g DRCP配置与使用
Oracle 11g DRCP配置与使用Oracle 11g推出了驻留连接池(Database Resident Connection Pool)特性,提供了数据库层面上的连接池管理机制,为应对高并发 ...
- C++并发编程之std::future
简单地说,std::future 可以用来获取异步任务的结果,因此可以把它当成一种简单的线程间同步的手段.std::future 通常由某个 Provider 创建,你可以把 Provider 想象成 ...
- Excel:公式应用技巧汇总
1.合并单元格添加序号:=MAX(A$1:A1)+1 不重复的个数: 公式1:{=SUM(1/COUNTIF(A2:A8,A2:A8))} 公式2:{=SUM(--(MATCH(A2:A8,A2:A8 ...
- HDU 3595 every-sg模型
多个子游戏同时进行,每个子游戏给出两个数a,b,可以将大的数减去k倍小的数,不能操作者输. 策略就是对于一个必胜的游戏要使得步数更长,对于一个必败的游戏使得步数最短. 以下都来自贾志豪的论文.. 对于 ...
- SQL语句(十二)分组查询
(十二)分组查询 将数据表中的数据按某种条件分成组,按组显示统计信息 查询各班学生的最大年龄.最小年龄.平均年龄和人数 分组 SELECT <字段名表1> FROM <表名> ...
- (64位)本体学习程序(ontoEnrich)系统使用说明文档
系统运行:文件夹system下,可执行文件ontoEnrichment 概念学习 --------------------------------------------------------1.简 ...
- AtomicInteger源码
一.概念 AtomicInteger,一个提供原子操作的Integer的类.在Java语言中,++i和i++操作并不是线程安全的,在使用的时候,不可避免的会用到synchronized关键字.而Ato ...
- Convert Expression to Reverse Polish Notation
Given an expression string array, return the Reverse Polish notation of this expression. (remove the ...