Grafana分析Nginx日志
按日期对ES的index进行分割:
logstash配置:
input{
file{
path => "/home/hottopic/logs/trend-shotting-api/metric/*"
type => "trend-shotting-api-metric"
start_position => "beginning"
codec => json {
charset => "UTF-8"
}
}
}
output{
if [type] == "trend-shotting-api-metric" {
elasticsearch {
hosts=> ["172.17.213.60:9200"]
index=> "trend-shotting-api-metrick.%{+YYYY-MM}"
}
}
}
grafana源配置:(注意日期格式要统一,比如YYYY-MM或YYYY.MM)
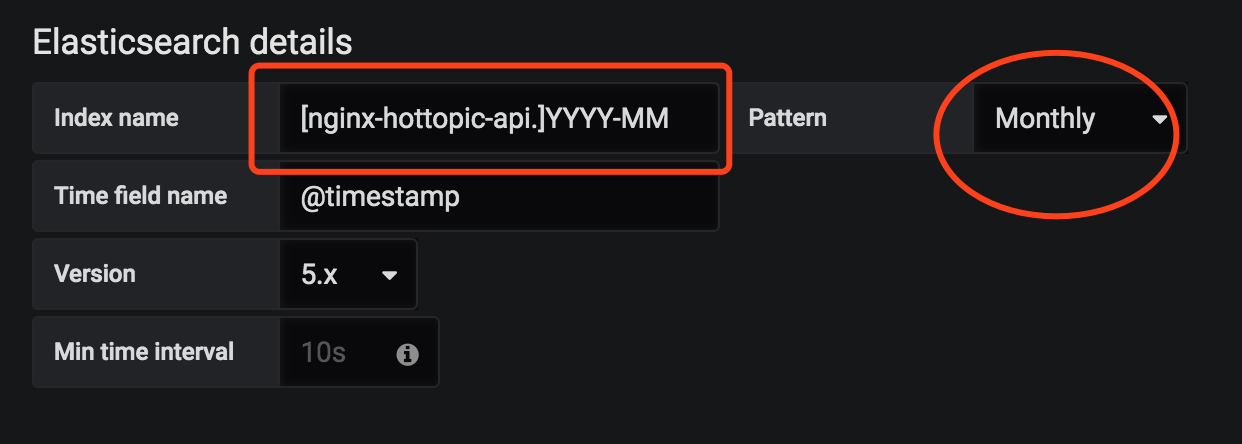
配置Groub by -Terms时报错,提示需要设置fielddata=true,报错内容大概如下:
"Fielddata is disabled on text fields by default ... "
解决方法如下:
https://www.elastic.co/guide/en/elasticsearch/reference/current/fielddata.html#_fielddata_is_disabled_on_literal_text_literal_fields_by_default
curl -X PUT "localhost:9200/nginx/_mapping/doc" -H 'Content-Type: application/json' -d'
{
"properties": {
"xforward": {
"type": "text",
"fielddata": true
}
}
}
'
操作后仍然报错,于是
curl -X PUT "localhost:9200/nginx/_mapping/doc?update_all_types" -H 'Content-Type: application/json' -d'
{
"properties": {
"xforward": {
"type": "text",
"fielddata": true
}
}
}
'
以上nginx为index名称 xforward为字段名称。
修改完后查看结果显示已修改成功

返回到Grafana进行再一次设置

修改成功后,可以正常出图。
Grafana分析Nginx日志的更多相关文章
- 烂泥:利用awstats分析nginx日志
本文由ilanniweb提供友情赞助,首发于烂泥行天下 想要获得更多的文章,可以关注我的微信ilanniweb 昨天把nginx的日志进行了切割,关于如何切割nginx日志,可以查看<烂泥:切割 ...
- elk实战分析nginx日志文档
elk实战分析nginx日志文档 架构: kibana <--- es-cluster <--- logstash <--- filebeat 环境准备:192.168.3.1 no ...
- elk平台分析nginx日志的基本搭建
一.elk套件介绍 ELK 由 ElasticSearch . Logstash 和 Kiabana 三个开源工具组成.官方网站: https://www.elastic.co/products El ...
- 一天,python搞个分析NGINX日志的脚本
准备给ZABBIX用的. 统计接口访问字次,平均响应时间,4XX,5XX次数 以后可以再改进.. #!/usr/bin/env python # coding: utf-8 ############# ...
- 利用python分析nginx日志
最近在学习python,写了个脚本分析nginx日志,练练手.写得比较粗糙,但基本功能可以实现. 脚本功能:查找出当天访问次数前十位的IP,并获取该IP来源,并将分析结果发送邮件到指定邮箱. 实现前两 ...
- hive分析nginx日志之UDF清洗数据
hive分析nginx日志一:http://www.cnblogs.com/wcwen1990/p/7066230.html hive分析nginx日志二:http://www.cnblogs.com ...
- awstat分析nginx日志
awstat分析nginx日志 http://lxw66.blog.51cto.com/5547576/1323712 server{ listen ; server_name localhost; ...
- shell脚本分析nginx日志
shell脚本分析nginx日志: name=`awk -F ',' '{print $13":"$32}' $file | awk -F ':' '{print $4}'`ech ...
- 使用Hive的正则解析器RegexSerDe分析nginx日志
1.环境: hadoop-2.6.0 + apache-hive-1.2.0-bin 2.使用Hive分析nginx日志,站点的訪问日志部分内容为: cat /home/hadoop/hivetest ...
随机推荐
- python面向对象 : 抽象类(接口类),多态,封装(私有制封装)
一. 抽象类(接口类) 与java一样, python也有抽象类的概念但是同样需要借助模块实现,抽象类是一个特殊的类, 它的特殊之处在于只能被继承, 不能被实例化. 从设计角度去看, 如果类是从现实对 ...
- 数据迁移_老集群RAC迁移数据恢复到新集群RAC
数据迁移_老集群RAC迁移数据恢复到新集群RAC 作者:Eric 微信:loveoracle11g 1.把老集群RAC备份的数据远程拷贝到新集群RAC [root@old-rac-node1 ~]# ...
- Qt Opengl
目前在Qt5中做Opengl的学习时候,发现gluPerspective函数没有定义. 1: gluPerspective( 45.0, (GLfloat)width/(GLfloat)height, ...
- 阿里云发送短信验证码php_SDK
1.登录阿里云账号下载——aliyun-dysms-php-sdk(我使用的php版本) 下载地址:https://help.aliyun.com/document_detail/55359.html ...
- Can't create handler inside thread that has not called Looper.prepare()
Looper.prepare(); // Can't create handler inside thread that has not called Looper.prepare(). Toast. ...
- WPF 自定义分页控件一
一:右键添加新建项,选择新建自定义控件,命名为:KDataPager public class KDataPager : Control { static KDataPager() { Default ...
- springboot中JPA的应用
1.JPA JPA(Java Persistence API)是Sun官方提出的Java持久化规范.它为Java开发人员提供了一种对象/关联映射工具来管理Java应用中的关系数据.他的出现主要是为了简 ...
- MySQL数据库相关开发入门
使用apt-get来进行MYSQL数据库的安装,安装好以后就可以使用数据库了. 命令行键入mysql即可进入(因为数据库初始化的没有密码的):当然为了安全,你最好还是创建一个用户和密码. 当你创建过用 ...
- linux 下的ssh免密登陆设置
一,原理 说明: A为linux服务器a B为linux服务器b 每台linux都有ssh的服务端和客户端,linux下的ssh命令就是一个客户端 我们常用ssh协议来进行登陆或者是文件的拷贝,都需要 ...
- android TextView 例子代码(文字中划线、文字下划线)
XML: <?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android ...