统计--VARCHAR与NVARCHAR在统计预估上的区别
最近遇到一个问题,当查询使用到模糊查询时,由于预估返回行数过高,执行计划认为索引查找+Key Lookup的成本过高,因此采用Clustered Index Scan的方式,消耗大量逻辑IO,执行计划较差。
经过测试,发现对于模糊查询,NVARCHAR和VARCHAR的预估返回行数差距很大,因此拿出来供大家一起测试。
首先生成测试数据,分别创建TB101和TB102的表,表上有相同的聚集索引和非聚集索引,表中有100w数据,创建测试数据脚本如下:
DROP TABLE TB101
GO
DROP TABLE TB102
GO
SELECT
CAST(NCHAR(19968+20902*RAND(RID))+NCHAR(19968+20902/2*RAND(RID))+NCHAR(19968+20902/3*RAND(RID)) AS varchar(40)) AS RName
,*
INTO TB101
FROM(
SELECT ROW_NUMBER()OVER(ORDER BY T1.OBJECT_ID DESC) AS RID,T1.* FROM sys.all_objects T2
CROSS JOIN sys.all_columns T1
) AS T
WHERE T.RID<1000000
GO
SELECT * INTO TB102 FROM TB101
GO
ALTER TABLE TB102
ALTER COLUMN RName NVARCHAR(40)
GO
CREATE UNIQUE CLUSTERED INDEX IDX_RID ON TB101(RID)
GO
CREATE UNIQUE CLUSTERED INDEX IDX_RID ON TB102(RID)
GO
CREATE INDEX IDX_Name ON TB101(RName)
GO
CREATE INDEX IDX_Name ON TB102(RName)
GO EXEC sp_spaceused 'TB101'
EXEC sp_spaceused 'TB102'
GO
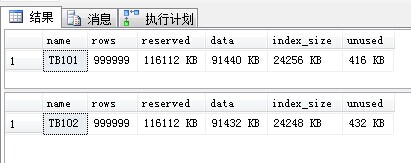
两表使用空间相同,数据相同。
测试前先更新下统计:
--更新统计
UPDATE STATISTICS TB101 WITH FULLSCAN
GO
UPDATE STATISTICS TB102 WITH FULLSCAN
开始测试1
SELECT RName FROM TB101
WHERE RName LIKE '你好%'
其执行计划为: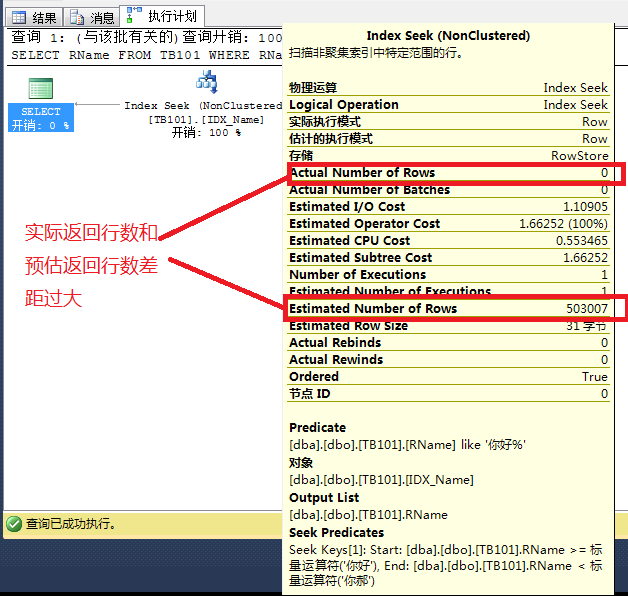
测试2:
SELECT RName FROM TB102
WHERE RName LIKE N'你好%'

感谢网友“ 害怕飞的鸟”的提醒,我们测试了以中文开头的模糊查询,需要测试以字母开头的模糊查询。
因此重新创建测试用例(生成新的测试数据目的为了避免查询值落在统计的两端,原理请参考大神高继伟的SQL Server 统计信息(Statistics)-概念,原理,应用,维护)
准备测试数据:
SELECT
CAST(NCHAR(65+25*RAND(RID))+NCHAR(24*RAND(RID))+NCHAR(19968+20902/2*RAND(RID))+NCHAR(19968+20902/3*RAND(RID)) AS varchar(40)) AS RName
,*
INTO TB103
FROM(
SELECT ROW_NUMBER()OVER(ORDER BY T1.OBJECT_ID DESC) AS RID,T1.* FROM sys.all_objects T2
CROSS JOIN sys.all_columns T1
) AS T
WHERE T.RID<1000000
GO
SELECT * INTO TB104 FROM TB103
GO
ALTER TABLE TB104
ALTER COLUMN RName NVARCHAR(40)
GO
CREATE UNIQUE CLUSTERED INDEX IDX_RID ON TB103(RID)
GO
CREATE UNIQUE CLUSTERED INDEX IDX_RID ON TB104(RID)
GO
CREATE INDEX IDX_Name ON TB103(RName)
GO
CREATE INDEX IDX_Name ON TB104(RName)
GO
测试1:
SELECT RName FROM TB103
WHERE RName LIKE 'A你好%'

测试2:
SELECT RName FROM TB104
WHERE RName LIKE N'A你好%'

通过上面四个测试,可以得出以下结论:
1. 当字段的数据类型为NVARCHAR时,无论模糊查询以中文还是英文字母开头,预估返回行数和实际返回行数相差不多
2. 当字段的数据类型为VARCHAR且模糊查询以英文字母开头,预估返回行数和实际返回行数相差不多
3. 当字段的数据类型为VARCHAR且模糊查询以中文开头,预估返回行数和实际返回行数相差较大。
--==============================================================
当预估返回行数与实际返回行数相差较大时,就很容易生成较差的执行计划,如对于查询:
SELECT * FROM TB101
WHERE RName LIKE '你好%'
由于预估索引查找会返回50w的数据,查询优化器引擎认为如果使用索引查找+Key Lookup就会消耗上200W+的逻辑IO, 效率会远低于表扫描,因此有了下面的执行计划:
而实际上,经过索引查找后,只会返回少量的数据行,这些行做Key Lookup也只会消耗少量的逻辑IO,因此索引查找+Key Lookup是最高效的。
解决办法:
对于这种问题,可以有几种办法处理:
1. 强制索引查找
SELECT * FROM TB101 WITH(FORCESEEK)
WHERE RName LIKE '你好%'
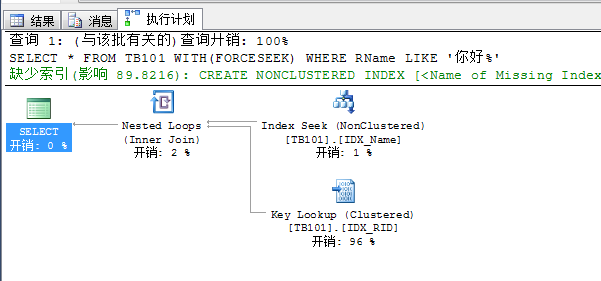
2. 使用隐式转化
SELECT * FROM TB101
WHERE RName LIKE N'你好%'

经过一次隐式转换后,预估返回行数出奇地下降下来,生成了正确的执行计划(看来隐式转换也是有存在价值地哦)
3. 如果不想修改程序的话,可以考虑使用参数化和执行计划指南来实现
--=========================================================================================
总结(以下结论未经过大神认证,请自行组鉴别正确性):
1. 当字段的数据类型为NVARCHAR时,无论模糊查询以中文还是英文字母开头,预估返回行数和实际返回行数相差不多
2. 当字段的数据类型为VARCHAR且模糊查询以英文字母开头,预估返回行数和实际返回行数相差不多
3. 当字段的数据类型为VARCHAR且模糊查询以中文开头,预估返回行数和实际返回行数相差较大。
4. 隐式转换未必会导致表扫描或索引扫描,也未必会导致执行计划质量不优。
--===========================================================


统计--VARCHAR与NVARCHAR在统计预估上的区别的更多相关文章
- SQL Server 执行计划利用统计信息对数据行的预估原理二(为什么复合索引列顺序会影响到执行计划对数据行的预估)
本文出处:http://www.cnblogs.com/wy123/p/6008477.html 关于统计信息对数据行数做预估,之前写过对非相关列(单独或者单独的索引列)进行预估时候的算法,参考这里. ...
- SQL Server 执行计划利用统计信息对数据行的预估原理以及SQL Server 2014中预估策略的改变
前提 本文仅讨论SQL Server查询时, 对于非复合统计信息,也即每个字段的统计信息只包含当前列的数据分布的情况下, 在用多个字段进行组合查询的时候,如何根据统计信息去预估行数的. 利用不同字段 ...
- 数据库char varchar nchar nvarchar,编码Unicode,UTF8,GBK等,Sql语句中文前为什么加N(一次线上数据存储乱码排查)
背景 公司有一个数据处理线,上面的数据经过不同环境处理,然后上线到正式库.其中一个环节需要将数据进行处理然后导入到另外一个库(Sql Server).这个处理的程序是老大用python写的,处理完后进 ...
- 全废话SQL Server统计信息(2)——统计信息基础
接上文:http://blog.csdn.net/dba_huangzj/article/details/52835958 我想在大地上画满窗子,让所有习惯黑暗的眼睛都习惯光明--顾城<我是一个 ...
- 全废话SQL Server统计信息(1)——统计信息简介
当心空无一物,它便无边无涯.树在.山在.大地在.岁月在.我在.你还要怎样更好的世界?--张晓风<我在> 为什么要写这个内容? 随着工作经历的积累,越来越感觉到,大量的关系型数据库的性能问题 ...
- sql中NVARCHAR(MAX) 性能和占空间分析 varchar(n),nvarchar(n) 长度性能及所占空间分析
varchar(n),nvarchar(n) 中的n怎么解释: nvarchar(n)最多能存n个字符,不区分中英文. varchar(n)最多能存n个字节,一个中文是两个字节. 所占空间: nvar ...
- 答:SQLServer DBA 三十问之一: char、varchar、nvarchar之间的区别(包括用途和空间占用);xml类型查找某个节点的数据有哪些方法,哪个效率高;使用存储 过程和使用T-SQL查询数据有啥不一样;
http://www.cnblogs.com/fygh/archive/2011/10/18/2216166.html 1. char.varchar.nvarchar之间的区别(包括用途和空间占用) ...
- varchar和Nvarchar区别
http://www.cnblogs.com/yelaiju/archive/2010/05/29/1746826.html Unicode字符集就是为了解决字符集这种不兼容的问题而产生的,它所有的字 ...
- sql-char和varchar,nvarchar的区别
数据类型的比较 char表示的是固定长度,最长n个字 varchar表示的是实际长度的数据类型 比如:如果是char类型,当你输入字符小于长度时,后补空格:而是varchar类型时,则表示你输入字符的 ...
随机推荐
- MySQL 索引 INDEX
索引用于快速找出在某列中有特定值的行. 不使用索引,MySQL必须从第一条记录开始读完整个表,直到找到相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的列有一个索引,MySQL能够快速到达一 ...
- [Python] 代码中有中文注释会报错
原因 如果文件里有非ASCII字符,需要在第一行或第二行指定编码声明. 解决方法 在第一行或是第二行加入这么一句# -- coding: utf-8 -- ASCII知识普及: ASCII(Ameri ...
- Python之路(第十三篇)time模块、random模块、string模块、验证码练习
一.time模块 三种时间表示 在Python中,通常有这几种方式来表示时间: 时间戳(timestamp) : 通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量.(从 ...
- NETSHARP微信开发说明
一.微信开发介绍 1.微信分为个人号,订阅号.服务号,需要去理解三个号的区别,对于开发来说也需要了解不同的账号所提供的功能 2.微信号需要审批,审批之后有一些功能才能使用 3.微信提供的功能及使用情况 ...
- ros主从关系
主机: 在~/.bashrc里面输入 export ROS_MASTER_URI=http://localhost:11311export ROS_HOSTNAME=192.168.4.1 其ip地址 ...
- Android中关于使用空格对齐文字
前言:今日编写新项目UI时,突然遇到文本有长有短无法对齐的问题(汗,以前竟从未遇到也从未考虑过这小小的问题),在资源文件中尝试Tab键.space空格键,发现效果都不能很好的实现,无奈只得请求度娘的协 ...
- ubuntu 配置ftp server(zz)
ubuntu 配置 ftp server 安装vsftpd sudo apt-get install vsftpd # vsftp(Very Secure FTP)是一种在Unix/Linux中非 ...
- spring学习 十四 注解AOP 通知传递参数
我们在对切点进行增强时,不建议对切点进行任何修改,因此不加以使用@PointCut注解打在切点上,尽量只在Advice上打注解(Before,After等),如果要在通知中接受切点的参数,可以使用Jo ...
- 19 模块之shelve xml haslib configparser
shelve 什么是shelve模块 也是一种序列化方式使用方法 1.opne 2.读写 3.close特点:使用方法比较简单 提供一个文件名字就可以开始读写 读写的方法和字典一致 你可以把它当成带有 ...
- chmod / chown /chattr
显示了七列信息,从左至右依次为:权限.文件数.归属用户.归属群组.文件大小.创建日期.文件名称 d :第一位表示文件类型 d 文件夹 - 普通文件 l 链接 b 块设备文件 p 管道文件 c 字符设备 ...