爬虫初窥day3:BeautifulSoup
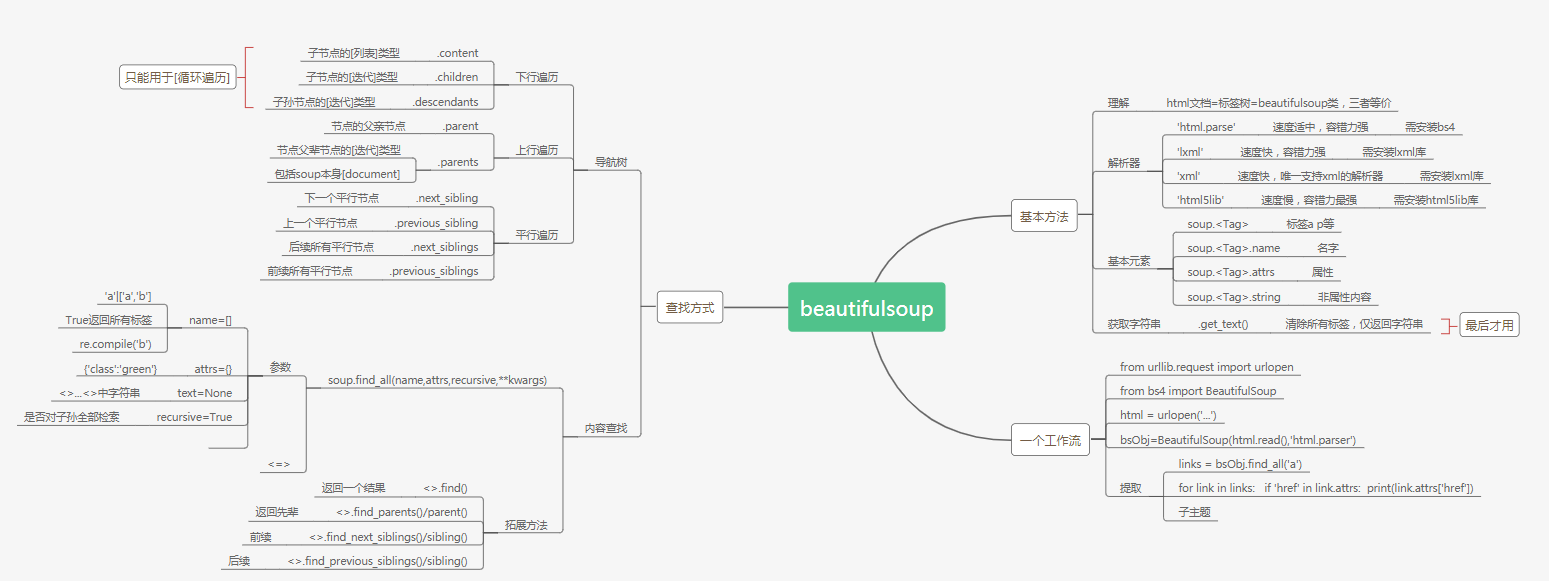
信息提取
1.通过Tag对象的属性和方法
#!/usr/bin/python
# -*- coding: utf- -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen('https://www.cnblogs.com/pcat/p/5398997.html')
soup = BeautifulSoup(html.read().decode('utf-8'),'html.parser')#避免乱码,先utf-8解码 #print()输出第一个匹配项
print(soup)
print(soup.a)
print(soup.a.name)
print(soup.a.attrs)
print(soup.a.string) soup.html.get_text()输出字符串,原文排版
2.通过标签树对象的find_all()方法
aS = soup.find_all('a')
for i in aS:
print(i)
#print(i.name)
#print(i.attrs)
#print(i.string)
#find_all带条件(name,attrs,string,text,recursive,可多条件匹配)
hrefs = soup.find_all(href=re.compile('pcat$'))#以pcat结尾的链接
for i in hrefs:
print(i)
#对css类名属性class进行搜索时,为避免与python保留字冲突,需用class_
a = soup.find_all(class_ = 'postDesc')
print(a)
#补充1.text匹配非属性内容。.["a","b"]的形式,表示匹配多个值
3.通过标签树对象的find()方法
#find返回一个标签节点,find_all返回多值列表
#find
e1 =soup.find('head').find('title')#在标签名为head的tag中查找title标签
print(e1)
4.通过CSS选择器
#标签名
soup.select('p')#搜索所有标签名为p的标签
soup.select('p a')#搜索所有p标签的子孙节点中标签名为a的标签。即下N层
soup.select('p > a')#搜索所有p标签的直接子节点中标签名为a的标签。即下一层
#类名
soup.select('.blogStats ')#所有类名为blogStats的标签
soup.select('.blogStats span')#所有类名为blogStats且子孙节点中标签名为span的标签
soup.select('a.menu')#标签名为a并且类名为menu的标签
e1=soup.select('a.menu')#标签名为a并且类名为menu的标签
for i in e1:
print(i['href'])
#id
soup.select('#stats_post_count')#所有id为xxx的标签
soup.select('#navList #blog_nav_sitehome')#所有id为xxx且其子孙节点id为xxx的标签
#属性
soup.select('a[href]')#标签名为a且属性中存在href的所有标签
soup.select('a[href="https://www.cnblogs.com/pcat/"]')#标签名为a且href属性值为http://...的所有标签
soup.select('a[href^="http"]')#标签名为a且href属性以http开头的标签
soup.select('a[href$="http"]')#标签名为a且href属性以pcat结尾的标签
soup.select('a[href*="cnblogs"]')#标签名为a且href属性包含example的标签
#标签名/类名/id/属性 空格[ ] 右符号'>' 相互搭配
遍历
1.下行遍历
| <tag>.contents | 以列表形式返回Tag的所有子节点 |
| <tag>.children | 以迭代形式返回Tag的所有子节点 |
| <tag>.descendants | 以迭代形式返回Tag的所有子孙节点 |
| <tag>.strings | 以迭代形式返回Tag及其所有子孙节点的非属性字符串 |
| <tag>.stripped_strings | 以迭代形式返回Tag去除空白字符后的非属性字符串 |
\c
#contents
e1=soup.ul.contents
print(type(e1))
print(len(e1))
#children
e1=soup.ul.children
for i in e1:
print(i)
#descendants
e1=soup.ul.descendants
for i in e1:
print(i)
#strings
e1=soup.ul.strings
for i in e1:
print(i)
#stripped_strings
e1=soup.ul.stripped_strings
for i in e1:
print(i)
\c
2.上行遍历
| parent | 以列表形式返回tag的所有父亲节点 |
| parents | 以迭代形式返回tag的所有父辈节点 |
\c
3.水平遍历
| next_sibling | 按文档顺序,返回Tag的下一个相邻兄弟节点 |
| previous_sibling | 按文档顺序,返回Tag的上一个相邻兄弟节点 |
| next_siblings | 按文档顺序,返回Tag的后续兄弟节点 |
| previous_siblings | 按文档顺序,返回Tag的前续兄弟节点 |
爬虫初窥day3:BeautifulSoup的更多相关文章
- 爬虫初窥day4:requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 ...
- 爬虫初窥day2:正则
正则在线测试 http://tool.oschina.net/regex https://www.regexpal.com/ http://tool.chinaz.com/regex exp1:筛选所 ...
- 爬虫初窥day1:urllib
模拟“豆瓣”网站的用户登录 # coding:utf-8 import urllib url = 'https://www.douban.com/' data = urllib.parse.urlen ...
- python爬虫 scrapy2_初窥Scrapy
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- Scrapy001-框架初窥
Scrapy001-框架初窥 @(Spider)[POSTS] 1.Scrapy简介 Scrapy是一个应用于抓取.提取.处理.存储等网站数据的框架(类似Django). 应用: 数据挖掘 信息处理 ...
- scrapy2_初窥Scrapy
递归知识:oop,xpath,jsp,items,pipline等专业网络知识,初级水平并不是很scrapy,可以从简单模块自己写. 初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数 ...
- Scrapy 1.4 文档 01 初窥 Scrapy
初窥 Scrapy Scrapy 是用于抓取网站并提取结构化数据的应用程序框架,其应用非常广泛,如数据挖掘,信息处理或历史存档. 尽管 Scrapy 最初设计用于网络数据采集(web scraping ...
- python2.7 爬虫初体验爬取新浪国内新闻_20161130
python2.7 爬虫初学习 模块:BeautifulSoup requests 1.获取新浪国内新闻标题 2.获取新闻url 3.还没想好,想法是把第2步的url 获取到下载网页源代码 再去分析源 ...
- R语言爬虫初尝试-基于RVEST包学习
注意:这文章是2月份写的,拉勾网早改版了,代码已经失效了,大家意思意思就好,主要看代码的使用方法吧.. 最近一直在用且有维护的另一个爬虫是KINDLE 特价书爬虫,blog地址见此: http://w ...
随机推荐
- azkaban编译以及安装(调度系统)
编译源码 下载azkaban源码 git clone https://github.com/azkaban/azkaban.git jdk要求是1.8以上版本 export JAVA_HOME=/ ...
- BOM进IN_BOM_HEADER表后被过滤掉
1.查看如下两个表发现BOM被过滤掉了 SELECT PRODUCT_ID||'_'||substr(BOM_ID,1,8),A.* FROM IN_BOM_HEADER A WHERE A.PRO ...
- Jmeter(二十五)常见问题(转载)
转载自 http://www.cnblogs.com/yangxia-test 收集工作中JMeter遇到的各种问题 1. JMeter的工作原理是什么? 向服务器提交请求:从服务器取回请求返回 ...
- day31 粘包问题
TCP粘包问题 cmd客户端代码 import socket import struct import socket import json c = socket.socket() c.connect ...
- hibench 对CDH5.13.1进行基准测试(测试项目hadoop\spark\)HDFS作HA高可靠性
使用CDH 5.13.1部署了HADOOP集群之后,需要进行基准性能测试. 一.hibench 安装 1.安装位置要求. 因为是全量安装,其中有SPARK的测试(SPARK2.0). 安装位置在SPA ...
- RedHat 更新CentOS Yum源(转)
经测试,可用.转自:https://www.cnblogs.com/tangsen/p/5151994.html 一.随笔引言 1.1随笔内容: 1.RedHat 配置Centos yum源 2.yu ...
- c# tcp协议发送数据
private void tcp_send(string data)//tcp协议转发数据 { TcpClient tcpClient = new TcpClient(); tcpClient.Con ...
- linux下面redis安装
安装方法1redis1.下载安装包2.解压程序包tar -zxvf redis-3.2.6.tar.gz3.编译源程序make(编译失败,查看是否安装gcc 如果没有yum install gc ...
- Android模拟器故障:waiting for target deviceto come online
关闭再打开模拟器.删除再新建模拟器均无效. 解决办法:在AVD Manager中,选择立即冷启动(Cold Boot Now)模拟器.
- iOS 10 之后权限设置
iOS 10 之后权限设置 麦克风权限:Privacy - Microphone Usage Description 是否允许此App使用你的麦克风? 相机权限: Privacy - Camera U ...