CentOS7 安装 hbase1.3.3
1. 集群规划
| ip地址 | 机器名 | 角色 |
| 192.168.1.101 | palo101 | hadoop namenode, hadoop datanode, yarn nodeManager, zookeeper, hive, hbase master,hbase region server |
| 192.168.1.102 | palo102 | hadoop namenode, hadoop datanode, yarn nodeManager, yarn resource manager, zookeeper, hive, hbase master,hbase region server |
| 192.168.1.103 | palo103 | hadoop namenode, hadoop datanode, yarn nodeManager, zookeeper, hive,hbase region server,mysql |
2. 环境准备
安装JDK
hbase和hadoop存在版本依赖关系,所有安装之前请先确定好hbase和hadoop是否支持,具体版本支持关系可以到hbase官方页面上查看: https://hbase.apache.org/book.html#basic.prerequisites, 在页面中搜索: Hadoop version support matrix 即可。
当前的hadoop和hbase的版本关系如下;
3. 下载hbase1.3.3
注意:3,4两步都在192.168.1.101上操作,配置好hbase后,通过scp复制到其他两台机器上去
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/1.3.3/hbase-1.3.3-bin.tar.gz
mkdir -p /usr/local/hbase/
tar xzvf hbase-1.3.-bin.tar.gz
mv hbase-1.3.-bin /usr/local/hbase/hbase-1.3.
4. 配置hbase
4.1 编辑hbase.env.sh
vim /usr/local/hbase/hbase-1.3./conf/hbase-env.sh
#加入JAVA_HOME的路径,本机中的JAVA_HOME路径为,
export JAVA_HOME=/usr/java/jdk1..0_172-amd64
#关闭HBase自带的Zookeeper,使用Zookeeper集群
export HBASE_MANAGES_ZK=false
HBASE_MANAGES_ZK变量, 此变量默认为true,告诉HBase是否启动/停止ZooKeeper集合服务器作为HBase启动/停止的一部分。如果为true,这Hbase把zookeeper启动,停止作为自身启动和停止的一部分。如果设置为false,则表示独立的Zookeeper管理。
#设置HBASE_PID_DIR目录
export HBASE_PID_DIR=/var/hadoop/pids
注释掉下面两行
# export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
# export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
这两个配置是用于jdk1.7的,本例中用的是jdk1.8,所以去掉这两个配置项;
#修改Hbase堆设置,将其设置成4G,
export HBASE_HEAPSIZE=4G
整体内容如下:
#JAVA_HOME
export JAVA_HOME=/usr/java/jdk1..0_172-amd64 #关闭HBase自带的Zookeeper,使用外部Zookeeper集群
export HBASE_MANAGES_ZK=false #设置HBASE_PID_DIR目录
export HBASE_PID_DIR=/var/hadoop/pids #Hbase日志目录
export HBASE_LOG_DIR=/usr/local/hbase/hbase-1.3./logs #HBASE_CLASSPATH
export HBASE_CLASSPATH=/usr/local/hbase/hbase-1.3./conf #HBASE_HOME
export HBASE_HOME=/usr/local/hbase/hbase-1.3. #HADOOP_HOME
export HADOOP_HOME=/opt/softwre/hadoop-2.7. #set hbase heep size
export HBASE_HEAPSIZE=4G
4.2 编辑hbase-site.xml
vim /usr/local/hbase/hbase-1.3./conf/hbase-site.xml
加入以下配置信息
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://192.168.1.101:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value></value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>192.168.1.101,192.168.1.102,192.168.1.103</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/software/zookeeper-3.4./data</value>
</property>
<property>
<name>hbase.master.maxclockskew</name>
<value></value>
</property>
</configuration>
注意:
a) hbase.zookeeper.property.dataDir,即之前安装的zookeeper集群的数据目录,本例中是/opt/software/zookeeper-3.4.12/data
b) 必须指定zookeeper的端口号,如果不添加hbase.zookeeper.property.clientPort配置节,也可以直接在hbase.zookeeper.quorum配置节中指定,形如192.168.1.101:2181,192.168.1.102:2181,多个机器之间用逗号分隔
c) hbase.rootdir配置节这个参数是用来设置RegionServer 的共享目录,用来存放HBase数据。格式必须是hdfs://{HDFS_NAME_NODE_IP}:{HDFS_NAME_NODE_PORT}/{HBASE_HDFS_ROOT_DIR_PATH},否则,hbase将访问不到hdfs,安装失败(hbase依赖hdfs做存储).本例中hdfs namenode部署在192.168.1.101上,端口为默认端口9000,hbase的根路径是/hbase,所以配置为hdfs://192.168.1.101:9000/hbase
e) hbase.cluster.distributed: HBase 的运行模式。为 false 表示单机模式,为 true 表示分布式模式。
4.3 编辑regionservers
vim /usr/local/hbase/hbase-1.3./conf/regionservers
添加以下内容:
192.168.1.101
192.168.1.102
192.168.1.103
5. 将配置好的hbase复制到其他两台机器
将配置好的hbase复制到192.168.1.102,192.168.1.103
scp -r /usr/local/hbase 192.168.1.102:/usr/local/
scp -r /usr/local/hbase 192.168.1.103:/usr/local/
6.配置环境变量
vim /etc/profile
在文件末尾添加
#hbase
export HBASE_HOME=/usr/local/hbase/hbase-1.3.
export PATH=$HBASE_HOME/bin:$PATH
:wq保存退出.
在终端输入 source /etc/profile使环境变量生效。
注意:每台机器都需要操作
7. 配置时间同步
我们在使用HDFS的时候经常会出现一些莫名奇妙的问题,通常可能是由于多台服务器的时间不同步造成的。我们可以使用网络时间服务器进行同步。
yum -y install ntp ntpdate #安装ntpdate时间同步工具
ntpdate cn.pool.ntp.org #设置时间同步
hwclock --systohc #将系统时间写入硬件时间
timedatectl #查看系统时间
注意:上面操作每台机器都需要做.
8. 启动hbase
在192.168.1.101上启动hbase
$HBASE_HOME/bin/start-hbase.sh
输出如下:
[root@palo101 conf]# $HBASE_HOME/bin/start-hbase.sh
palo101: starting zookeeper, logging to /usr/local/hbase/hbase-1.3./bin/../logs/hbase-root-zookeeper-palo103.out
palo102: starting zookeeper, logging to /usr/local/hbase/hbase-1.3./bin/../logs/hbase-root-zookeeper-palo101.out
palo103: starting zookeeper, logging to /usr/local/hbase/hbase-1.3./bin/../logs/hbase-root-zookeeper-palo102.out
starting master, logging to /usr/local/hbase/hbase-1.3./logs/hbase-root-master-palo102.out
Java HotSpot(TM) -Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
Java HotSpot(TM) -Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
192.168.1.101: starting regionserver, logging to /usr/local/hbase/hbase-1.3./bin/../logs/hbase-root-regionserver-palo101.out
192.168.1.103: starting regionserver, logging to /usr/local/hbase/hbase-1.3./bin/../logs/hbase-root-regionserver-palo103.out
192.168.1.102: starting regionserver, logging to /usr/local/hbase/hbase-1.3./bin/../logs/hbase-root-regionserver-palo102.out
192.168.1.101: Java HotSpot(TM) -Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
192.168.1.101: Java HotSpot(TM) -Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
192.168.1.103: Java HotSpot(TM) -Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
192.168.1.103: Java HotSpot(TM) -Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
192.168.1.102: Java HotSpot(TM) -Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
192.168.1.102: Java HotSpot(TM) -Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
9. 查看hbase版本
在任意机器上输入
$HBASE_HOME/bin/hbase shell
[root@palo103 conf]# $HBASE_HOME/bin/hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hbase/hbase-1.3./lib/slf4j-log4j12-1.7..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/workspace/hadoop-2.7./share/hadoop/common/lib/slf4j-log4j12-1.7..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/workspace/apache-hive-2.3.-bin/lib/log4j-slf4j-impl-2.6..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.3., rfd0d55b1e5ef54eb9bf60cce1f0a8e4c1da073ef, Sat Nov :: CST hbase(main)::> version
1.3., rfd0d55b1e5ef54eb9bf60cce1f0a8e4c1da073ef, Sat Nov :: CST
10. hbase监控界面
通过浏览器打开http://{HBASE_MASTER_IP}:16010可以查看hbase的监控信息,本例中是http://192.168.1.101:16010/,打开后截图如下:
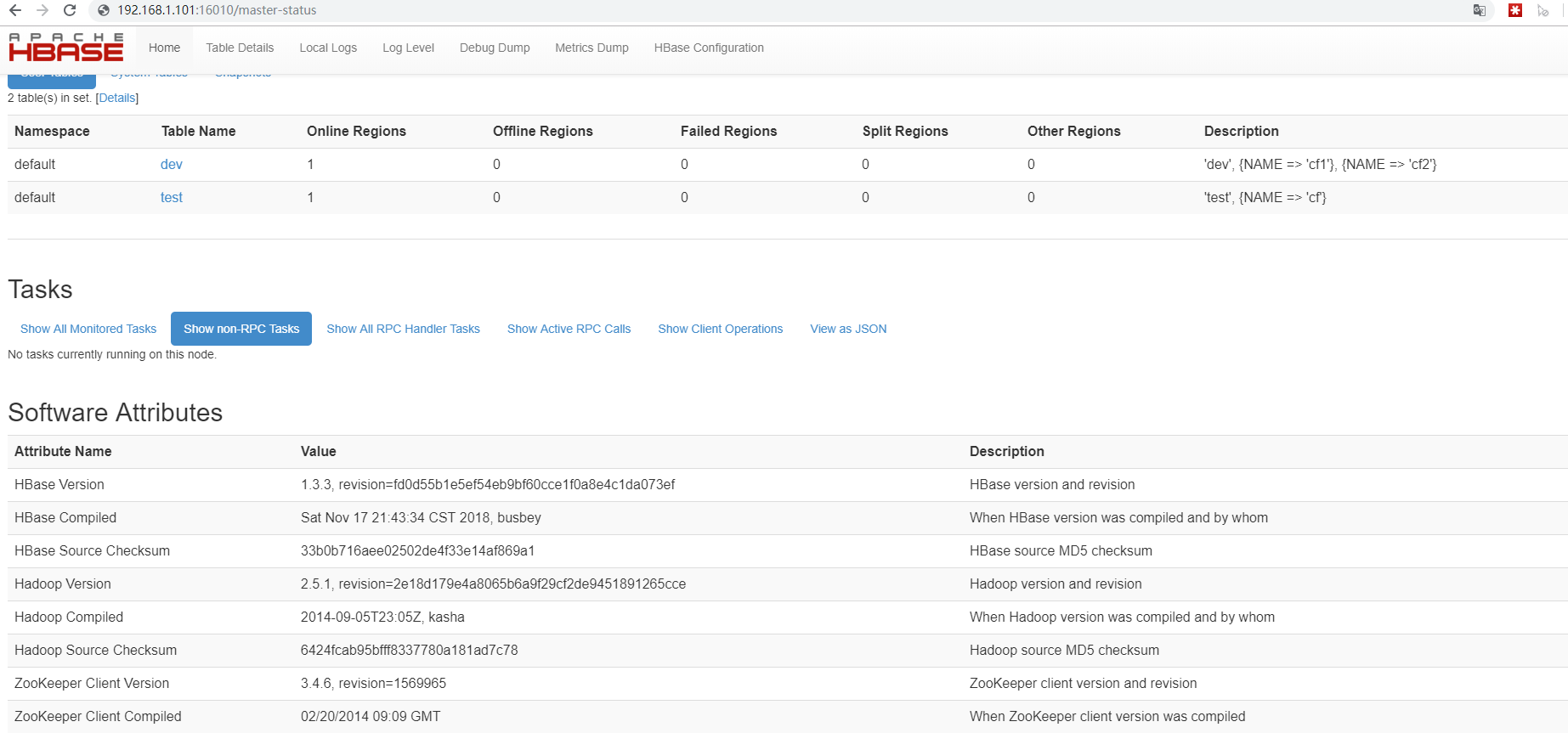
安装完成!
CentOS7 安装 hbase1.3.3的更多相关文章
- Centos7安装HBase1.4
准备 1.hadoop集群已安装,这里将在Centos7安装Hadoop2.7的基础上安装hbase1.4,所以是同样的三台机器,其规划如下: hostname IP地址 部署规划 node1 172 ...
- HP服务器 hp 360g5 centos7安装问题
HP服务器 hp 360g5 centos7安装问题 一 :启动盘无法识别硬盘 1.进入安装光盘,用上下键选择安装centos--Install Centos7(注意不可按Enter键),如图: 2 ...
- CentOS7 安装Mono及Jexus
CentOS7安装Mono及Juxes 1 安装Mono 1.1 安装yum-utils 因为安装要用到yum-config-manager,默认是没有安装的,所以要先安装yum-utils包.命令如 ...
- CentOS7安装mysql提示“No package mysql-server available.”
针对centos7安装mysql,提示"No package mysql-server available."错误,解决方法如下: Centos 7 comes with Mari ...
- CentOS7安装Oracle 11gR2 安装
概述 Oracle 在Linux和window上的安装不太一样,公司又是Linux系统上的Oracle,实在没辙,研究下Linux下Oracle的使用,oracle默认不支持CentOS系统安装,所以 ...
- Centos7安装完毕后重启提示Initial setup of CentOS Linux 7 (core)的解决方法
问题: CentOS7安装完毕,重新开机启动后显示: Initial setup of CentOS Linux 7 (core) 1) [x] Creat user 2) [!] License i ...
- centos7安装eclipse
centos7安装eclipse Eclipse是一个集成开发环境(IDE),包含一个基工作区和定制环境的可扩展插件系统.大部分使用 Java 编写,Eclipse 可以用来开发应用程序.通过各种插件 ...
- CentOS7安装mongoDB数据库
CentOS7安装mongoDB数据库 时间:2015-03-03 16:45来源:blog.csdn.net 作者:进击的木偶 举报 点击:8795次 mongoDB是目前发展比较好的NOSQL数据 ...
- CentOS7安装Ambari
环境: CentOS7安装两个节点:master.slave1.并配置ssh无密码登录. 步骤: 获取 Ambari 的公共库文件(public repository): wget http://pu ...
随机推荐
- CloudStack学习-2
环境准备 这次实验主要是CloudStack结合glusterfs. 两台宿主机,做gluster复制卷 VmWare添加一台和agent1配置一样的机器 系统版本:centos6.6 x86_64 ...
- linux修改文件所有者和文件所在组 【转载】
chgrp 用户名 文件名 -R chown 用户名 文件名 -R -R表示递归目录下所有文件 以上部分已验证 地址原贴
- spring-boot-dependencies jar 不完整的问题
集成 springboot 有两种方式. 1 直接 父项目指向 springboot <parent> <groupId>org.springframework.boot&l ...
- Linux下安装CollabNetSubversionEdge
1.首先下载CollabNet Subversion,目前最新版本Subversion Edge 5.2.2 (Linux 64-bit),注意下载的时候需要注册下账号,才允许下载: 2.安装Coll ...
- ubuntu16 安装matplotlib
在安装ubuntu安装matplotlib时碰到不少问题,简单做个备忘: 需要先安装其依赖的包libpng和freetype 安装libpng: sudo apt-get install libpng ...
- python re 实例
#!/usr/bin/env python#_*_coding:utf-8_*_ import reimport timeimport jsonimport MySQLdbimport context ...
- DEVC++ C++ Builder6.0
Devc++安装后无法正常编译程序 出现错误,不知道是什么,可能是不兼容的原因 然后就是一直编译出错,程序是最简单的helloworld程序. 之后选择安装C++ Builder 6.0
- VS2012打开项目——已停止工作
VS2012打开项目——已停止工作 解决方法如下: 1. 开始-->所有程序-->Microsoft Visual Studio 2012-->Visual Studio Tools ...
- Azure SQL 数据库仓库Data Warehouse (2) 架构
<Windows Azure Platform 系列文章目录> 在上一篇文章中,笔者介绍了MPP架构的基本内容 在本章中,笔者给大家介绍一下Azure SQL Data Warehouse ...
- 黄聪:超实用的PHPExcel[导入][导出]实现方法总结
首先需要去官网https://github.com/PHPOffice/PHPExcel/下载PHPExcel,下载后只需要Classes目录下的文件即可. 1.PHPExcel导出方法实现过程 /* ...