hadoop之完全分布式集群配置(centos7)
一、基础环境
现在我们有两台虚拟机了,再克隆两台:

克隆好之后需要做三件事:1、更改主机名称 2、修改ip地址 3、将ip地址和对应的主机号加入到/etc/hosts文件中
1、永久修改主机名
hostnamectl set-hostname hadoop03 等等
2、修改ip地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
删除掉UUID,然后注意红色框中的

3、将ip地址和主机名加入到/etc/hosts中
vim /etc/hosts
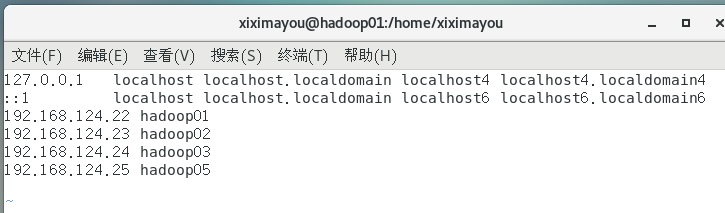
(图中最后应该是hadoop04)
同理对于hadoop04也这么做。hadoop02是我之前学习伪分布式时已经克隆配置好了的。也要在hadoop01和hadoop02中将这四个也添加上去。hadoop01是克隆源,里面的UUID不可删去。
二、集群配置
1、集群部署规划
| hadoop02 | hadoop03 | hadoop04 | |
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN | NodeManager |
ResourceManager NodeManager |
NodeManager |
说明:NameNode和SecondaryNameNode要求不在一个节点上。ResourceManager不能和NameNode、SecondaryNameNode在同一个节点上。
2、修改hadoop02中的配置
在hadoop-2.9.2目录下:vim etc/hadoop/core-site.xml
<!--指定HDFS中NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop02:9000</value>
</property>
<!--指定hadoop运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.9.2/data/tmp</value>
</property>
在vim etc/hadoop/hadoop-env.sh中配置JAVA_HOME路径
在vim etc/hadoop/hdfs-site.xml中
<configuration>
<!--备份的个数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--辅助节点的位置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop04:50090</value>
</property>
</configuration>
在vim etc/hadoop/yarn-env.sh中配置JAVA_HOME路径
在vim etc/hadoop/yarn-site.xml中配置
<configuration>
<!--Reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定yarn的ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop03</value>
</property>
</configuration>
在vim etc/hadoop/mapred-env.sh中配置JAVA_HOME路径
vim etc/hadoop/mapred-site.xml中配置
<!--指定MR运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3、配置好hadoop02,利用之前博客中的集群分发脚本将配置文件传给hadoop03、hadoop04
xsync.sh /opt/module/hadoop-2.9.2/etc/hadoop/
然后去hadoop03和hadoop04中查看是否成功:
4、在hadoop02、hadoop03、hadoop04中删除掉之前运行的data和logs文件夹,在/opt/modul/hadoop-2.9.2/下
rm -rf data logs
5、集群节点启动
可使用jps指令查看节点是否启动。
(1)在hadoop02中:
首先格式化namenode:bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
(2) 在hadoop03中:
sbin/hadoop-daemon.sh start datanode
(3)在hadoop04中:
sbin/hadoop-daemon.sh start datanode
(4)关闭hadoop02中的防火墙
三、查看
在windows中输入http://192.168.124.23:50070/,若出现以下界面:

四、ssh无密码登录
问题:我们都是一个个去别的虚拟机启动节点,当节点很多时,我们要一个个去输入?
事实上,在当前虚拟机中终端中输入:ssh 主机名就可以登录到其他虚拟机
比如,当前的是hadoop02,那么输入ssh hadoop03,就可以登录到hadoop03,只不过每次切换的时候都需要输入密码。为了避免麻烦,可以部署免密登录,只需要输入一次密码,之后再次登录就不需要密码了。那么如何进行操作呢?
免密登录原理:

先来到hadoop02: 输入ls -al查看隐藏的文件,有一个.ssh。cd .ssh

里面有你访问过的主机名称。
生成相应的密钥:ssh-keygen -t rsa
然后输入三次回车。
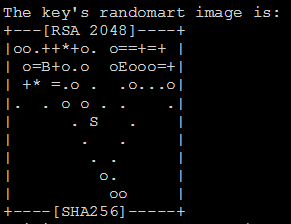

id_rsa就是私钥,id_rsa.pub就是公钥
将id_rsa.pub中的内容拷贝到hadoop03和hadoop04中:
在hadoop02的.ssh目录下输入:
ssh-copy-id hadoop03
ssh-copy-id hadoop04
然后我们再输入ssh hadoop03
发现就不需要再输入密码了,并且在.ssh目录下会生成一个authorized_keys:里面存放的就是hadoop02的公钥

同时也需要在hadoop02中的.ssh目录下:
ssh-copy-id hadoop02,
也要将root用户配置ssh免密登录:su切换到root,然后执行以上操作
同样对hadoop03和hadoop04重复上述的操作 。
五、群起集群
1、配置slaves
在hadoop02中
vim /opt/module/hadoop-2.9.2/etc/hadoop/slaves
在该文件中加入以下内容(将原本的localhost删除掉):主要是datanode,hadoop02、hadoop03、hadoop04上面都有
hadoop02
hadoop03
hadoop04
注意末尾不能有空格、回车。
然后使用集群分发脚本将其分发给hadoop03、hadoop04
在/opt/module/hadoop-2.9.2/etc/hadoop目录下输入:xsync.sh slaves
接下来将之前启动的那些节点都给停止掉:
sbin/hadoop-daemon.sh stop namenode
sbin/hadoop-daemon.sh stop datanode
然后在hadoop02中的/opt/module/hadoop-2.9.2目录下输入:sbin/start-dfs.sh

诸葛检查一下吧,首先是hadoop02:

hadoop03:

hadoop04:

说明是成功的,不容易啊。
六、启动yarn
这里注意,我们要在hadoop03中启动。即如果NameNode和ResourceManager不在同一台机器上,要在ResourceManager机器上启动yarn
输入:sbin/start-yarn.sh

可能会报权限不够问题。
那就改权限吧:需要注意看清前面是哪个服务器有权限问题
sudo chmod 777 /tmp/yarn-xiximayou-resourcemanager.pid
sudo chmod 777 /tmp/yarn-xiximayou-nodemanager.pid
之后再执行:

查看一下:
hadoop03:
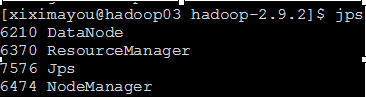
hadoop02:
hadoop04:

跟预期的对照一下:

七、进行测试
记得将hadoop03和hadoop04的防火墙也给关闭掉
1、上传一个文件到集群
在hadoop02中的hadoop-2.9.2目录下:
先上传一个小文件:
bin/hdfs dfs -put wcinput/wc.input /
再上传一个大文件:
bin/hdfs dfs -put /opt/software/Market.zip /
然后我们去查看
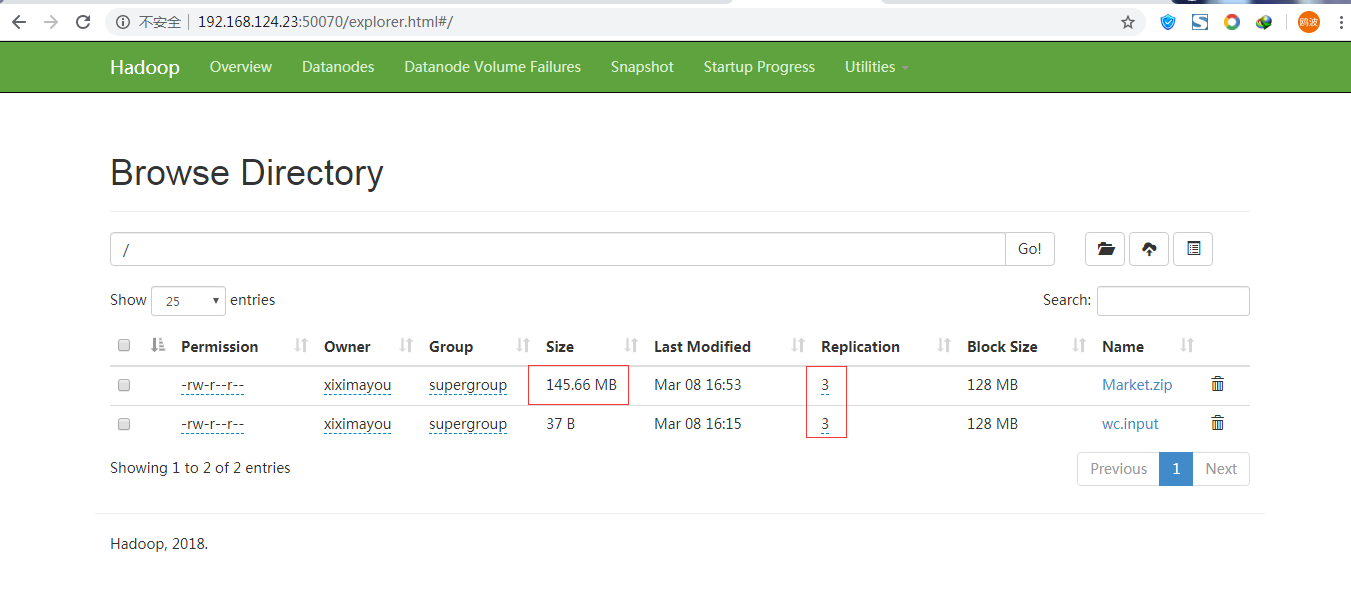
点开Market.zip
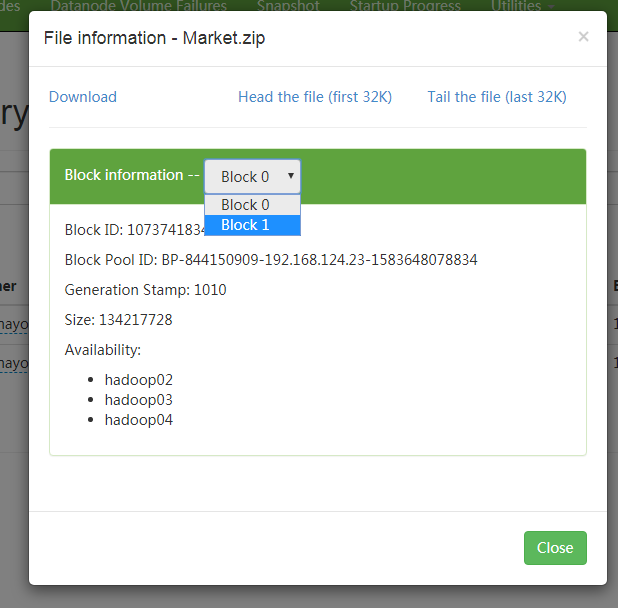
大文件(超过128M)分成了两块 ,同时在hadoop02、03、04上都有一份备份。
八、集群停止
sbin/stop-yarn.sh
sbin/stop-dfs.sh
hadoop之完全分布式集群配置(centos7)的更多相关文章
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 1.如何在虚拟机ubuntu上安装hadoop多节点分布式集群
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个had ...
- Hadoop(25)-高可用集群配置,HDFS-HA和YARN-HA
一. HA概述 1. 所谓HA(High Available),即高可用(7*24小时不中断服务). 2. 实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制:HDFS的HA ...
- Hadoop单机/伪分布式集群搭建(新手向)
此文已由作者朱笑笑授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 本文主要参照官网的安装步骤实现了Hadoop伪分布式集群的搭建,希望能够为初识Hadoop的小伙伴带来借鉴意 ...
- Linux下Apache与Tomcat的完全分布式集群配置(负载均衡)
最近公司要给客户提供一套集群方案,项目组采用了Apache和Tomcat的集群配置,用于实现负载均衡的实现. 由于以前没有接触过Apache,因此有些手生,另外在网上搜寻了很多有关这方面的集群文章,但 ...
- apache + tomcat 负载均衡分布式集群配置
Tomcat集群配置学习篇-----分布式应用 现目前基于javaWeb开发的应用系统已经比比皆是,尤其是电子商务网站,要想网站发展壮大,那么必然就得能够承受住庞大的网站访问量:大家知道如果服务器访问 ...
- hadoop-2.3.0-cdh5.1.0完全分布式集群配置HA配置
一.安装前准备: 操作系统:CentOS 6.5 64位操作系统 环境:jdk1.7.0_45以上,本次采用jdk-7u55-linux-x64.tar.gz master01 10.10.2.57 ...
- hadoop-2.3.0-cdh5.1.0完全分布式集群配置及HA配置(待)
一.安装前准备: 操作系统:CentOS 6.5 64位操作系统 环境:jdk1.7.0_45以上,本次采用jdk-7u55-linux-x64.tar.gz master01 10.10.2.57 ...
随机推荐
- 在VMware装了linux系统,如何在windows系统中用xshell连接
网上有好几种方法,不过我觉得这种比较简单 1.找到VMware菜单 打开 编辑>虚拟网络编辑器 如图: 点下面的更改设置 点确定就可以了,什么都不用改.然后回到linux系统中ifconfig ...
- 2. Unconstrained Optimization(2th)
2.1 Basic Results on the Existence of Optimizers 2.1. DefinitionLet $f:U->\mathbb{R}$ be a functi ...
- Listening-lecture|主旨题|术语解释|举例原则|Crash course 哔哩哔哩
Listening-lecture: Major topic: SP1---detail---detail---detail SP2---detail---detail---detail Crash ...
- Python的lambda学习
lambda可以简化简单循环,如下: def fc1(x): return x + 10 print "fc1(23) = ", fc1(23) y = lambda x: x+1 ...
- Caused by: java.io.FileNotFoundException: class path resource [../../resources/config/spring.xml] cannot be opened because it does not exist
在尝试使用Spring的Test的时候遇到了这个错误 原来的代码: @RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(loca ...
- 5-6 学生CPP成绩计算
给出下面的人员基类框架: class Person { protected: string name; int age; public: Person(); Person (string p_name ...
- Java集合源码剖析——ArrayList源码剖析
ArrayList简介 ArrayList是基于数组实现的,是一个动态数组,其容量能自动增长,类似于C语言中的动态申请内存,动态增长内存. ArrayList不是线程安全的,只能用在单线程环境下,多线 ...
- 吴裕雄--天生自然python学习笔记:pandas模块读取 Data Frame 数据
读取行数据 读取一个列数据的语法为: 例如,读取所有学生自然科目的成绩 : import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56 ...
- 柱状图dataLabels 文字格式 以及如何获取柱子的name(名称)属性
dataLabels: { formatter:funnctin(){ return this.percentage //只在堆叠图或饼图中有效,是该点相对总值的百分比. this.point //数 ...
- css样式表----------样式属性(背景与前景、边界和边框、列表与方块、格式与布局)
一.背景与前景 (1).背景 line-height: 1.5 !important;">90; /*背景色(以样式表为主,样式表优先.)*/ background-image:url ...