Scrapy 中的模拟登陆
目前,大部分网站都具有用户登陆功能,其中某些网站只有在用户登陆后才能获得有价值的信息,在爬取这类网站时,Scrapy 爬虫程序先模拟登陆,再爬取内容
1、登陆实质
其核心是想服务器发送含有登陆表单数据的 HTTP 请求(通常是POST)
2、使用 FormRequest
Scrapy 提供了一个FormRequest(Request 的子类),专门用于含有表单数据的请求,FormRequest 的构造方法有一个 formdata 参数,接收字典形式的表单数据。
有两方法可以构造 FormRequest 对象
(1)直接构造
<1> 先提取 3 个隐藏在<inout>中包含的信息
<2> 构造表单数据
<3> 填写账号和密码信息
(2)简单方式
即调用 FormRequest 的 form_response 方法,调用时传入一个 Response 对象作为第一个参数,该方法会解析 Response 对象所包含页面中的<from>元素,帮助用户创建FormRequest 对象,并将隐藏<input> 中的信息自动填入表单数据,使用这种方法,我们只需要通过 formdata 参数填写账号和密码即可:
>>> fd = {'email': 'junchuanzhang@webscraping.com', 'password': }
>>> request = FromRequest.from_response(response, fromdata = fd)
3、实现登陆的 Spide
import scrap
from http.http import Request , FormRequest
class LoginSpider(scrapy.Spider):
name = 'login'
allowed_domains = ['example.webscraping.com']
start_urls = ['http:?/example.websrcaping.com/user/login'] def parse(self, response):
# 解析登陆后下载的页面,此例中是用户个人信息
keys = response.css('table lable::text').re('*').extractor()
values = response.css(''table td.w2p_fw::text).extractor()
yield dict(zip(keys, values)) # --------------------登陆-------------------
#登陆页面的url
login_url = 'http://example.websracping.com/user/login' def start_requests(self):
yield Request(self.login_url, callback=self.login) def login(self, response):
# 登陆页面的解析函数,构造FormRequest 对象提交表单
fd = {'email': 'junchuanzhang@webscraping.com', 'password': 123456}
request = FromRequest.from_response(response, fromdata = fd, callback=self.parse_login)
def parse_login(self, response):
# 登陆成功后, 继续爬取 start_url 中的页面
if 'Welcome Liu' in response.text:
yield from super().start_requests()
解析上述代码如下:
(1)覆盖基类的 start_requests 方法,最先请求登录页面
(2)login 方法为登录页面的解析函数,在该方法中进行模拟登录,构造表单请求并提交。
(3)parse_login 方法为表单请求的响应处理函数,在该方法中通过在页面查找特殊字符串“Welcome Liu” 判断是否登录成功
如果成功,调用基类的 start_requests 方法,继续爬取 start_urls 中的页面。
这样设计 LoginSpider 就是想把模拟登录和爬取内容的代码分离开,使得逻辑上更加清晰。
4、识别验证码
目前,很多网站为了防止爬虫爬取,登录是需要用户输入验证码
下面我们学习如何在爬虫程序中识别验证码(在举例过程中不知名具体网站)
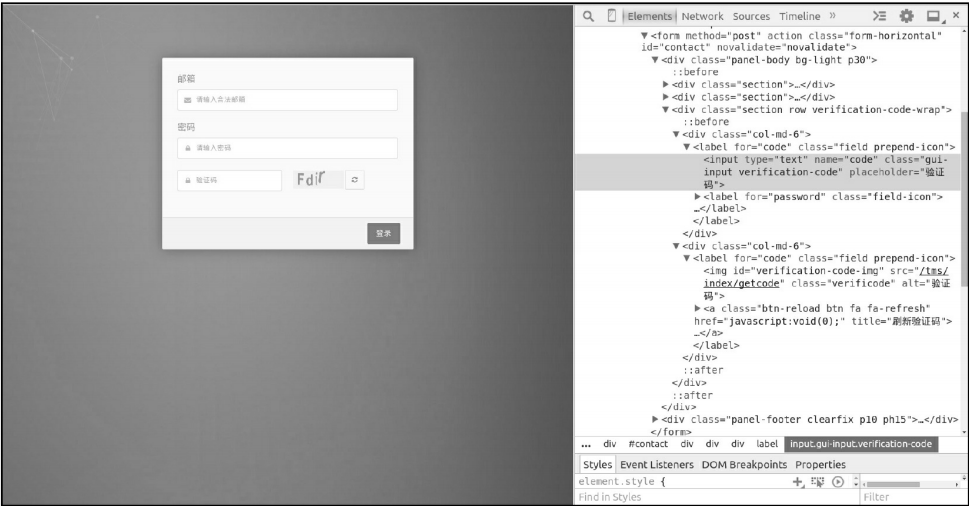
页面中的图片对应一个 <img> 元素,即一张图片,浏览器加载完登录页面后,会携带之前访问获取的Cookie信息,继续发送一个HTTP请求加载验证码图片,
和账号密码输入框一样,验证码输入框也对应一个<input>元素,因此用户输入的验证码会成为表单数据的一部分,表单提交后有网站服务器程序验证,
识别验证码有多种方式,下面解说常用的几种。
(1) OCR识别
(2)网络识别平台
(3)人工识别
5、Cookie 登录
目前网站的验证码越来越复杂,某些验证码已经复杂到人类那一识别的程度,有些时候提交表单的路子那一走通,此时,我们可以换一种登录爬取的思路,在使用浏览器登录网站后,包含用户身份的信息的Cookie会被浏览器保存在本地,如果 Scrapy 爬虫能直接使用浏览器中的 Cookie 发送 HTTP 请求,就可以绕过提交表单登录的步骤。
1、获取浏览器 Cookie
我们无需费心钻研,各种浏览器将 Cookie 以哪种形式存储在哪里,使用第三方 Python 库 browercookie 便可以获取 Chrome 和 Firefox浏览器中的 Cookie
使用 pip 安装 browercookie :
pip install browsercookie
browsercookie 的使用非常简单,实例代码如下:
>>> import browsercookie
>>>chrome_cookiejar = browsercookie.chrome()
>>>fire_cookiejar = browsercookie.firefox()
>>>type(chrome_cookiejar)
<class 'http.cookiejar.CookieJar'>
browsercookie的Chrome和Firefox方法分别返回 Chrome 和 Firefox 浏览器中的 Cookie,返回值是一个http.cookiejar.Cookiejar对象,对 cookiejar 对象进行迭代,可以访问其中的Cookie对象。
总结一下
1、如何使用 FormRequest 提交登陆表单的模拟登录
2、讲解识别验证码的 3 中方式
3、如何使用浏览器 Cookie 直接登录
Scrapy 中的模拟登陆的更多相关文章
- python之scrapy携带Cookies模拟登陆
知识点 """ scrapy两种模拟登陆: 1.直接携带cookie 2.找到发送post请求的url地址,带上信息,发送请求 应用场景: 1.cookie过期时间很长, ...
- Scrapy 模拟登陆知乎--抓取热点话题
工具准备 在开始之前,请确保 scrpay 正确安装,手头有一款简洁而强大的浏览器, 若是你有使用 postman 那就更好了. Python 1 scrapy genspid ...
- scrapy爬取某网站,模拟登陆过程中遇到的那些坑
本节内容 在访问网站的时候,我们经常遇到有些页面必须用户登录才能访问.这个时候我们之前写的傻傻的爬虫就被ban在门外了.所以本节,我们给爬虫配置cookie,使得爬虫能保持用户已登录的状态,达到获得那 ...
- Scrapy中使用cookie免于验证登录和模拟登录
Scrapy中使用cookie免于验证登录和模拟登录 引言 python爬虫我认为最困难的问题一个是ip代理,另外一个就是模拟登录了,更操蛋的就是模拟登录了之后还有验证码,真的是不让人省心,不过既然有 ...
- Scrapy基础(十四)————Scrapy实现知乎模拟登陆
模拟登陆大体思路见此博文,本篇文章只是将登陆在scrapy中实现而已 之前介绍过通过requests的session 会话模拟登陆:必须是session,涉及到验证码和xsrf的写入cookie验证的 ...
- scrapy的一些容易忽视的点(模拟登陆,传递item等)
scrapy爬虫注意事项 一.item数据只有最后一条 这种情况一般存在于对标签进行遍历时,将item对象放置在了for循环的外部.解决方式:将item放置在for循环里面. 二.item字段传递 ...
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别 第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://gith ...
- 爬虫入门之scrapy模拟登陆(十四)
注意:模拟登陆时,必须保证settings.py里的COOKIES_ENABLED(Cookies中间件) 处于开启状态 COOKIES_ENABLED = True或# COOKIES_ENABLE ...
- Scrapy模拟登陆豆瓣抓取数据
scrapy startproject douban 其中douban是我们的项目名称 2创建爬虫文件 进入到douban 然后创建爬虫文件 scrapy genspider dou douban. ...
随机推荐
- MySQLroot密码的恢复方法
MySQLroot密码的恢复方法 有可能你的系统没有 safe_MySQLd 程序(比如我现在用的 ubuntu操作系统, apt-get安装的MySQL) , 下面方法可以恢复 1.停止MySQLd ...
- sqlite3 install 和使用
windows: 在 Windows 上安装 SQLite 请访问 http://www.sqlite.org/download.html,从 Windows 区下载预编译的二进制文件. 您需要下载 ...
- redhat7.6 配置主从DNS
主DNS配置include指向的配置文件 /etc/named.rfc1912.zone 下面图片配置内容/etc/named.rfc1912.zones 从DNS配置 /etc/named.conf ...
- Redis注意点记录
场景:1主2从 1.不使用哨兵模式,则当主机宕机后,从机并不会自动切换到Master状态,仍旧是Slave,若主机重新恢复,则从机进行自动连接 2.使用哨兵模式后,主机宕机,从机会根据分配的权值在从机 ...
- Hibernate学习(二)
持久化对象的声明周期 1.Hibernate管理的持久化对象(PO persistence object )的生命周期有四种状态,分别是transient.persistent.detached和re ...
- eclipse 热部署
参考: http://blog.sina.com.cn/s/blog_be8b002e0101koql.html
- 如何使用charles对Android Https进行抓包
Charles.png charles是一款在Mac下常用的截取网络封包工具,对Android Http进行抓包,只要对手机设置代理即可,但对Android Https进行抓包还是破费一些功夫,网 ...
- openjudge 和为给定数(二分答案)
嗯... 题目链接:http://noi.openjudge.cn/ch0111/07/ 这道题是一道不太明显,但很好二分的二分答案的一道题... 首先排序(二分要满足单调性),然后枚举每一个数,在[ ...
- python2.7 一个莫名其妙的错误
先看看错误: Traceback (most recent call last): File "/home/darkchii/文档/PycharmProjects/ml/model.py&q ...
- Centos6.X安装桌面
1.前置环境yum -y groupinstall 'X Window System'2.桌面安装 yum -y groupinstall 'Desktop' 3.语言包yum -y groupins ...