python 爬虫之 urllib 实践
文章更新于:2020-03-19
注:本文参考官方文档进行 urllib 的讲解。
文章目录
一、urllib 模块介绍
urllib 主要有以下四大模块用于处理URL。
1、urllib.request.py模块
注1:Request Objects有以下属性:full_url、type、host、origin_req_host、selector、data、unverifiable、method
注2:Request Objects有以下方法:·get_method()、add_header(key,val)、add_unredirected_header(key,header)、has_header(header)、remove_header(header)、get_full_url()、set_proxy(host,type)、get_header(header_name,default=None)、header_items()
注3:以上属性或方法,可以在定义一个Request对象后调用。
(1)urlopen函数
urllib.request.urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT,
*, cafile=None, capath=None, cadefault=False, context=None)
注1:用于打开一个url,可以是一个网址字符串,也可以是一个Request对象。
注2:它返回的http.client.HTTPResponse或urllib.response.addinfourl对象具有以下方法:
注3:geturl()方法:通常用于查看返回资源的URL,确定是否被重定向。
注4:info()方法:返回页面的元信息,比如headers。
注5:getcode()方法:返回http的响应码。
(2) Request函数
urllib.request.Request(url, data=None, headers={}, origin_req_host=None,
unverifiable=False, method=None)¶
注1:url应该是一个有效的网址字符串。
注2:data是要发送给服务器的数据对象。
注3:如果是post方法,data应该是application/x-www-form-urlencoded格式。
注4:headers应该是一个字典。
(3) ProxyHandler(proxies=None)函数
注1:用于设置代理。
注2:端口号:port可选。
2、urllib.error.py模块
此模块下有URLError、HTTPError和ContentTooShortError(msg,content)。
3、urllib.parse.py模块
这个模块是用来处理URL的,可以分解拼接URL。
通常来说,一个URL可以分为6部分,比如说:scheme://netloc/path;parameters?query#fragment
每部分都是一个字符串,有些可以为空,但这6块都是不可再分的最小单位。

6个参数的解释如下:

4、urllib.robotparser.py模块
二、模块的使用
1、获取网页内容1
>>> import urllib.request
>>> with urllib.request.urlopen('http://www.python.org/') as f:
... print(f.read(300))
...
b'<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">\n\n\n<html
xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">\n\n<head>\n
<meta http-equiv="content-type" content="text/html; charset=utf-8" />\n
<title>Python Programming '
注1:如果是输出中文,这里的f.read(300)要改为f.read(300).decode('utf-8')才可以。
注2:因为urlopen返回的是字节对象,它无法自动转换编码,所以中文的话,手动来一下即可正常显示。
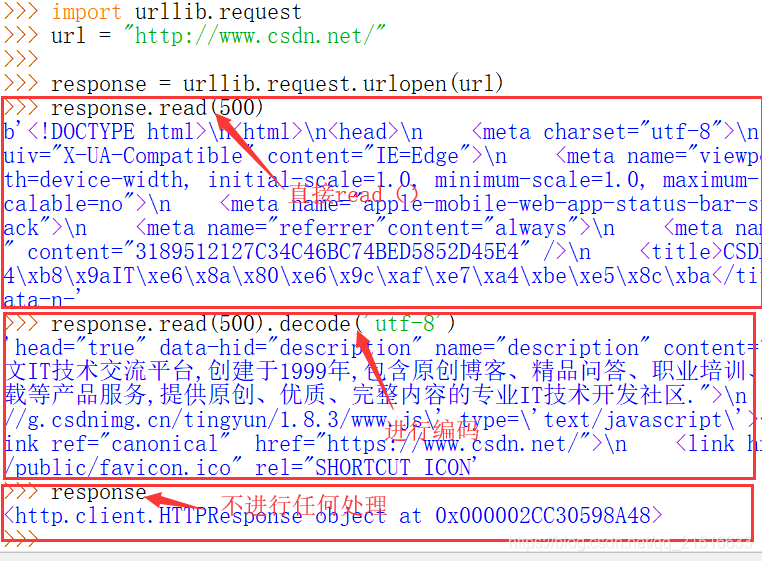
import urllib.request
url = "http://www.baidu.com/"
response = urllib.request.urlopen(url)
print(response.read().decode('utf-8')
注1:response 只能read一次(只print也算),再次read为空。
注2:如果只输出response,而不read(),那么输出的结果是这样的:
2、获取网页内容2
注:当然你还可以使用下面这种方法。
>>> import urllib.request
>>> f = urllib.request.urlopen('http://www.python.org/')
>>> print(f.read(100).decode('utf-8'))
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtm
3、使用基本的 HTTP 认证
import urllib.request
# Create an OpenerDirector with support for Basic HTTP Authentication...
auth_handler = urllib.request.HTTPBasicAuthHandler()
auth_handler.add_password(realm='PDQ Application',
uri='https://mahler:8092/site-updates.py',
user='klem',
passwd='kadidd!ehopper')
opener = urllib.request.build_opener(auth_handler)
# ...and install it globally so it can be used with urlopen.
urllib.request.install_opener(opener)
urllib.request.urlopen('http://www.example.com/login.html')
4、添加 headers
import urllib.request
req = urllib.request.Request('http://www.example.com/')
req.add_header('Referer', 'http://www.python.org/')
# Customize the default User-Agent header value:
req.add_header('User-Agent', 'urllib-example/0.1 (Contact: . . .)')
r = urllib.request.urlopen(req)
5、使用参数
>>> import urllib.request
>>> import urllib.parse
>>> data = urllib.parse.urlencode({'spam': 1, 'eggs': 2, 'bacon': 0})
>>> data = data.encode('ascii')
>>> with urllib.request.urlopen("http://requestb.in/xrbl82xr", data) as f:
... print(f.read().decode('utf-8'))
...
6、使用代理
>>> import urllib.request
>>> proxies = {'http': 'http://proxy.example.com:8080/'}
>>> opener = urllib.request.FancyURLopener(proxies)
>>> with opener.open("http://www.python.org") as f:
... f.read().decode('utf-8')
...
7、响应码
| 响应码 | 说明 |
|---|---|
| 100 | (‘Continue’, ‘Request received, please continue’) |
| 101 | (‘Switching Protocols’, ‘Switching to new protocol; obey Upgrade header’) |
| 200 | (‘OK’, ‘Request fulfilled, document follows’) |
| 201 | (‘Created’, ‘Document created, URL follows’) |
| 202 | (‘Accepted’, ‘Request accepted, processing continues off-line’) |
| 203 | (‘Non-Authoritative Information’, ‘Request fulfilled from cache’) |
| 204 | (‘No Content’, ‘Request fulfilled, nothing follows’) |
| 205 | (‘Reset Content’, ‘Clear input form for further input.’) |
| 206 | (‘Partial Content’, ‘Partial content follows.’) |
| 300 | (‘Multiple Choices’, ‘Object has several resources – see URI list’) |
| 301 | (‘Moved Permanently’, ‘Object moved permanently – see URI list’) |
| 302 | (‘Found’, ‘Object moved temporarily – see URI list’) |
| 303 | (‘See Other’, ‘Object moved – see Method and URL list’) |
| 304 | (‘Not Modified’, ‘Document has not changed since given time’) |
| 305 | (‘Use Proxy’, ‘You must use proxy specified in Location to access this resource.’) |
| 307 | (‘Temporary Redirect’, ‘Object moved temporarily – see URI list’) |
| 400 | (‘Bad Request’, ‘Bad request syntax or unsupported method’) |
| 401 | (‘Unauthorized’, ‘No permission – see authorization schemes’) |
| 402 | (‘Payment Required’, ‘No payment – see charging schemes’) |
| 403 | (‘Forbidden’, ‘Request forbidden – authorization will not help’) |
| 404 | (‘Not Found’, ‘Nothing matches the given URI’) |
| 405 | (‘Method Not Allowed’, ‘Specified method is invalid for this server.’) |
| 406 | (‘Not Acceptable’, ‘URI not available in preferred format.’) |
| 407 | (‘Proxy Authentication Required’, ‘You must authenticate with this proxy before proceeding.’) |
| 408 | (‘Request Timeout’, ‘Request timed out; try again later.’) |
| 409 | (‘Conflict’, ‘Request conflict.’) |
| 410 | (‘Gone’, ‘URI no longer exists and has been permanently removed.’) |
| 411 | (‘Length Required’, ‘Client must specify Content-Length.’) |
| 412 | (‘Precondition Failed’, ‘Precondition in headers is false.’) |
| 413 | (‘Request Entity Too Large’, ‘Entity is too large.’) |
| 414 | (‘Request-URI Too Long’, ‘URI is too long.’) |
| 415 | (‘Unsupported Media Type’, ‘Entity body in unsupported format.’) |
| 416 | (‘Requested Range Not Satisfiable’, ‘Cannot satisfy request range.’) |
| 417 | (‘Expectation Failed’, ‘Expect condition could not be satisfied.’) |
| 500 | (‘Internal Server Error’, ‘Server got itself in trouble’) |
| 501 | (‘Not Implemented’, ‘Server does not support this operation’) |
| 502 | (‘Bad Gateway’, ‘Invalid responses from another server/proxy.’) |
| 503 | (‘Service Unavailable’, ‘The server cannot process the request due to a high load’) |
| 504 | (‘Gateway Timeout’, ‘The gateway server did not receive a timely response’) |
| 505 | (‘HTTP Version Not Supported’, ‘Cannot fulfill request.’) |
8、处理异常
from urllib.request import Request, urlopen
from urllib.error import URLError, HTTPError
req = Request(someurl)
try:
response = urlopen(req)
except HTTPError as e:
print('The server couldn\'t fulfill the request.')
print('Error code: ', e.code)
except URLError as e:
print('We failed to reach a server.')
print('Reason: ', e.reason)
else:
# everything is fine
```
### 9、异常处理2
```python
from urllib.request import Request, urlopen
from urllib.error import URLError
req = Request(someurl)
try:
response = urlopen(req)
except URLError as e:
if hasattr(e, 'reason'):
print('We failed to reach a server.')
print('Reason: ', e.reason)
elif hasattr(e, 'code'):
print('The server couldn\'t fulfill the request.')
print('Error code: ', e.code)
else:
# everything is fine
三、总结
1、urllib.request.urlopen()
import urllib.request
url = "http://www.csdn.net/"
req = urllib.request.urlopen(url)
req.add_header('Referer','http://www.csdn.net')
req.add_header('User-Agent','chrome')
response = urllib.request.urlopen(req)
print(response.read(2000).decode('utf-8')
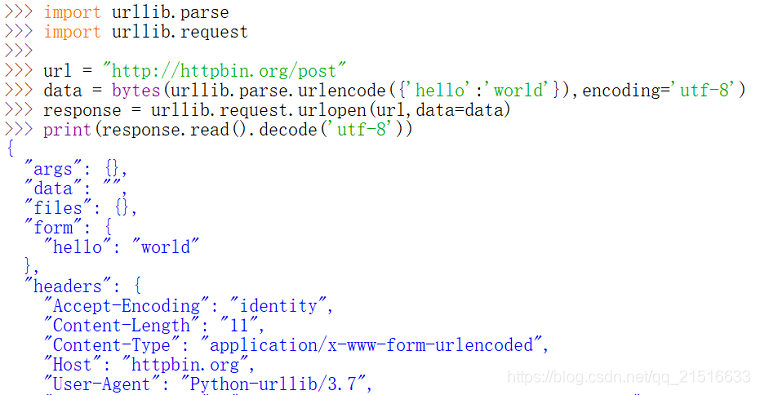
2、添加表单数据
import urllib.parse
import urllib.request
url = "http://httpbin.org/post"
data = bytes(urllib.parse.urlencode({'hello':'world'}),encoding='utf-8')
response = urllib.request.urlopen(url,data=data)
print(response.read().decode('utf-8'))
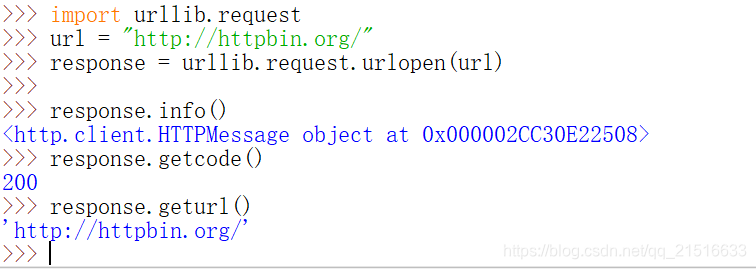
3、获取响应信息
import urllib.request
url = "http://httpbin.org/"
response = urllib.request.urlopen(url)
response.info()
response.getcode()
response.geturl()
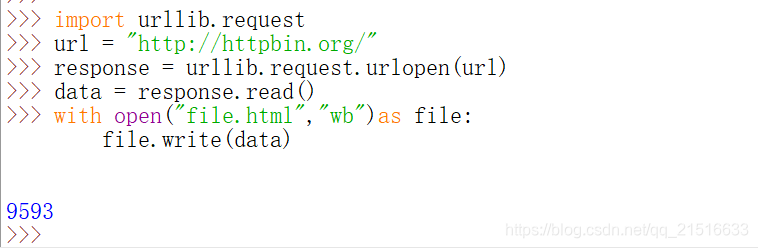
4、保存数据
如果是保存 HTML:
import urllib.request
url = "http://httpbin.org/"
response = urllib.request.urlopen(url)
data = response.read()
with open("file.html","wb")as file:
file.write(data)
·
如果是保存图片等数据:
import urllib.request
url = "http://csdn.net/favicon.ico"
response = urllib.request.urlopen(url)
data = response.read()
with open("file.png","wb")as file:
file.write(data)

另外一种方法,(注意路径要存在):
import urllib.request
url = "http://csdn.net/"
urllib.request.urlretrieve(url,filename=r"d:\test\index.html")
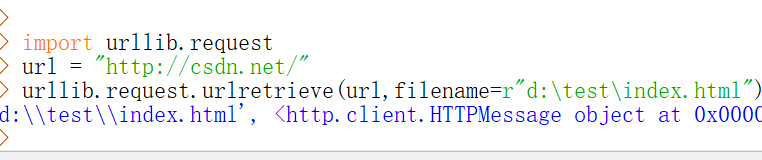
也可以用变量接收这个语句的返回值,类型是数组,可以输出数据。
5、处理异常
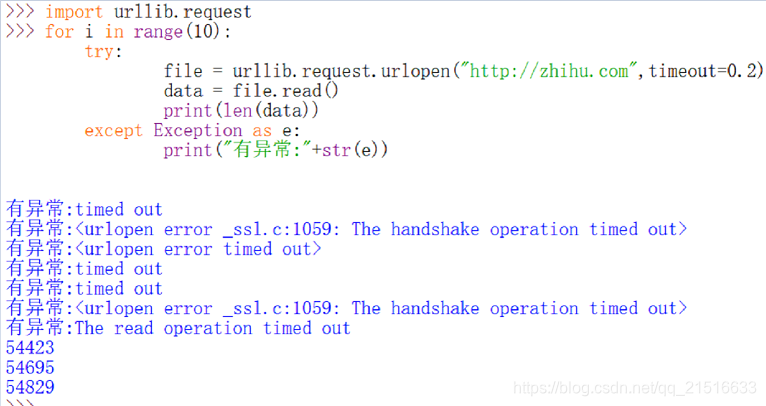
>>>import urllib.request
>>> for i in range(10):
try:
file = urllib.request.urlopen("http://zhihu.com",timeout=0.2)
data = file.read()
print(len(data))
except Exception as e:
print("有异常:"+str(e))
四、Enjoy!
python 爬虫之 urllib 实践的更多相关文章
- Python爬虫之urllib模块2
Python爬虫之urllib模块2 本文来自网友投稿 作者:PG-55,一个待毕业待就业的二流大学生. 看了一下上一节的反馈,有些同学认为这个没什么意义,也有的同学觉得太简单,关于Beautiful ...
- Python爬虫之urllib模块1
Python爬虫之urllib模块1 本文来自网友投稿.作者PG,一个待毕业待就业二流大学生.玄魂工作室未对该文章内容做任何改变. 因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬 ...
- python爬虫之urllib库(三)
python爬虫之urllib库(三) urllib库 访问网页都是通过HTTP协议进行的,而HTTP协议是一种无状态的协议,即记不住来者何人.举个栗子,天猫上买东西,需要先登录天猫账号进入主页,再去 ...
- python爬虫之urllib库(二)
python爬虫之urllib库(二) urllib库 超时设置 网页长时间无法响应的,系统会判断网页超时,无法打开网页.对于爬虫而言,我们作为网页的访问者,不能一直等着服务器给我们返回错误信息,耗费 ...
- python爬虫之urllib库(一)
python爬虫之urllib库(一) urllib库 urllib库是python提供的一种用于操作URL的模块,python2中是urllib和urllib2两个库文件,python3中整合在了u ...
- Python爬虫之urllib.parse详解
Python爬虫之urllib.parse 转载地址 Python 中的 urllib.parse 模块提供了很多解析和组建 URL 的函数. 解析url 解析url( urlparse() ) ur ...
- Python爬虫之Urllib库的基本使用
# get请求 import urllib.request response = urllib.request.urlopen("http://www.baidu.com") pr ...
- python爬虫之urllib库
请求库 urllib urllib主要分为几个部分 urllib.request 发送请求urllib.error 处理请求过程中出现的异常urllib.parse 处理urlurllib.robot ...
- Python爬虫系列-Urllib库详解
Urllib库详解 Python内置的Http请求库: * urllib.request 请求模块 * urllib.error 异常处理模块 * urllib.parse url解析模块 * url ...
随机推荐
- 使用.Net Core编写命令行工具(CLI)
命令行工具(CLI) 命令行工具(CLI)是在图形用户界面得到普及之前使用最为广泛的用户界面,它通常不支持鼠标,用户通过键盘输入指令,计算机接收到指令后,予以执行. 通常认为,命令行工具(CLI)没有 ...
- MySQL记录操作(多表查询)
准备 建表与数据准备 #建表 create table department( id int, name varchar(20) ); create table employee( id int pr ...
- git常规使用命令笔记
使用git也有不短的时间,这篇文章主要默写自己在提交代码经常使用的一些密令,仅供参考并不是教程. git log 查看日志 git branch 查看分值 git branch Name 新建一个Na ...
- 【分布式锁】01-使用Redisson实现可重入分布式锁原理
前言 主流的分布式锁一般有三种实现方式: 数据库乐观锁 基于Redis的分布式锁 基于ZooKeeper的分布式锁 之前我在博客上写过关于mysql和redis实现分布式锁的具体方案:https:// ...
- mui switch 点击事件不冒泡
工作上遇到一个问题 手机移动端app,采用mui框架,要求左边是手机号码,右边是switch开关,并且点击标题的时候,可以展开下面人员的基本信息. 采用了折叠面板. 先上图如下: 开始时出现的问题是: ...
- 关于Addressable的疑问
1)关于Addressable的疑问2)Addressable如何进行热更新3)如何设置SceneView相机的Shader变量4)Activity默认为SingleTask的原因5)关于Resour ...
- Python习题集(四)
每天一习题,提升Python不是问题!!有更简洁的写法请评论告知我! https://www.cnblogs.com/poloyy/category/1676599.html 题目 如果一个 3 位数 ...
- JSTL、请求转发和URL重定向
JSTL 为什么要使用JSTL? 因为在JSP中写JAVA代码很麻烦,而JSTL可以简化在JSp中写JAva代码的流程 如何使用JSTL? 准备工作: ①将JSTL依赖的jar包导入工程的WEB-IN ...
- java-接口(新手)
//创建的一个包名. package jiekou; //接口方法. //创建一个接口并且起名字. public interface JK { //抽象的返回值.(具体功能未定义,需要自己定义) ab ...
- 滑动窗口-Moving Stones Until Consecutive II
2020-02-20 16:34:16 问题描述: 问题求解: public int[] numMovesStonesII(int[] stones) { int n = stones.length; ...