数据挖掘入门系列教程(四点五)之Apriori算法
数据挖掘入门系列教程(四点五)之Apriori算法
Apriori(先验)算法关联规则学习的经典算法之一,用来寻找出数据集中频繁出现的数据集合。如果看过以前的博客,是不是想到了这个跟数据挖掘入门系列教程(一)之亲和性分析这篇博客很相似?Yes,的确很相似,只不过在这篇博客中,我们会更加深入的分析如何寻找可靠有效的亲和性。并在下一篇博客中使用Apriori算法去分析电影中的亲和性。这篇主要是介绍Apriori算法的流程。
频繁(项集)数据的评判标准
这个在数据挖掘入门系列教程(一)之亲和性分析这篇博客曾经提过,但在这里再重新详细的说一下。
何如判断一个数据是否是频繁?按照我们的想法,肯定是数据在数据集中出现次数的越多,则代表着这个数据出现的越频繁。
值得注意的是:在这里的数据可以是一个数据,也可以是多个数据 (项集)。
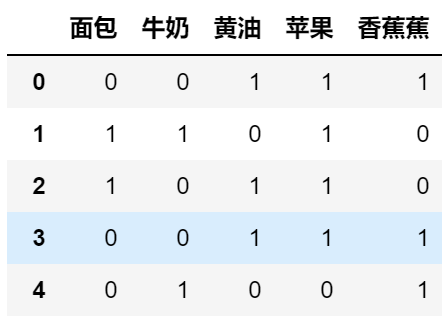
以下面这张图为例子,这张图每一列代表商品是否被购买(1代表被购买,0代表否),每一行代表一次交易记录:
常用的评估标准由支持度、置信度、和提升度三个:
支持度(support):
支持度就是数据在数据集中出现的次数(也可以是次数占总数据集的比重),或者说其在数据集中出现的概率:
下面的公式以所占比例来说明:
\[
\begin{split}
& 如果是一个数据X,则其支持度为:\\
& support(X) = P(X) = \frac{num(X)}{num(ALL)} \\
& 如果数据是一个数据项集(X,Y),则支持度为:\\
& support(X,Y) = P(X,Y) = \frac{num(XY)}{num(ALL)}\\
& 如果数据是一个数据项集(X,Y,Z),则支持度为:\\
& support(X,Y,Z) = P(X,Y,Z) = \frac{num(XYZ)}{num(ALL)}\\
& (X,Y,Z代表的是X,Y,Z同时出现的次数)
\end{split}
\]
以上面的交易为例:
我们来求 (黄油,苹果) 的支持度:
(黄油,苹果) 在第0,2,3中通过出现了,一共是5条数据,因此\(support(黄油,苹果) = \frac{3}{5} = 0.6\)
一般来说,支持度高的不一定数据频繁,但是数据频繁的一定支持度高
置信度(confidence):
置信度代表的规则应验的准确性,也就是一个数据出现后,另外一个数据出现的概率,也就是条件概率。(以购买为例,就是已经购买Y的条件下,购买X的概率)公式如下:
\[
\begin{split}
& 设分析的数据是X,Y,则X对Y的置信度为:\\
& confidence(X \Leftarrow Y) = P(X|Y) = \frac{P(XY)}{P(Y)} \\
& 设分析的数据是X,Y,Z,则X对Y和Z的置信度为:\\
& confidence(X \Leftarrow YZ) = P(X|YZ) = \frac{P(XYZ)}{P(YZ)} \\
\end{split}
\]
还是以 (黄油,苹果) 为例子,计算黄油对苹果的置信度:\(confidence(黄油\Leftarrow苹果) = \frac{3}{4} = 0.75\)。
但是置信度有一个缺点,那就是它可能会扭曲关联的重要性。因为它只反应了Y的受欢迎的程度。如果X的受欢迎程度也很高的话,那么confidence也会很大。下面是数据挖掘蒋少华老师的一段为什么我们需要使用提升度的话:
提升度(Lift):
提升度表示在含有Y的条件下,同时含有X的概率,同时考虑到X的概率,公式如下:
\[
\begin{equation}
\begin{aligned}
Lift(X \Leftarrow Y) &= \frac{support(X,Y)}{support(X) \times support(Y)} \
\
&= \frac{P(X,Y)}{P(X) \times P(Y)}\\
& = \frac{P(X|Y)}{P(X)}\\
& = \frac{confidenc(X\Leftarrow Y)}{P(X)}
\end{aligned}
\end{equation}
\]
在提升度中,如果\(Lift(X \Leftarrow Y) = 1\)则表示X,Y之间相互独立,没有关联(因为\(P(X|Y) = P(X)\)),如果\(Lift(X \Leftarrow Y) > 1\)则表示\(X \Leftarrow Y\)则表示\(X \Leftarrow Y\)是有效的强关联(在购买Y的情况下很可能购买X);如果\(Lift(X \Leftarrow Y) < 1\)则表示\(X \Leftarrow Y\)则表示\(X \Leftarrow Y\)是无效的强关联。
一般来说,我们如何判断一个数据集中数据的频繁程度时使用提升度来做的。
Apriori 算法流程
说完评判标准,接下来我们说一下算法的流程(来自参考1)。
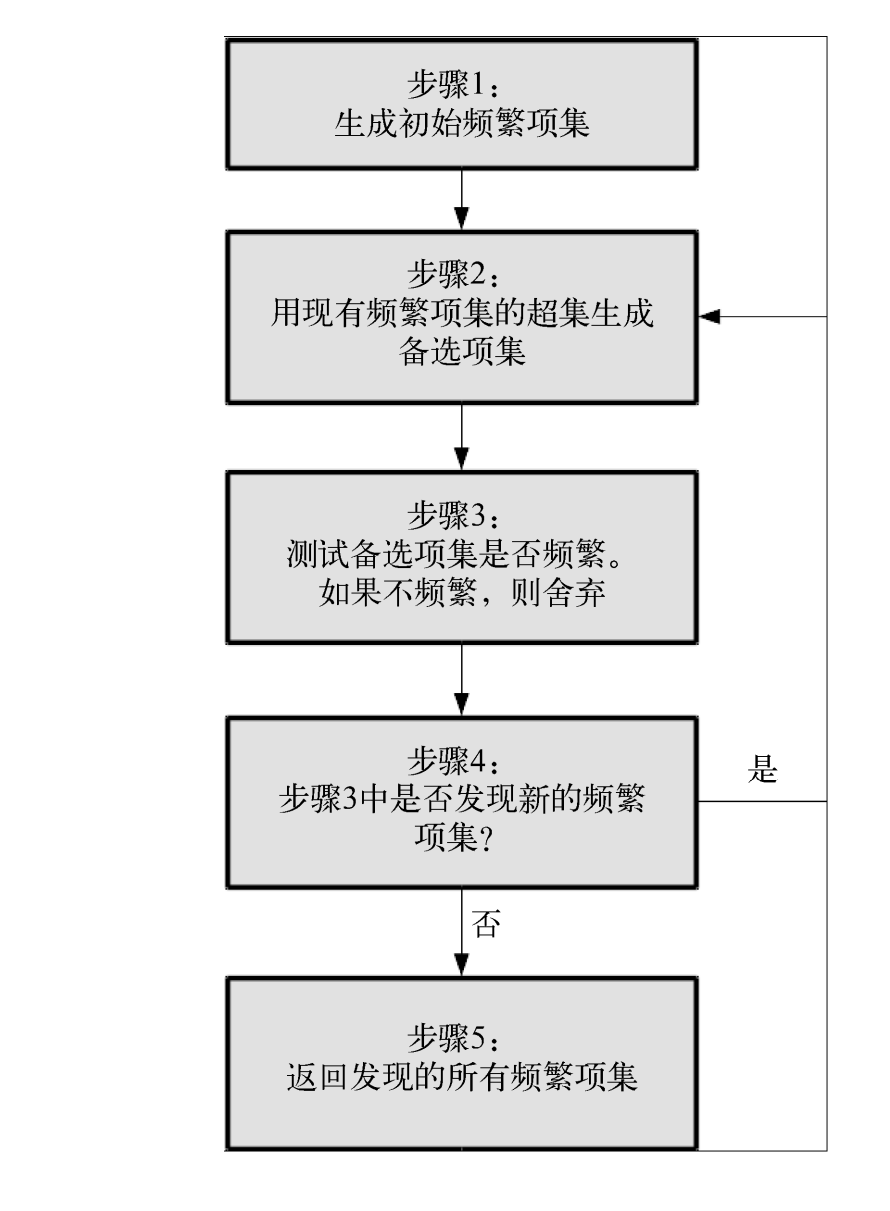
Apriori算法的目标是找到最大的K项频繁集。这里有两层意思,首先,我们要找到符合支持度标准(置信度or提升度)的频繁集。但是这样的频繁集可能有很多。第二层意思就是我们要找到最大个数的频繁集。比如我们找到符合支持度的频繁集AB和ABE,那么我们会抛弃AB,只保留ABE,因为AB是2项频繁集,而ABE是3项频繁集。
算法的流程图如下(图来自《Python数据挖掘入门与实践》):
下面是一个具体的例子来介绍(图源不知道来自哪里,很多博客都在用),这个例子是以support作为评判标准,在图中\(C_n\)代表的是备选项集,L代表的是被剪掉后的选项集,\(Min\ support = 50\%\)代表的是最小符合标准的支持度(大于它则表示频繁)。
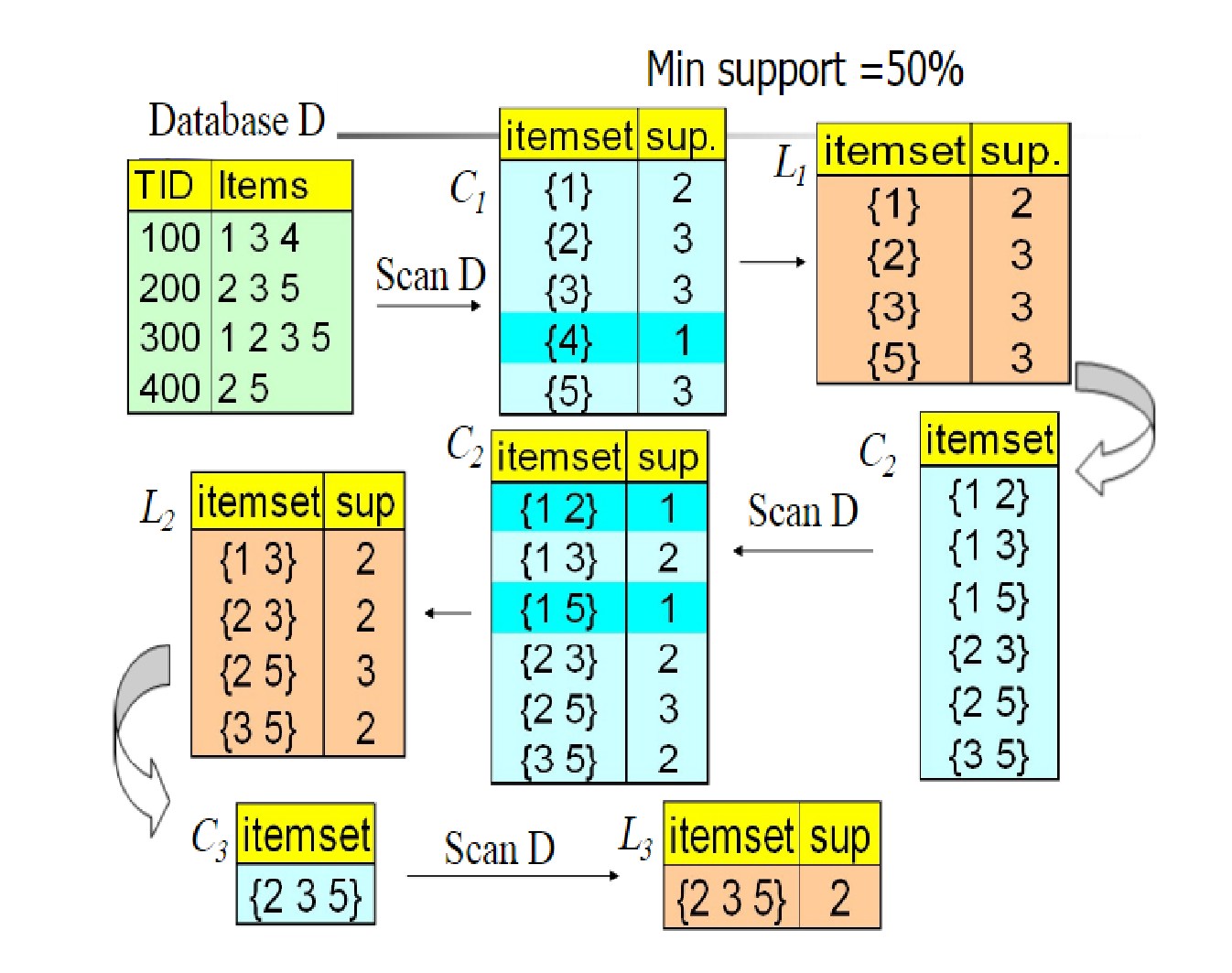
这个例子的图像还是满生动的,很容易看的懂。下面就简单的解释一下:
首先我们有数据集D,然后生成数据项\(K =1\)的备选项集\(C_1\),然后去除\(support_n < Min\ support\)的数据项,得到\(L_1\),然后又生成数据项\(K =2\)的备选项集\(C_2\),然后又去除\(support_n < Min\ support\)的数据项。进行递归,直到无法发现新的频繁项。
结尾
总的来说,Apriori算法不是很难,算法的流程也很简单,而它的核心在于如何构建一个有效的评判标准,support?confidence?Lift?or others?但是它也有一些缺点:每次递归都需要产生大量的备选项集,如果数据集很大的话,怎么办?重复的扫描数据集……
在下一篇博客中,我将介绍如何使用Apriori算法对电影的数据集进行分析,然后找出之间的相关关系。
参考
- Apriori算法原理总结
- Association Rules and the Apriori Algorithm: A Tutorial
- 《Python数据挖掘入门与实践》
- 数据挖掘蒋少华老师
数据挖掘入门系列教程(四点五)之Apriori算法的更多相关文章
- 数据挖掘入门系列教程(五)之Apriori算法Python实现
数据挖掘入门系列教程(五)之Apriori算法Python实现 加载数据集 获得训练集 频繁项的生成 生成规则 获得support 获得confidence 获得Lift 进行验证 总结 参考 数据挖 ...
- 数据挖掘入门系列教程(十点五)之DNN介绍及公式推导
深度神经网络(DNN,Deep Neural Networks)简介 首先让我们先回想起在之前博客(数据挖掘入门系列教程(七点五)之神经网络介绍)中介绍的神经网络:为了解决M-P模型中无法处理XOR等 ...
- 数据挖掘入门系列教程(八)之使用神经网络(基于pybrain)识别数字手写集MNIST
目录 数据挖掘入门系列教程(八)之使用神经网络(基于pybrain)识别数字手写集MNIST 下载数据集 加载数据集 构建神经网络 反向传播(BP)算法 进行预测 F1验证 总结 参考 数据挖掘入门系 ...
- 数据挖掘入门系列教程(九)之基于sklearn的SVM使用
目录 介绍 基于SVM对MINIST数据集进行分类 使用SVM SVM分析垃圾邮件 加载数据集 分词 构建词云 构建数据集 进行训练 交叉验证 炼丹术 总结 参考 介绍 在上一篇博客:数据挖掘入门系列 ...
- 数据挖掘入门系列教程(十一)之keras入门使用以及构建DNN网络识别MNIST
简介 在上一篇博客:数据挖掘入门系列教程(十点五)之DNN介绍及公式推导中,详细的介绍了DNN,并对其进行了公式推导.本来这篇博客是准备直接介绍CNN的,但是想了一下,觉得还是使用keras构建一个D ...
- 数据挖掘入门系列教程(十二)之使用keras构建CNN网络识别CIFAR10
简介 在上一篇博客:数据挖掘入门系列教程(十一点五)之CNN网络介绍中,介绍了CNN的工作原理和工作流程,在这一篇博客,将具体的使用代码来说明如何使用keras构建一个CNN网络来对CIFAR-10数 ...
- 数据挖掘入门系列教程(二)之分类问题OneR算法
数据挖掘入门系列教程(二)之分类问题OneR算法 数据挖掘入门系列博客:https://www.cnblogs.com/xiaohuiduan/category/1661541.html 项目地址:G ...
- 数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例)
数据挖掘入门系列教程(三)之scikit-learn框架基本使用(以K近邻算法为例) 简介 scikit-learn 估计器 加载数据集 进行fit训练 设置参数 预处理 流水线 结尾 数据挖掘入门系 ...
- 数据挖掘入门系列教程(四)之基于scikit-lean实现决策树
目录 数据挖掘入门系列教程(四)之基于scikit-lean决策树处理Iris 加载数据集 数据特征 训练 随机森林 调参工程师 结尾 数据挖掘入门系列教程(四)之基于scikit-lean决策树处理 ...
随机推荐
- css3 transform 变形属性详解
本文主要介绍了css3 属性transform的相关内容,针对CSS3变形.CSS3转换.CSS3旋转.CSS3缩放.扭曲和矩阵做了详细的讲解.希望对你有所帮助. 这个很简单,就跟border-rad ...
- VisionPro连接Dalsa线扫相机
1 环境配置 硬件:编码器(提供编码信号的PLC) 线扫相机 镜头 相机线缆 图像采集卡(Dalsa_Xcelera-CL_PX4 Dual) 软件:VisionPro 8.2 VisionPro软件 ...
- vue-cli 项目结构介绍
感谢:https://www.jianshu.com/p/7006a663fb9f 总体框架 一个vue-cli的项目结构如下,其中src文件夹是需要掌握的,所以本文也重点讲解其中的文件,至于其他相关 ...
- JDK1.8新特性Lambda表达式
/** * Lambda * @date 2019/8/2 10:03 */ public class Lamda { public static void main(String[] args){ ...
- Dungeon Master (三维BFS)
题目: You are trapped in a 3D dungeon and need to find the quickest way out! The dungeon is composed o ...
- React.js/HTML5和iOS双向通信
最近,我使用WKWebView和React.js进行双向通信,自己写了React.js嵌入到Native中. Native操作Web,通过两种方式传值 第一种,通过JS传值给Native 通过这种方式 ...
- windowserver 2012安装openssh
下载https://github.com/PowerShell/Win32-OpenSSH/releases解压放到C:\Program Files\OpenSSH-Win64 进入到C:\Progr ...
- iPhone 8价格狂跌:是国产手机的胜利,还是苹果的黄昏
8价格狂跌:是国产手机的胜利,还是苹果的黄昏" title="iPhone 8价格狂跌:是国产手机的胜利,还是苹果的黄昏"> 其实呢,这年头发布新款智能 ...
- 树的三种DFS策略(前序、中序、后序)遍历
之前刷leetcode的时候,知道求排列组合都需要深度优先搜索(DFS), 那么前序.中序.后序遍历是什么鬼,一直傻傻的分不清楚.直到后来才知道,原来它们只是DFS的三种不同策略. N = Node( ...
- 【C++基础】008常量和变量
简介:常量和变量. 常量和变量 1. 常量 具体把数据写出来 2,3,4: 1.2,1.3: "Hello World!","C++": cout <&l ...