Redis学习笔记(九)——集群
一、概述
Redis Cluster与Redis3.0.0同时发布,以此结束了Redis无官方集群方案的时代。
Redis Cluster是去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
那么Redis是如何合理分配这些节点和数据呢?
Redis集群并没有使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽(hash slot)的方式来分配的。Redis Cluster默认分配了16384个slot,当我们set一个key时,会用CRC16算法来取模得到所属的slot,然后将这个key分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。
注意的是:必须要3个以上的主节点,否则在创建集群时会失败。
所以,我们假设现在有3个节点已经组成了集群,分别是A、B、C三个节点,它们可以是一台机器上的三个端口,也可以是三台不同的服务器。那么采用哈希槽(hash slot)的方式来分配16384个slot的话,它们三个节点分别承担的slot区间是:
节点A覆盖 0 - 5460;
节点B覆盖 5461 - 10922;
节点C覆盖 10923 - 16383;
Redis Cluster主从模式:
Redis Cluster为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据备份,当这个主节点挂掉后,就会有这个从节点选取一个来当主节点,从而保证集群不会挂掉。
二、操作
搭建集群需要的环境:
目前我用的是CentOS 7的系统,所以安装Ruby的时候只有2.0.0的版本,会执行不成功;每个Linux系统版本都有差别,如果执行以下操作不成功,请自行百度解决。
安装RVM:
在该系统,如果我之间安装Ruby只有2.0.0版本,在执行 gem install redis 时,会提示:
ERROR: Error installing redis:
redis requires Ruby version >= 2.2.2.
所以得安装RVM再安装2.2.2或以上的Ruby。
安装命令:
gpg2 --keyserver hkp://keys.gnupg.net --recv-keys D39DC0E3

curl -L get.rvm.io | bash -s stable
source /usr/local/rvm/scripts/rvm
查看RVM库已知的ruby版本
rvm list known
安装一个ruby版本(大于2.2.2),这里安装2.4.4
rvm install 2.2.4
使用ruby版本
rvm use 2.4.4 --default

卸载ruby2.0.0版本
rvm remove 2.0.0

安装redis
gem install redis

单机多节点集群实验
1、Redis安装包里面有个集群工具,要复制到/usr/local/bin 里去
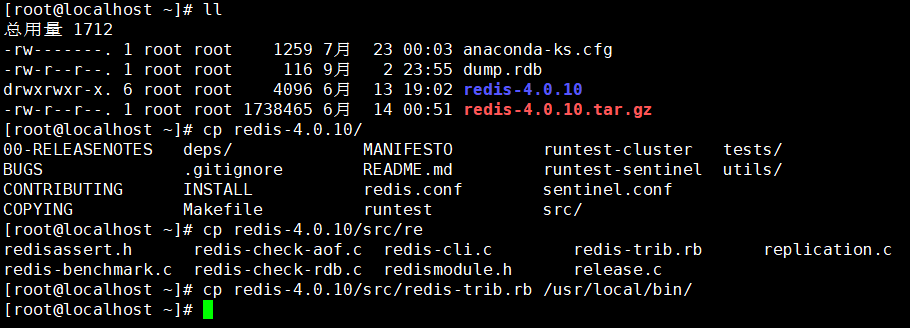
2、修改配置,创建节点
我们现在要搞六个节点,三主三从。
端口规定分别为:7001、7002、7003、7004、7005、7006。
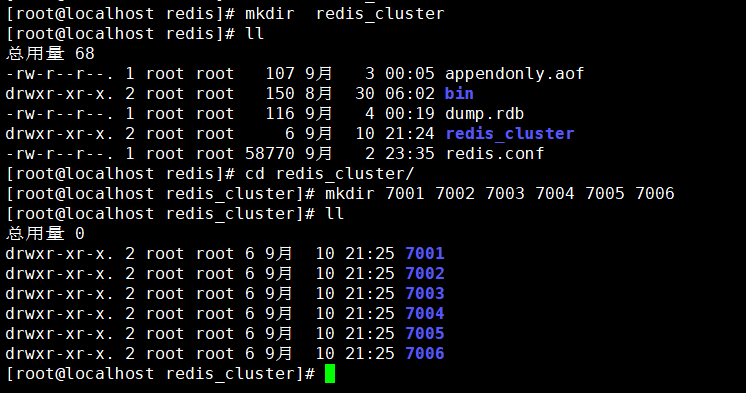
我们先在 /usr/local/redis/ 目录下新建一个redis_cluster目录,然后再该目录下再创建6个目录,分别是7001、7002、7003、7004、7005、7006,用来存储redis配置文件:
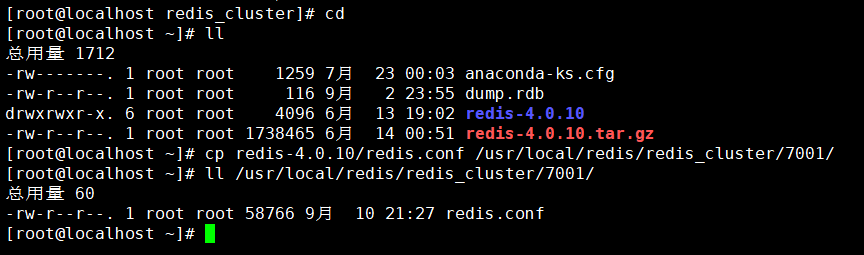
我们先复制一份配置文件到7001目录下
我们回到7001目录,修改配置文件,修改以下几个参数:
port 7001 // 六个节点配置文件分别是7001 - 7006
daemonize yest // redis后台运行
pidfile /var/run/redis_7001.pid // pidfile文件对应7001 - 7006
cluster-enabled yes // 开启集群
cluster-config-file nodes_7001.conf // 保存节点配置,自动创建,自动更新对应7001 - 7006
cluster-node-timeout 5000 // 集群超时时间,节点超过这个时间没反应就断定宕机
appendonly yes // 存储方式,aof,将写操作记录保存到日志中
修改port

修改daemonize

修改pidfile

修改 cluster-enabled

修改cluster-config-file
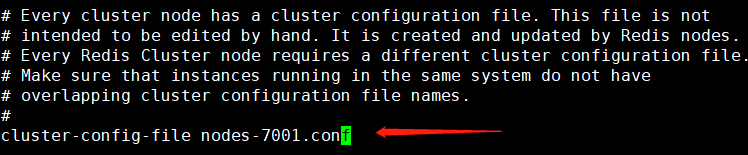
修改cluster-node-timeout

修改appendonly

7001下的配置文件修改完保存后,我们将该配置文件分别复制到7002 - 7006中,然后对应的再修改配置即可,编辑后面5个配置文件,把 port ,pidfile,cluster-config-file 分别修改下即可(此操作简略);

3、启动六个节点的redis

查看redis进程:

六个进程都启动成功了。
4、创建集群
Redis官方提供了redis-trib.rb 工具,第一步里已经拷贝到bin目录下;
但是在使用之前,需要安装ruby,以及Redis和ruby连接(前面也有教程讲了安装了)
创建集群:
redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006

创建成功
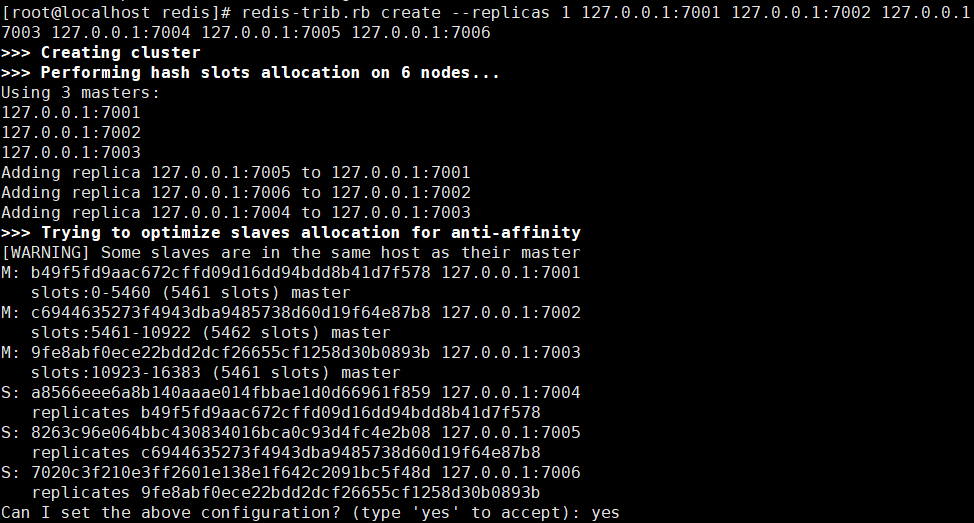
从运行结果看,主节点就是7001、7002、7003、从节点分别是7004、7005、7006
7001分配到的哈希槽是 0 - 5460;
7002分配到的哈希槽是 5461 - 10922;
7003分配到的哈希槽是 10923 - 16383;
最后问我们是否接受上面的设置,输入yes就表示接受,我们输入yes:

显示配置哈希槽,以及集群创建成功,可以用了;
也有可能会出现以下错误:

出现该错误的解决方式:删除生产的配置文件nodes.conf,如果不行则说明现在创建的节点包括了旧集群的节点信息,需要删除redis的持久化文件后再重启redis,比如:appendonly.aof、dump.rdb
4、集群数据测试
我们先连接任意一个节点,然后添加一个key:
redis-cli是默认redis的客户端工具,启动时加上 '-c' 参数, '-p' 指定端口,就可以连接到集群。
连接任意一个节点端口:

添加一个key

Redis Cluster值分配规则,它会使用CRC16('value')%16384算法来计算,将这个key放到哪个节点,这里分配到5798slot就分配到了7002(5461 - 10922)这个节点上。
我们从其他集群节点,都可以获取到数据:

Redis学习笔记(九)——集群的更多相关文章
- redis 学习笔记-cluster集群搭建
一.下载最新版redis 编译 目前最新版是3.0.7,下载地址:http://www.redis.io/download 编译很简单,一个make命令即可,不清楚的同学,可参考我之前的笔记: red ...
- redis 学习笔记2(集群之哨兵模式的使用)
redis3.0之前已经有了哨兵模式,3.0之后有了cluster(分片集群),官方不推荐使用!!主要原因是分片后单节点故障后需要实现手动分槽... 集群较为成熟的解决方案codis,公司使用的是哨兵 ...
- Quartz学习笔记:集群部署&高可用
Quartz学习笔记:集群部署&高可用 集群部署 一个Quartz集群中的每个节点是一个独立的Quartz应用,它又管理着其他的节点.这就意味着你必须对每个节点分别启动或停止.Quartz集群 ...
- Dubbo -- 系统学习 笔记 -- 示例 -- 集群容错
Dubbo -- 系统学习 笔记 -- 目录 示例 想完整的运行起来,请参见:快速启动,这里只列出各种场景的配置方式 集群容错 在集群调用失败时,Dubbo提供了多种容错方案,缺省为failover重 ...
- NodeJS学习笔记 (17)集群-cluster(ok)
cluster模块概览 node实例是单线程作业的.在服务端编程中,通常会创建多个node实例来处理客户端的请求,以此提升系统的吞吐率.对这样多个node实例,我们称之为cluster(集群). 借助 ...
- redis相关笔记(二.集群配置及使用)
redis笔记一 redis笔记二 redis笔记三 1.配置:在原redis-sentinel文件夹中添加{8337,8338,8339,8340}文件夹,且复制原8333中的配置 在上述8333配 ...
- MongoDB学习笔记~Mongo集群和副本集
回到目录 一些概念 对于Mongo在数据容灾上,推荐的模式是使用副本集模式,它有一个对外的主服务器Primary,还有N个副本服务器Secondary(N>=1,当N=1时,需要有一台仲裁服务器 ...
- ElasticSearch学习笔记-02集群相关操作_cat参数
_cat参数允许你查看集群的一些相关信息,如集群是否健康,有哪些节点,以及索引的情况等的. 检测集群是否健康 curl localhost:9200/_cat/health?v 说明: curl 是一 ...
- Spark学习笔记——在集群上运行Spark
Spark运行的时候,采用的是主从结构,有一个节点负责中央协调, 调度各个分布式工作节点.这个中央协调节点被称为驱动器( Driver) 节点.与之对应的工作节点被称为执行器( executor) 节 ...
- Redis学习笔记九:独立功能之慢查询日志
Redis 的慢查询日志用于记录执行时间超过给定时长的命令请求,用户可以通过这个功能产生的日志来监视和优化查询速度. 服务器配置有两个相关选项: slowlog-log-slower-than 选项指 ...
随机推荐
- Redis学习(二)redis的特点
一.Redis的特性 Redis是基于内存,常用作于缓存的技术 Redis实现的是分布式缓存,如果有多台实例(机器)的话,每个实例都共享一份缓存,缓存具有一致性. 常见的性能问题一般都是由于数据库(磁 ...
- Win10安装Ubuntu子系统
相信我,这是最后一次折腾系统了qaq,以后一定开始认真用Linux编程 跟的一个博客安装,传送门:Win10安装Ubuntu子系统及图形化界面详细教程 文章是2019的,加上我装的是Ubuntu 20 ...
- 《我想进大厂》之MQ夺命连环11问
继之前的mysql夺命连环之后,我发现我这个标题被好多套用的,什么夺命zookeeper,夺命多线程一大堆,这一次,开始面试题系列MQ专题,消息队列作为日常常见的使用中间件,面试也是必问的点之一,一起 ...
- Python-如何在一个for循环中迭代多个可迭代对象?
案例: 某班学生期末考试成绩,语文.数学.英语分别存储在3个列表中,同时迭代三个列表.,计算每个学生的总分(并行) 某年级有4个班,某次英语成绩分别记录在4个列表中,依次迭代每个列表,统计全年级高于9 ...
- Decision trees决策树
信息熵(entropy) 信息熵模型(香农Shannon's Entropy Model) 在一个随机事件中,某个事件发生的不确定度越大,熵也就越大,那我们要搞清楚所需要的信息量越 信息增益(IG,I ...
- 剑指offer-链表&数组
1.圆圈中最后剩下的数 每年六一儿童节,牛客都会准备一些小礼物去看望孤儿院的小朋友,今年亦是如此.HF作为牛客的资深元老,自然也准备了一些小游戏.其中,有个游戏是这样的:首先,让小朋友们围成一个大圈. ...
- This is Riv3r1and.
总是要弄个博客来搞的嘛.
- Android Studio3.5在编译项目出现连接不上gradle该怎么办?
------------恢复内容开始------------ 报错原因: Could not get resource 'https://dl.google.com/dl/android/maven2 ...
- linux 内存泄露检测工具
Valgrind Memcheck 一个强大开源的程序检测工具 下载地址:http://valgrind.org/downloads/current.html Valgrind快速入门指南:http: ...
- Oracle报错>记录被另外一个用户锁定
原因 当一个用户对数据进行修改时,若没有进行提交或者回滚,Oracle不允许其他用户修改该条数据,在这种情况下修改,就会出现:"记录被另外一个用户锁定"错误. 解决 查询用户.数据 ...