Spark学习进度-RDD
RDD
RDD 是什么
定义
RDD, 全称为 Resilient Distributed Datasets, 是一个容错的, 并行的数据结构, 可以让用户显式地将数据存储到磁盘和内存中, 并能控制数据的分区.
同时, RDD 还提供了一组丰富的操作来操作这些数据. 在这些操作中, 诸如 map, flatMap, filter 等转换操作实现了 Monad 模式, 很好地契合了 Scala 的集合操作. 除此之外, RDD 还提供了诸如 join, groupBy, reduceByKey 等更为方便的操作, 以支持常见的数据运算.
特点
RDD 是一个编程模型
RDD 允许用户显式的指定数据存放在内存或者磁盘
RDD 是分布式的, 用户可以控制 RDD 的分区
RDD 是一个编程模型
RDD 提供了丰富的操作
RDD 提供了 map, flatMap, filter 等操作符, 用以实现 Monad 模式
RDD 提供了 reduceByKey, groupByKey 等操作符, 用以操作 Key-Value 型数据
RDD 提供了 max, min, mean 等操作符, 用以操作数字型的数据
RDD 是混合型的编程模型, 可以支持迭代计算, 关系查询, MapReduce, 流计算
RDD 是只读的
RDD 之间有依赖关系, 根据执行操作的操作符的不同, 依赖关系可以分为宽依赖和窄依赖
创建 RDD
简略的说, RDD 有三种创建方式
RDD 可以通过本地集合直接创建
RDD 也可以通过读取外部数据集来创建
RDD 也可以通过其它的 RDD 衍生而来
通过本地集合直接创建 RDD
//从本地集合创建
@Test
def rddCreationLocal(): Unit ={ val seq=Seq(1,2,3)
val rdd1: RDD[Int] = sc.parallelize(seq, 2)
//区别在于,parallelize不需要指定分区个数,makeRDD需要指定分区个数
val rdd2: RDD[Int] = sc.makeRDD(seq, 2) }
通过读取外部文件创建 RDD
//从文件创建
@Test
def rddCreationHDFS(): Unit ={ sc.textFile("hdfs://hadoop101:8020/data/wordcount.txt")
// 1.textFile传入的是什么
// 传入的是路径,读取路径
// * hdfs://hadoop101:8020/../.. file:///... 一个是读hdfs,一个是读本地
// 2. 是否支持分区
// 如果传入的是hdfs,分区是由HDFS文件中block决定的
// 3.支持什么平台
// aws和阿里云 }
通过其它的 RDD 衍生新的 RDD
//从RDD衍生
@Test
def rddCreateFromRDD(): Unit ={ val rdd1 = sc.parallelize(Seq(1, 2, 3))
// 通过在rdd上执行算子操作,会生成新的 rdd
// 原地计算
// str.substr 返回新的字符串,非原地计算
// 和字符串中的方式很像,字符串是可变的吗?
// RDD可变吗》不可变
val rdd2 = rdd1.map(item => item) }
RDD 算子
Map 算子
@Test
def mapTest(): Unit ={ //1.创建RDD
val rdd1=sc.parallelize(Seq(1,2,3))
//2.执行map操作
val rdd2=rdd1.map(item =>item*10)
//3.得到结果
val result=rdd2.collect()
result.foreach(item=>println(item))
}
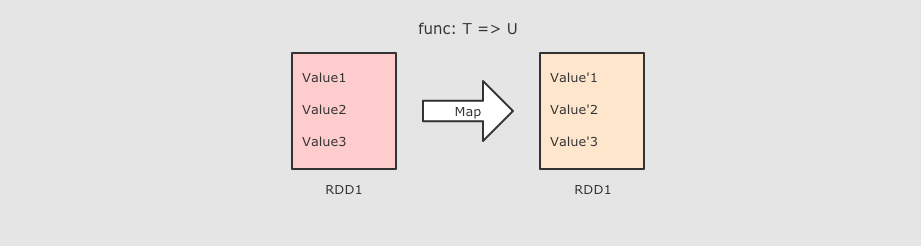
作用
把 RDD 中的数据 一对一 的转为另一种形式,Map是一对一
FlatMap 算子
@Test
def flatMapTest(): Unit ={ //1.创建RDD
val rdd1=sc.parallelize(Seq("Hello lily","Hello lucy","Hello tim"))
//2.处理数据
val rdd2: RDD[String] = rdd1.flatMap(item => item.split(" "))
//3.得到结果
val result=rdd2.collect()
result.foreach(item=>println(item))
//4.关闭sc
sc.stop()
}

作用
FlatMap 算子和 Map 算子类似, 但是 FlatMap 是一对多,flatMap 其实是两个操作, 是 map + flatten, 也就是先转换, 后把转换而来的 List 展开
ReduceByKey 算子
@Test
def reduceByKeyTest(): Unit ={
//1.创建RDD
val rdd1=sc.parallelize(Seq("Hello lily","Hello lucy","Hello tim"))
//2.处理数据
val rdd2=rdd1.flatMap(item => item.split(" "))
.map(item=>(item,1))
.reduceByKey((curr,agg) => curr+agg)
//3.得到结果
val result=rdd2.collect()
result.foreach(item=>println(item))
//4.关闭sc
sc.stop()
}
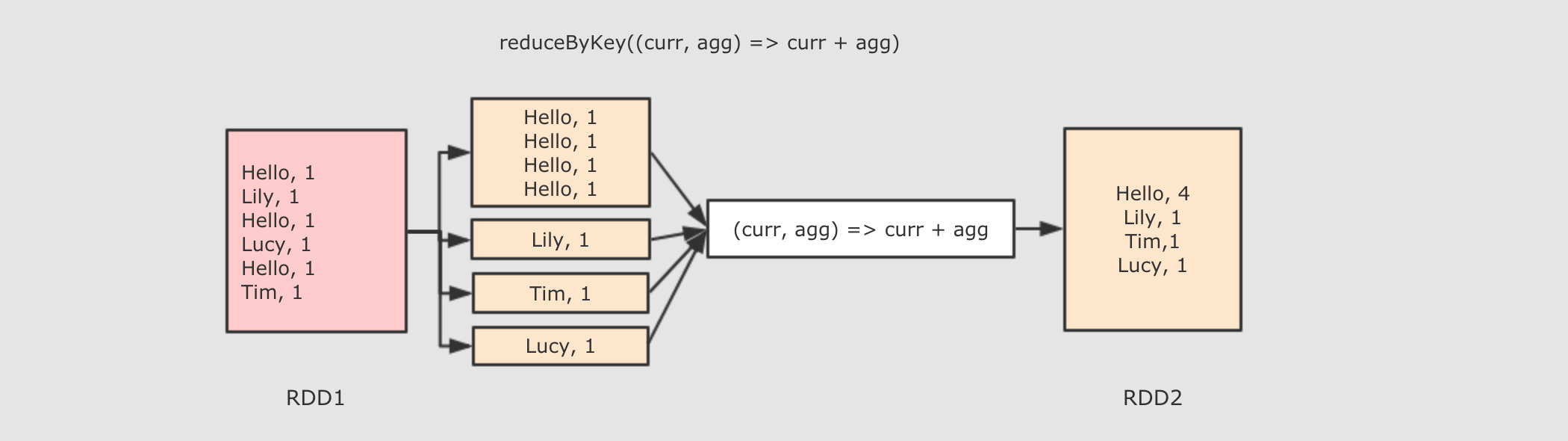

作用
首先按照 Key 分组, 接下来把整组的 Value 计算出一个聚合值, 这个操作非常类似于 MapReduce 中的 Reduce
参数
func → 执行数据处理的函数, 传入两个参数, 一个是当前值, 一个是局部汇总, 这个函数需要有一个输出, 输出就是这个 Key 的汇总结果,并进行更新
注意点
ReduceByKey 只能作用于 Key-Value 型数据, Key-Value 型数据在当前语境中特指 Tuple2
ReduceByKey 是一个需要 Shuffled 的操作
和其它的 Shuffled 相比, ReduceByKey是高效的, 因为类似 MapReduce 的, 在 Map 端有一个 Cominer, 这样 I/O 的数据便会减少
map 和 flatMap 算子都是转换, 只是 flatMap 在转换过后会再执行展开, 所以 map 是一对一, flatMap 是一对多
reduceByKey 类似 MapReduce 中的 Reduce
Spark学习进度-RDD的更多相关文章
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
- Spark学习之RDD
RDD概述 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的集合 ...
- Spark学习之RDD编程总结
Spark 对数据的核心抽象——弹性分布式数据集(Resilient Distributed Dataset,简称 RDD).RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外 ...
- Spark学习笔记——RDD编程
1.RDD——弹性分布式数据集(Resilient Distributed Dataset) RDD是一个分布式的元素集合,在Spark中,对数据的操作就是创建RDD.转换已有的RDD和调用RDD操作 ...
- spark学习(10)-RDD的介绍和常用算子
RDD(弹性分布式数据集,里面并不存储真正要计算的数据,你对RDD的操作,他会在Driver端转换成Task,下发到Executor计算分散在多台集群上的数据) RDD是一个代理,你对代理进行操作,他 ...
- Spark学习之RDD的理解
转自:http://www.infoq.com/cn/articles/spark-core-rdd/ 感谢张逸老师的无私分享 RDD,全称为Resilient Distributed Dataset ...
- spark 学习(二) RDD及共享变量
声明:本文基于spark的programming guide,并融合自己的相关理解整理而成 Spark应用程序总是包括着一个driver program(驱动程序),它运行着用户的main方 ...
- spark学习(RDD案例实战)
练习0(并行化创建RDD) 先启动spark-shell 通过并行化生成rdd scala> val rdd1 = sc.parallelize(List(63,45,89,23,144,777 ...
- Spark学习(2) RDD编程
什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.弹性.里面的元素可并行计算的集合 RDD允 ...
随机推荐
- moviepy音视频剪辑:与time时间线相关的变换函数freeze_region、make_loopable、speedx、time_mirror、time_symmetrize介绍
☞ ░ 前往老猿Python博文目录 ░ 一.引言 在<moviepy音视频剪辑:moviepy中的剪辑基类Clip详解>介绍了剪辑基类的fl.fl_time.fx方法,在<movi ...
- 图像处理gamma修正(伽马γ校正)的原理和实现算法
☞ ░ 前往老猿Python博文目录 ░ 本文转自博客园:淇淇宝贝的文章<图像处理之gamma校正>,原文链接:https://www.cnblogs.com/qiqibaby/p/532 ...
- Python中自定义类如果重写了__repr__方法为什么会影响到str的输出?
这是因为Python3中,str的输出是调用类的实例方法__str__来输出,如果__str__方法没有重写,则自动继承object类的__str__方法,而object类的__str__方法是调用_ ...
- PyQt(Python+Qt)学习随笔:Qt Designer中主窗口对象的dockOptions属性
dockOptions属性代表主窗口对浮动部件停靠的反应,其类型为枚举类型QMainWindow.DockOptions.相关取值及含义如下: 这些枚举值可以组合使用,仅控制如何在QMainWindo ...
- js中的(function(){})()立即执行
( function(){-} )() 和 ( function (){-} () ) 是两种javascript立即执行函数的常见写法,要理解立即执行函数,需要先理解一些函数的基本概念. 函数声明. ...
- Panda交易所获悉,五地股权市场获批参与「区块链建设试点」
Panda交易所获悉,北京市地方金融监督管理局官网于7月21日发布信息显示,"证监会发布<关于原则同意北京.上海.江苏.浙江.深圳等5家区域性股权市场开展区块链建设工作的函>,原 ...
- li = [11,22,33,44,55,66,77,88,99]分类
方法一: li = [11,22,33,44,55,66,77,88,99]s = []m = []for i in li: if i <= 55: s.append(i) else: m.ap ...
- Jmeter(5)JSON提取器
Jmeter后置处理器-JSON提取器 JSON是一种轻量级数据格式,以"键-值"对形式组织数据. JSON串中{}表示对象,[]表示对象组成的数组.对象包含多个"属性& ...
- 【转载】Django,学习笔记
[转自]https://www.cnblogs.com/jinbchen/p/11133225.html Django知识笔记 基本应用 创建项目: django-admin startproje ...
- Day5 - 04 函数的参数-可变参数*
传入的参数的个数是可变的. 例子:定义一个函数,通过给出一组数,返回这组数中最大值与最小值的和. def msum(numbers): r = max(numbers) + min ...