三层架构的一点理解以及Dapper一对多查询
1.首先说一下自己对三层架构的一点理解
论坛里经常说会出现喜欢面相对象的写法,所以使用EF的,我个人觉得他俩没啥关系,先别反对,先听听我怎么说吧.
三层架构,基本都快说烂了,但今天还是说三层架构:UI,BLL,DAL.之前往往强调的是三层架构各司其职,但没有说三层架构中每层之间怎么交互的,以及人员之间的分工合作问题.今天重点说这个,从而回答面向对象和EF的关系.
今天说的与数据库有关,那就先说BLL和DAL之间数据的传递.有不少都是按照以下两种方式写的:
(1)以Datatable传递.可想想,一个datatable对象,里面是什么呢?对于这样的方式作为业务层和数据库之间的桥梁不直观,并且无法应对变化,还不如写成一层.
(2)那我定义成对象不就直观了,所以有些就一张表定义一个对象,对象和数据库表一模一样.这样写呢,没比第一种好到哪去.首先数据库修改之后,Model得修改,Dal层也得修改.还有,这也是最重要的,如果两个人分别开发BLL和DAL,那这两个人必须都得熟悉数据库以及他们之间的对应关系.
那怎么样比较合适呢?
随着编程越来越成熟,细分不可避免.在公司中每个人只关心自己的那部分,三层分别划分为不同的人或团队编写.这样不只是从代码层面,从管理层面更符合术业有专攻,每层专注于自己的功能:
(1)业务人员更应该了解业务的编写,业务算法的实现,计算性能等,而无需关心数据怎么存储,无需学习数据库,无需关心索引,主键等等.
(2)UI更多的关心界面怎么布局,怎么做的更好看,更符合用户的使用等,而无需关心数据怎么存储,业务怎么计算等.
(3)数据库服务层(注意现在多加了服务两个字,很关键)更应该关心数据用什么去存储去满足高性能的数据增删改查,在这我没说非是关系型数据库,还是NoSql什么的,其实如果text,excel存储方便且能满足性能要求,又有何不可呢.
三层有了,那他们之间怎么衔接呢,答案就是业务,每个业务都需要展示,计算(简单业务不需要),存储数据,这不就是三层人员需要干的事吗,根据展示的数据定义好对象作为UI和BLL层之间的传输对象.存储也一样,根据业务需要存储数据的特征定义好存储的对象,作为BLL和DAL之间交互的对象.实际这两个对象就是三层交互的公约,有了这个公约,每层开发根据公约实现每层的功能,每层的编程人员也不再需要关心其他层怎么实现的.DAl层已经不仅仅是数据库这么简单了,而是对对象增删改查.
这样做的好处:
(1)人员更加专业,分工明确后,每个人专业技能容易提升
(2)只要交互的对象不发生改变,三层随意修改,都不会影响到其他两层.
(3)编程人员更容易形成自己的模式,加快开发速度.
(4)编写人员接触多了,踩过的坑就越多,编写的代码也就越健康.等等吧,好处大大滴.
说了这么多,现在回答EF的问题,根据以上划分的三层,EF必然归数据服务层了.如果是写UI或业务的人员,那面不面向对象与EF没有任何关系.数据服务层就是实现对象的增删改查,如果使用的关系型数据库,那使用EF到底能简化多少行代码,我觉得一般般吧.
微软总喜欢给用户一整套解决方案,比如MVC,用微软的VS直接可以生成MVC框架,但MVC不是真正意义上的前后端分离.同样EF更偏向于一个人来完成所有层的编写.
2.性能
性能都说Dapper与原生ADO.NET差不多,其处理过程是一样的(个人理解,没有深究,有不对的请指导.):
ADO.NET是把查询的赋值给datatable或dataset.
Dapper是利用委托的方式,把每行的数据处理之后再赋值给对象.如果不用委托,那就直接把每行查出来的数据赋值给对象即可.最后生成一个集合.
EF应该是根据设置的主外键关系生成sql语句,然后再去查询.但对于复杂的查询,自动生成sql语句就没那么容易了,在考虑索引的问题,那就是难上加难了,可能会经常出现不使用索引的情况,导致查询速度慢.
3.Dapper实现一对多查询
既然说一对多,那就整个复杂的,两级一对多查询.有更复杂的也希望大家提供.
公司分为多个部门,每个部门又有很多员工.
3.1先建立表,并添加示例数据
USE [test]
GO
/****** Object: Table [dbo].[staff] Script Date: 11/12/2019 10:18:55 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[staff](
[id] [int] IDENTITY(1,1) NOT NULL,
[part_id] [int] NOT NULL,
[name] [nvarchar](50) NULL
) ON [PRIMARY]
GO
SET IDENTITY_INSERT [dbo].[staff] ON
INSERT [dbo].[staff] ([id], [part_id], [name]) VALUES (1, 1, N'员工1')
INSERT [dbo].[staff] ([id], [part_id], [name]) VALUES (2, 1, N'员工2')
INSERT [dbo].[staff] ([id], [part_id], [name]) VALUES (3, 1, N'员工3')
INSERT [dbo].[staff] ([id], [part_id], [name]) VALUES (4, 2, N'员工4')
INSERT [dbo].[staff] ([id], [part_id], [name]) VALUES (6, 2, N'员工5')
INSERT [dbo].[staff] ([id], [part_id], [name]) VALUES (7, 3, N'员工6')
SET IDENTITY_INSERT [dbo].[staff] OFF
/****** Object: Table [dbo].[department] Script Date: 11/12/2019 10:18:55 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[department](
[id] [int] IDENTITY(1,1) NOT NULL,
[com_id] [int] NOT NULL,
[name] [nvarchar](50) NULL
) ON [PRIMARY]
GO
SET IDENTITY_INSERT [dbo].[department] ON
INSERT [dbo].[department] ([id], [com_id], [name]) VALUES (1, 1, N'部门1')
INSERT [dbo].[department] ([id], [com_id], [name]) VALUES (2, 1, N'部门2')
INSERT [dbo].[department] ([id], [com_id], [name]) VALUES (3, 2, N'部门1')
INSERT [dbo].[department] ([id], [com_id], [name]) VALUES (4, 2, N'部门3')
SET IDENTITY_INSERT [dbo].[department] OFF
/****** Object: Table [dbo].[company] Script Date: 11/12/2019 10:18:55 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[company](
[id] [int] IDENTITY(1,1) NOT NULL,
[name] [nvarchar](50) NULL
) ON [PRIMARY]
GO
SET IDENTITY_INSERT [dbo].[company] ON
INSERT [dbo].[company] ([id], [name]) VALUES (1, N'公司1')
INSERT [dbo].[company] ([id], [name]) VALUES (2, N'公司2')
INSERT [dbo].[company] ([id], [name]) VALUES (3, N'公司3')
SET IDENTITY_INSERT [dbo].[company] OFF
3.2对象定义
(1)公司
/// <summary>
/// 公司
/// </summary>
public class Company
{
/// <summary>
/// 公司ID
/// </summary>
public int CompanyID { get; set; }
/// <summary>
///公司名称
/// </summary>
public string CompanyName { get; set; }
/// <summary>
/// 公司包含的部门
/// </summary>
public List<Department> Department { get; set; }
}
(2)部门
/// <summary>
/// 部门
/// </summary>
public class Department
{
/// <summary>
/// 部门ID
/// </summary>
public int DepartmentID { get; set; }
/// <summary>
/// 部门名称
/// </summary>
public string DepartmentName { get; set; }
/// <summary>
/// 部门包含的员工
/// </summary>
public List<Staff> Staff { get; set; }
}
(3)员工
/// <summary>
/// 员工
/// </summary>
public class Staff
{
/// <summary>
/// 员工ID
/// </summary>
public int StaffID { get; set; }
/// <summary>
/// 员工姓名
/// </summary>
public string StaffName { get; set; }
}
3.3不使用委托
/// <summary>
/// 不用委托
/// </summary>
public static List<Company> NoDelegate()
{
using (IDbConnection conn = new SqlConnection("Data Source = .;Initial Catalog = test;User Id = sa;Password = sa;"))
{
string sql = "SELECT com.id CompanyID,com.name CompanyName,part.id DepartmentID, part.name DepartmentName,st.ID StaffID, st.name StaffName FROM company com LEFT JOIN department part ON part.com_id=com.id LEFT JOIN staff st ON st.part_id=part.id";
return conn.Query<Company>(sql).AsList();
}
}
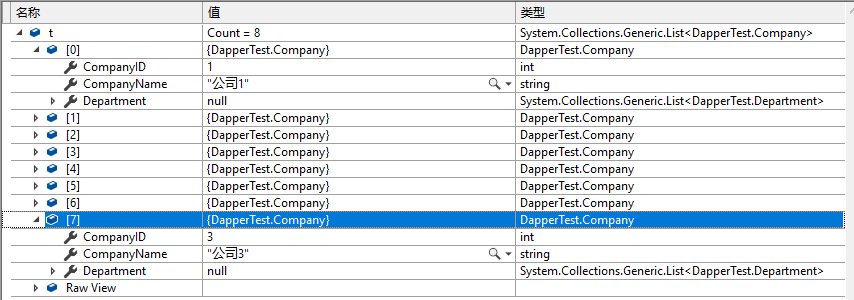
没有做级联处理,所以每一行结果就是一个Company对象,一共8行,结果就是8个Company对象的集合.
3.4使用委托
/// <summary>
/// 使用委托
/// </summary>
/// <returns></returns>
public static List<Company> UseDelegate()
{
using (IDbConnection conn = new SqlConnection("Data Source = .;Initial Catalog = test;User Id = sa;Password = sa;"))
{
string sql = "SELECT com.id CompanyID,com.name CompanyName,part.id DepartmentID, part.name DepartmentName,st.ID StaffID, st.name StaffName FROM company com LEFT JOIN Department part ON part.com_id=com.id LEFT JOIN staff st ON st.part_id=part.id";
var res = new List<Company>();
conn.Query<Company, Department, Staff, Company>(sql, (com, part, staff) =>
{
//查找是否存在该公司
var t = res.Where(p => p.CompanyID == com.CompanyID).FirstOrDefault();
//如果没有该公司,则添加该公司
if (t == null)
{
t = new Company() { CompanyID = com.CompanyID, CompanyName = com.CompanyName };
res.Add(t);
}
//先判断该行数据的part是否为空,如果为空则不做任何处理.
Department parttmp = null;
if (part != null)
{
if (t.Department == null)
t.Department = new List<Department>();
parttmp = t.Department.Where(p => p.DepartmentID == part.DepartmentID).FirstOrDefault();
if (parttmp == null)
{
parttmp = part;
t.Department.Add(part);
}
}
//判断该行数据的员工是否为空
if (staff != null)
{
if (parttmp.Staff == null)
parttmp.Staff = new List<Staff>();
parttmp.Staff.Add(staff);
}
return com;//没有任何意义,不过委托需要有返回值.
}, splitOn: "DepartmentID,StaffID");
return res;
}
}
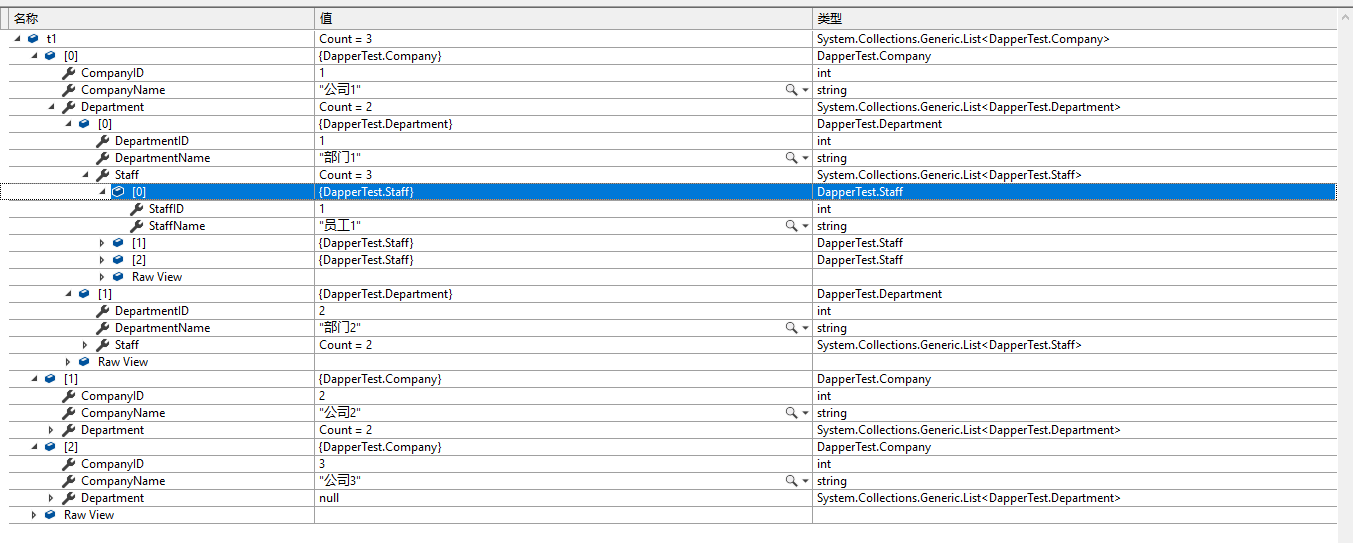
做级联处理,一共3个公司,所以结果是3个Company的集合.每个Company分别包含下属的部门和员工.
3.5使用ADO.NET查询DataTable,并转换成对象
/// <summary>
/// 利用datatable实现,为了测试性能,所以不再整理成级联的形式.
/// </summary>
/// <returns></returns>
public static List<Company> UseTable()
{
List<Company> res = new List<Company>();
DataTable dt = new DataTable();
using (SqlConnection conn = new SqlConnection("Data Source = .;Initial Catalog = test;User Id = sa;Password = sa;"))
{
if (conn.State != ConnectionState.Open)
conn.Open();
SqlCommand sqlCommand = new SqlCommand("SELECT com.id CompanyID,com.name CompanyName,part.id DepartmentID, part.name DepartmentName,st.ID StaffID, st.name StaffName FROM company com LEFT JOIN Department part ON part.com_id=com.id LEFT JOIN staff st ON st.part_id=part.id", conn)
{
CommandType = CommandType.Text
};
SqlDataAdapter da = new SqlDataAdapter
{
SelectCommand = sqlCommand
};
da.Fill(dt);
}
for (int i = ; i < dt.Rows.Count; i++)
{
res.Add(new Company()
{ CompanyID = Convert.ToInt32(dt.Rows[i]["CompanyID"]),
CompanyName = dt.Rows[i]["CompanyName"].ToString(),
Department = new List<Department>() { dt.Rows[i]["DepartmentID"]!=DBNull.Value? new Department() {
DepartmentID = Convert.ToInt32(dt.Rows[i]["DepartmentID"]),
DepartmentName = dt.Rows[i]["DepartmentName"].ToString(),
Staff = new List<Staff>() {
dt.Rows[i]["StaffID"]!=DBNull.Value? new Staff() {
StaffID =Convert.ToInt32(dt.Rows[i]["StaffID"]),
StaffName =dt.Rows[i]["StaffName"].ToString() }:null
}
}:null
}
});
}
return res;
}
}
查询结果与第一种一致.
3.6性能对比
每个循环执行10000次,记录执行的时间.在自己的电脑上测试的.不同电脑有所差异,每次运行所用时间也不同,非专业测试.但能说明问题.
static void Main(string[] args)
{
Stopwatch sw = new Stopwatch();
sw.Restart();
for (int i = ; i < ; i++)
{
var t = NoDelegate();
}
sw.Stop();
Console.Write("不用委托的时间:" + sw.ElapsedMilliseconds);
Console.WriteLine();
sw.Restart();
for (int i = ; i < ; i++)
{
var t1 = UseDelegate();
}
sw.Stop();
Console.Write("使用委托的时间:" + sw.ElapsedMilliseconds);
Console.WriteLine();
sw.Restart();
for (int i = ; i < ; i++)
{
var t2 = UseTable();
}
sw.Stop();
Console.Write("使用DataTable的时间:" + sw.ElapsedMilliseconds);
Console.ReadLine();
}
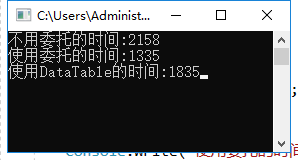
运行了好几次,结果大致就是这样:
(1)使用Dapper,但不做级联处理,时间最长.
(2)使用Dapper,做级联处理,耗时最短.
(3)使用DataTable,耗时在两者之间.
原因分析(个人理解):
以上三种情况的区别可以分为两点:
第一点执行过程:Dapper执行一次.ADO.NET先查询出DataTable,然后再转换为对象.
第二点转换对象方式:Dapper是利用Emit把数据转换成对象,使用DataTable实例化对象是先初始化对象再赋值;
基于以上的区别,三种方式执行耗时的原因如下:
第一种方式虽然不像第三种方式经过两步,但由于数据转换对象的次数较多,并且使用Emit转换而不是直接定义对象的方式赋值,所以耗时较长.
第二种方式即在每行查询的过程中给对象赋值,并且由于判断了公司和部门是否存在,数据转换到对象的次数明显少了很多.
第三种方式由于先把查询的结果赋值给DataTable,然后再把DataTable转换成对象,经过两步,比第二种方式耗时多一点,但优于第一种.
3.7第二种方式编写知识点说明
(1)执行过程,分为三步:
先定义一个Company集合,也就是返回值;
Dapper逐行处理SQL语句的查询结果,并添加到返回值的集合中;
最后返回Company集合.
(2) 解释Query中的四个对象Company,Department,Staff,Company
Dapper每行查询后会根据SQL语句和splitOn定义的分隔形成前三个对象(Company,Department,Staff)
最后一个Company定义了该Query查询的结果是Company的集合.
(3)委托的作用
委托就是定义Dapper以什么样的方式处理每行数据.本例中,处理流程:
Dapper查询出每行数据以后,定义的委托先判断在结果集合中(res:Company集合)判断是否存在该行数据指定的公司,如果不存在该公司,利用该行的公司数据初始化一个新的公司对象,并添加到res中.
然后判断该公司中是否存在该行数据指定的部门,如果不存在同样利用该行的部门数据实例化一个部门,并添加到公司对象中.
最后把员工添加到该行数据指定的部门中,员工不会出现重复.完成一行数据的处理.
以上过程可以在委托中打断点,看整个执行过程.
(4)splitOn
splitOn是为了帮助Dapper在查询每行的数据后,划分为指定的三个对象(Company,Department,Staff).在该实例中三个对象包含的字段分别是:
com.id CompanyID,com.name CompanyName;
part.id PartMentID, part.name PartMentName;
st.ID StaffID, st.name StaffName;
因此利用每个对象的第一个字段作为分隔符区分三个对象.例如splitOn: "DepartmentID,StaffID"中DepartmentID表示第二个对象(Department)的第一个字段,StaffID是第三个对象(Staff)的第一个字段.
(5)null值处理
在初始化Company和Department时,都未同时实例化其包含的部门集合和员工集合.以Company说明:
在查找结果集合中未包含当前查询行的公司时,需要实例化一个Company,然后利用该行的数据实例化一个Company对象,并添加到结果集合中.
t = new Company() { CompanyID = com.CompanyID, CompanyName = com.CompanyName };
没有写成 t = new Company() { CompanyID = com.CompanyID, CompanyName = com.CompanyName,Department = new List<Department>() };
也就是没有对t的Department 进行初始化.而是先判断该行的Department是否存在( if (part != null)),如果存在再判断Department 是否为空,为空则进行实例化,否则就让Department 为空.
这样是为了可以直接通过Department 是否为null判断数据的完整性,如果先实例化,那么判断数据的完整性的时候还需要判断Department 个数是否大于0.
三层架构的一点理解以及Dapper一对多查询的更多相关文章
- Dapper 一对多查询 one to many
参考文档:Dapper one to many Table public class Person { public int Id { get; set; } public string Name { ...
- c#利用三层架构做一个简单的登录窗体
就个人而言,三层架构有点难理解,不知道该如何下手,各层与各层之间怎么调用 最近一直在研究三层架构,经过网上学习与多方打听写一下自己的心得.有不足之处,可以评论和私聊探讨 言归正传: 三层架构(3-ti ...
- ASP.NET三层架构之不确定查询参数个数的查询
在做三层架构的时候,特别是对表做查询的时候,有时候并不确定查询条件的个数,比如查询学生表:有可能只输入学号,或者姓名,或者性别,总之查询条件的参数个数并不确定,下面是我用List实现传值的代码: 附图 ...
- 关于三层架构与MVC的一些理解
刚毕业的时候,参与了一个上位机的系统开发.上位机所使用的是.net Windows Form技术. 当时,和一个北理的姑娘在一个项目组里.因为她来公司时间比较长,而且经验比较丰富,所以,上位机的架构由 ...
- 利用Dapper ORM搭建三层架构
利用Dapper关系对象映射器写的简单的三层架构.Dapper:StackOverFlow在使用的一个微型的ORM,框架整体效率较高,轻量级的ORM框架.网上有较多的扩展.此处只是简单的调用Dappe ...
- 关于ASP.NET或VS2005 搭建三层架构的理解
最近想学习ASP.NET建网站,关于ASP.NET或VS2005 搭建三层架构的理解,网上摘录了一些资料,对于第(2)点的讲解让我理解印象深刻,如下: (1)为何使用N层架构? 因为每一层都可以在仅仅 ...
- 三层架构中bll层把datatable转换为实体model的理解
看了很多人的项目,很多都是用到三层架构,其中BLL层中有一种将DataTable转换为实体的方法.一直没有明白为啥要这样做,今天特意去搜索了一下,如果没有答案我是准备提问,寻求解答了.还好找到一个相关 ...
- Net系列框架-Dapper+简单三层架构
Net系列框架-Dapper+简单三层架构 工作将近6年多了,工作中也陆陆续续学习和搭建了不少的框架,后续将按由浅入深的方式,整理出一些框架源码,所有框架源码本人都亲自调试通过,如果有问题,欢迎联系我 ...
- 【转载】 JAVA三层架构,持久层,业务层,表现层的理解
JAVA三层架构,持久层,业务层,表现层的理解 转载:http://blog.csdn.net/ljf_study/article/details/64443653 SSH: Struts(表示层)+ ...
随机推荐
- .NetCore 配合 Gitlab CI&CD 实践 - 单体项目
前言 上一篇博文 .NetCore 配合 Gitlab CI&CD 实践 - 开篇,主要简单的介绍了一下 GitLab CI 的持续集成以及持续部署,这篇将通过 GitLab CI 发布一个 ...
- WordPress固定链接后404的解决方法
一般Wordpress自带的链接是一大串数字加符号,不美观也不明确,一般要设置成固定链接,而设置成功后大部分情况访问文章,子链接都会出现404界面,我找了网上的资料,才知道需要配置伪静态链接, 一般的 ...
- 强开企业付款到零钱与现金红包,无需等待90/30天,2-12H即可强开通!
一.微信官方给出的,企业付款到零钱|现金红包开通的说明 针对入账方式为即时入账至商户号,结算周期为T+1的商户,需满足三个条件:1)入驻满90天,2)连续正常交易30天,3)保持正常健康交易.其余结算 ...
- C#LeetCode刷题之#268-缺失数字(Missing Number)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/4056 访问. 给定一个包含 0, 1, 2, ..., n 中 ...
- 手写AOP实现过程
一.手写Aop前基础知识 1.aop是什么? 面向切面编程(AOP):是一种编程范式,提供从另一个角度来考虑程序结构从而完善面向对象编程(OOP). 在进行OOP开发时,都是基于对组件(比如类)进行开 ...
- STL函数库的应用第四弹——全排列(+浅谈骗分策略)
因为基础算法快学完了,图论又太难(我太蒻了),想慢慢学. 所以暂时不写关于算法的博客了,但又因为更新博客的需要,会多写写关于STL的博客. (毕竟STL函数库还是很香的(手动滑稽)) 请出今天主角:S ...
- 01@-tornado
import tornado.web ''' tornado的基础web框架模块 ''' import tornado.ioloop ''' tornado的核心IO循环模块 封装了Linux的epo ...
- SSM框架整合练习——一个简单的文章管理系统
使用SSM框架搭建的简易文章管理系统,实现了简单的增删改查功能. @ 目录 开发工具版本: 最终的项目结构 IDEA+Maven搭建项目骨架 1. 新建Maven项目: 2. 在新建的项目中添加所需要 ...
- java+opencv实现图像灰度化
灰度图像上每个像素的颜色值又称为灰度,指黑白图像中点的颜色深度,范围一般从0到255,白色为255,黑色为0.所谓灰度值是指色彩的浓淡程度,灰度直方图是指一幅数字图像中,对应每一个灰度值统计出具有该灰 ...
- Hitool打开出现failed to create the java virtual machine
今天在安装Hitool后,打开hitool后出现了错误:failed to create the java virtual machine. 解决方法如下: 记事本打开HiTool.ini -star ...