explain关键字使用解释
原文: 58沈剑 架构师之路 https://mp.weixin.qq.com/s/oWNrLHwqM-0ObuYbuGj98A
《数据库允许空值,往往是悲剧的开始》一文通过explain来分析SQL的执行计划,来分析null对索引命中情况的影响,有不少朋友留言,问explain结果中的type字段,ref,ALL等不一样的值究竟是什么含义。
今天简单说下,常见的type结果及代表的含义,并且通过同一个SQL语句的性能差异,说明建对索引多么重要。
explain结果中的type字段代表什么意思?

MySQL的官网解释非常简洁,只用了3个单词:连接类型(the join type)。它描述了找到所需数据使用的扫描方式。
最为常见的扫描方式有:
- system:系统表,少量数据,往往不需要进行磁盘IO;
- const:常量连接;
- eq_ref:主键索引(primary key)或者非空唯一索引(unique not null)等值扫描;
- ref:非主键非唯一索引等值扫描;
- range:范围扫描;
- index:索引树扫描;
- ALL:全表扫描(full table scan);
画外音:这些是最常见的,大家去explain自己工作中的SQL语句,95%都是上面这些类型。
上面各类扫描方式由快到慢:system > const > eq_ref > ref > range > index > ALL
下面一一举例说明。
1. system

explain select * from mysql.time_zone;
上例中,从系统库mysql的系统表time_zone里查询数据,扫码类型为system,这些数据已经加载到内存里,不需要进行磁盘IO。这类扫描是速度最快的。

explain select * from (select * from user where id=1) tmp;
再举一个例子,内层嵌套(const)返回了一个临时表,外层嵌套从临时表查询,其扫描类型也是system,也不需要走磁盘IO,速度超快。
2. const
数据准备:
create table user (
id int primary key,
name varchar(20)
)engine=innodb; insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi');

const扫描的条件为:(1)命中主键(primary key)或者唯一(unique)索引;(2)被连接的部分是一个常量(const)值;
explain select * from user where id=1;
如上例,id是PK,连接部分是常量1。
画外音:别搞什么类型转换的幺蛾子。
这类扫描效率极高,返回数据量少,速度非常快。
3. eq_ref
数据准备:
create table user (
id int primary key,
name varchar(20)
)engine=innodb; insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi'); create table user_ex (
id int primary key,
age int
)engine=innodb; insert into user_ex values(1,18);
insert into user_ex values(2,20);
insert into user_ex values(3,30);
insert into user_ex values(4,40);
insert into user_ex values(5,50);

eq_ref扫描的条件为,对于前表的每一行(row),后表只有一行被扫描。
再细化一点:(1)join查询;(2)命中主键(primary key)或者非空唯一(unique not null)索引;(3)等值连接;
explain select * from user,user_ex where user.id=user_ex.id;
如上例,id是主键,该join查询为eq_ref扫描。
这类扫描的速度也异常之快。
4. ref
数据准备:
create table user (
id int,
name varchar(20) ,
index(id)
)engine=innodb;
insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi'); create table user_ex (
id int,
age int,
index(id)
)engine=innodb;
insert into user_ex values(1,18);
insert into user_ex values(2,20);
insert into user_ex values(3,30);
insert into user_ex values(4,40);
insert into user_ex values(5,50);

如果把上例eq_ref案例中的主键索引,改为普通非唯一(non unique)索引。
explain select * from user,user_ex where user.id=user_ex.id;
就由eq_ref降级为了ref,此时对于前表的每一行(row),后表可能有多于一行的数据被扫描。

explain select * from user where id=1;
当id改为普通非唯一索引后,常量的连接查询,也由const降级为了ref,因为也可能有多于一行的数据被扫描。
ref扫描,可能出现在join里,也可能出现在单表普通索引里,每一次匹配可能有多行数据返回,虽然它比eq_ref要慢,但它仍然是一个很快的join类型。
5. range
数据准备:
create table user (
id int primary key,
name varchar(20)
)engine=innodb; insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi');
insert into user values(4,'wangwu');
insert into user values(5,'zhaoliu');
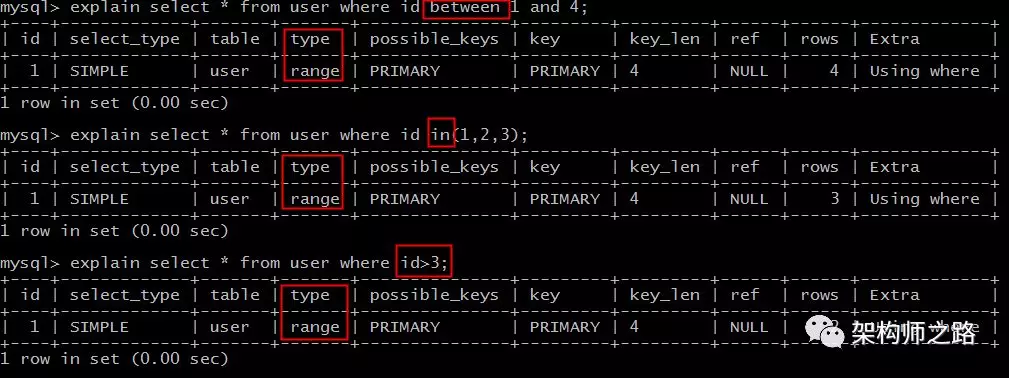
range扫描就比较好理解了,它是索引上的范围查询,它会在索引上扫码特定范围内的值。
explain select * from user where id between 1 and 4;
explain select * from user where id in (1,2,3);
explain select * from user where id>3;
像上例中的between,in,>都是典型的范围(range)查询。
画外音:必须是索引,否则不能批量"跳过"。
6. index

index类型,需要扫描索引上的全部数据。
explain count (*) from user;
如上例,id是主键,该count查询需要通过扫描索引上的全部数据来计数。
画外音:此表为InnoDB引擎。
它仅比全表扫描快一点。
7. ALL
数据准备:
create table user (
id int,
name varchar(20)
)engine=innodb; insert into user values(1,'shenjian');
insert into user values(2,'zhangsan');
insert into user values(3,'lisi'); create table user_ex (
id int,
age int
)engine=innodb; insert into user_ex values(1,18);
insert into user_ex values(2,20);
insert into user_ex values(3,30);
insert into user_ex values(4,40);
insert into user_ex values(5,50);

explain select * from user,user_ex where user.id=user_ex.id;
如果id上不建索引,对于前表的每一行(row),后表都要被全表扫描。
今天这篇文章中,这个相同的join语句出现了三次:
(1)扫描类型为eq_ref,此时id为主键;
(2)扫描类型为ref,此时id为非唯一普通索引;
(3)扫描类型为ALL,全表扫描,此时id上无索引;
有此可见,建立正确的索引,对数据库性能的提升是多么重要。
全表扫描代价极大,性能很低,是应当极力避免的,通过explain分析SQL语句,非常有必要。
总结
(1)explain结果中的type字段,表示(广义)连接类型,它描述了找到所需数据使用的扫描方式;
(2)常见的扫描类型有: system > const > eq_ref > ref > range > index > ALL 其扫描速度由快到慢;
(3)各类扫描类型的要点是:
system最快:不进行磁盘IO
const:PK或者unique上的等值查询
eq_ref:PK或者unique上的join查询,等值匹配,对于前表的每一行(row),后表只有一行命中
ref:非唯一索引,等值匹配,可能有多行命中
range:索引上的范围扫描,例如:between/in/>
index:索引上的全集扫描,例如:InnoDB的count
ALL最慢:全表扫描(full table scan)
(4)建立正确的索引(index),非常重要;
(5)使用explain了解并优化执行计划,非常重要;
思路比结论重要,希望大家有收获。本文测试于MySQL5.6。
explain关键字使用解释的更多相关文章
- Spring+SpringMVC+MyBatis+easyUI整合优化篇(十二)数据层优化-explain关键字及慢sql优化
本文提要 从编码角度来优化数据层的话,我首先会去查一下项目中运行的sql语句,定位到瓶颈是否出现在这里,首先去优化sql语句,而慢sql就是其中的主要优化对象,对于慢sql,顾名思义就是花费较多执行时 ...
- Mysql EXPLAIN列的解释
转自:http://blog.chinaunix.net/uid-540802-id-3419311.html explain显示了mysql如何使用索引来处理select语句以及连接表.可以帮助选择 ...
- mysql explain字段意思解释
mysql explain字段意思解释 explain包含id.select_type.table.type.possible_keys.key.key_len.ref.rows.extra字段 id ...
- mysql索引优化及explain关键字段解释
一.explain关键字解释 1.id MySQL QueryOptimizer 选定的执行计划中查询的序列号,表示查询中执行select 子句或操作表的顺序.id 值越大优先级越高,越先被执行.id ...
- 手把手教你彻底理解MySQL的explain关键字
数据库是程序员必备的一项基本技能,基本每次面试必问.对于刚出校门的程序员,你只要学会如何使用就行了,但越往后工作越发现,仅仅会写sql语句是万万不行的.写出的sql,如果性能不好,达不到要求,可能会阻 ...
- sql关键字的解释执行顺序
sql关键字的解释执行顺序 分类: 笔试面试总结2013-03-17 14:49 1622人阅读 评论(1) 收藏 举报 SQL关键字顺序 表里面的字段名什么符号都不加,值的话一律加上单引号 有一 ...
- MySQL的Explain关键字查看是否使用索引
explain显示了MySQL如何使用索引来处理select语句以及连接表.可以帮助选择更好的索引和写出更优化的查询语句.简单讲,它的作用就是分析查询性能. explain关键字的使用方法很简单,就是 ...
- static_cast 、const_cast、dynamic_cast、reinterpret_cast 关键字简单解释
static_cast .const_cast.dynamic_cast.reinterpret_cast 关键字简单解释: Static_cast 静态类型转换 ①用于类层次结构中基类(父类)和派生 ...
- MySQL 优化之 EXPLAIN 关键字
MySQL查询优化之explain的深入解析 0. 准备 首先执行如下的 sql 语句: CREATE TABLE IF NOT EXISTS `article` (`id` int(10) unsi ...
随机推荐
- Jmeter(十五) - 从入门到精通 - JMeter导入自定义的Jar包(详解教程)
1.简介 原计划这一篇是介绍前置处理器的基础知识的,结果由于许多小伙伴或者童鞋们在微信和博客园的短消息中留言问如何引入自己定义的Jar包呢???我一一回复告诉他们和引入插件的Jar包一样的道理,一通百 ...
- java 面向对象(五):类结构 方法(二) 关键字:return;方法的重载;可变个数形参的方法
return关键字:1.使用范围:使用在方法体中2.作用:① 结束方法 * ② 针对于返回值类型的方法,使用"return 数据"方法返回所要的数据.3.注意点:return关键字 ...
- 数据可视化之powerBI基础(三)编辑交互,体验更灵活的PowerBI可视化
https://zhuanlan.zhihu.com/p/64412190 PowerBI可视化与传统图表的一大区别,就是可视化分析是动态的,通过页面上筛选.钻取.突出显示等交互功能,可以快速进行访问 ...
- three.js 曲线
上几篇说了three.js的曲线,这篇来郭先生来说说three.js曲线,在线案例点击郭先生的博客查看. 1. 了解three.js曲线 之前已经说了一些three.js的几何体,这篇说一说three ...
- Crawlab Lite 正式发布,更轻量的爬虫管理平台
Crawlab 是一款基于 Golang 的分布式爬虫管理平台,产品发布已经一年有余,经过开发团队的不断打磨,即将迭代到 v0.5 版本.在这期间我们为 Crawlab 加入了大量社区用户共同期望的功 ...
- Python Ethical Hacking - Intercepting and Modifying Packets
INTERCEPTING & MODIFYING PACKETS Scapy can be used to: Create packets. Analyze packets. Send/rec ...
- 性能测试必备知识(4)- 使用 stress 和 sysstat
做性能测试的必备知识系列,可以看下面链接的文章哦 https://www.cnblogs.com/poloyy/category/1806772.html stress 介绍 Linux 系统压力测试 ...
- css : 使用浮动实现左右各放一个元素时很容易犯的错误
比如说,有一个div,我想在左侧和右侧各方一个元素. 如果不想用flex,那就只能用浮动了. ... <div class="up clearfix"> <h6& ...
- css 过渡样式 transition
过渡顾名思义就是就是样式改变的一个过程变化 简介 transition: property duration timing-function delay; 值 描述 transition-proper ...
- 题解 洛谷 P3710 【方方方的数据结构】
因为有撤销操作,所以修改操作可能会只会存在一段时间,因此把时间看作一维,被修改的序列看作一维. 可以把操作都离线下来,对于每个修改操作,就是在二维平面上对一个矩形进行修改,询问操作,就是查询单点权值. ...