康复计划#4 快速构造支配树的Lengauer-Tarjan算法
本篇口胡写给我自己这样的老是证错东西的口胡选手 以及那些想学支配树,又不想啃论文原文的人…
大概会讲的东西是求支配树时需要用到的一些性质,以及构造支配树的算法实现…
最后讲一下把只有路径压缩的并查集卡到$O(m \log n)$上界的办法作为小彩蛋…
1、基本介绍 支配树 DominatorTree
对于一个流程图(单源有向图)上的每个点$w$,都存在点$d$满足去掉$d$之后起点无法到达$w$,我们称作$d$支配$w$,$d$是$w$的一个支配点。

支配$w$的点可以有多个,但是至少会有一个。显然,对于起点以外的点,它们都有两个平凡的支配点,一个是自己,一个是起点。
在支配$w$的点中,如果一个支配点$i \neq w$满足$i$被$w$剩下的所有非平凡支配点支配,则这个$i$称作$w$的最近支配点(immediate dominator),记作$idom(w)$。
定理1:我们把图的起点称作$r$,除$r$以外每个点均存在唯一的$idom$。
这个的证明很简单:如果$a$支配$b$且$b$支配$c$,则$a$一定支配$c$,因为到达$c$的路径都经过了$b$所以必须经过$a$;如果$b$支配$c$且$a$支配$c$,则$a$支配$b$(或者$b$支配$a$),否则存在从$r$到$b$再到$c$的路径绕过$a$,与$a$支配$c$矛盾。这就意味着支配定义了点$w$的支配点集合上的一个全序关系,所以一定可以找到一个“最小”的元素使得所有元素都支配它。
于是,连上所有$r$以外的$idom(w) \to w$的边,就能得到一棵树,其中每个点支配它子树中的所有点,它就是支配树。

支配树有很多食用…哦不…是实际用途。比如它展示了一个信息传递网络的关键点,如果一个点支配了很多点,那么这个点的传递效率和稳定性要求都会很高。比如Java的内存分析工具(Memory Analyzer Tool)里面就可以查看对象间引用关系的支配树…很多分析上支配树都是一个重要的参考。
为了能够求出支配树,我们下面来介绍一下需要用到的基本性质。
2、支配树相关性质
首先,我们会使用一棵DFS树来帮助我们计算。从起点出发进行DFS就可以得到一棵DFS树。
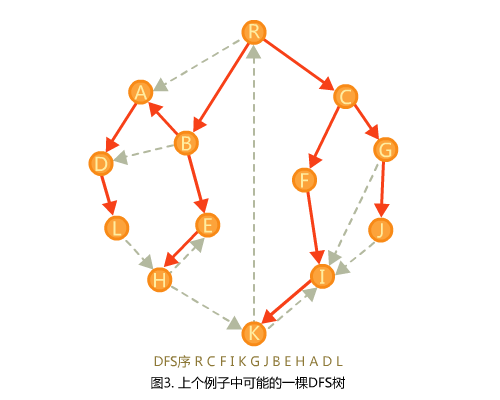
观察上面这幅图,我们可以注意到原图中的边被分为了几类。在DFS树上出现的边称作树边,剩下的边称为非树边。非树边也可以分为几类,从祖先指向后代(前向边),从后代指向祖先(后向边),从一棵子树內指向另一棵子树内(横叉边)。树边是我们非常熟悉的,所以着重考虑一下非树边。
我们按照DFS到的先后顺序给点从小到大编号(在下面的内容中我们通过这个比较两个节点),那么前向边总是由编号小的指向编号大的,后向边总是由大指向小,横叉边也总是由大指向小。现在在DFS树上我们要证明一些重要的引理:
引理1(路径引理):
如果两个点$v,w$满足$v \leq w$,那么任意$v$到$w$的路径经过$v,w$的公共祖先。(注意这里不是说LCA)
证明:
如果$v,w$其中一个是另一个的祖先显然成立。否则删掉起点到LCA路径上的所有点(这些点是$v,w$的公共祖先),那么$v$和$w$在两棵子树内,并且因为公共祖先被删去,无法通过后向边到达子树外面,前向边也无法跨越子树,而横叉边只能从大到小,所以从$v$出发不能离开这颗子树到达$w$。所以如果本来$v$能够到达$w$,就说明这些路径必须经过$v,w$的公共祖先。
在继续之前,我们先约定一些记号:
$V$代表图的点集,$E$代表图的边集。
$a \to b$代表从点$a$直接经过一条边到达点$b$,
$a \leadsto b$代表从点$a$经过某条路径到达点$b$,
$a \dot \to b$代表从点$a$经过DFS树上的树边到达点$b$($a$是$b$在DFS树上的祖先),
$a \overset{+}{\to} b$代表$a \dot \to b$且$a \neq b$。
定义 半支配点(semi-dominator):
对于$w \neq r$,它的半支配点定义为$sdom(w)=\min\{ v | \exists (v_0,v_1,\cdots,v_{k-1},v_k), v_0 = v, v_k = w, \forall 1 \leq i \leq k-1, v_i>w \}$
对于这个定义的理解其实就是从$v$出发,绕过$w$之前的所有点到达$w$。(只能以它之后的点作为落脚点)
注意这只是个辅助定义,并不是真正的支配点。甚至在只保留$w$和$w$以前的点时它都不一定是支配点。例子:$V = \{1,2,3,4\}, E = \{(1,2),(2,3),(3,4),(1,3),(2,4)\}, r = 1, sdom(4) = 2$,但是$2$不支配$4$。不过它代表了有潜力成为支配点的点,在后面我们可以看到,所有的$idom$都来自自己或者另一个点的$sdom$。
引理2
对于任意$w \neq r$,有$idom(w) \overset{+}{\to} w$。
证明很显然,如果不是这样的话就可以直接通过树边不经过$idom(w)$就到达$w$了,与$idom$定义矛盾。
引理3
对于任意$w \neq r$,有$sdom(w) \overset{+}{\to} w$。
证明:
对于$w$在DFS树上的父亲$fa_w$,$fa_w \to w$这条路径只有两个点,所以满足$sdom$定义中的条件,于是它是$sdom(w)$的一个候选。所以$sdom(w) \leq fa_w$。在这里我们就可以使用路径引理证明$sdom(w)$不可能在另一棵子树,因为如果是那样的话就会经过$sdom(w)$和$w$的一个公共祖先,公共祖先的编号一定小于$w$,所以不可行。于是$sdom(w)$就是$w$的真祖先。
引理4
对于任意$w \neq r$,有$idom(w) \dot \to sdom(w)$。
证明:
如果不是这样的话,按照$sdom$的定义,就会有一条路径是$r \dot \to sdom(w) \leadsto w$不经过$idom(w)$了,与$idom$定义矛盾。
引理5
对于满足$v \dot \to w$的点$v,w$,$v \dot \to idom(w)$或$idom(w) \dot \to idom(v)$。
(不严谨地说就是$idom(w)$到$w$的路径不相交或者被完全包含,其实$idom(w)$这个位置是可能相交的)
证明:
如果不是这样的话,就是$idom(v) \overset{+}{\to} idom(w) \overset{+}{\to} v \overset{+}{\to} w$,那么存在路径$r \dot \to idom(v) \leadsto v \overset{+}{\to}w$不经过$idom(w)$到达了$w$(因为$idom(w)$是$idom(v)$的真后代,一定不支配$v$,所以存在绕过$idom(w)$到达$v$的路径),矛盾。
上面这5条引理都比较简单,不过是非常重要的性质。接下来我们要证明几个定理,它们揭示了$idom$与$sdom$的关系。证明可能会比上面的复杂一点。
定理2
对于任意$w \neq r$,如果所有满足$sdom(w) \overset{+}{\to} u \dot \to w$的$u$也满足$sdom(u) \geq sdom(w)$,那么$idom(w) = sdom(w)$。
$$ sdom(w) \dot \to sdom(u) \overset{+}{\to} u \dot \to w $$
证明:
由上面的引理4知道$idom(w) \dot \to sdom(w)$,所以只要证明$sdom(w)$支配$w$就可以保证是最近支配点了。对任意$r$到$w$的路径,取上面最后一个编号小于$sdom(w)$的$x$(如果$sdom$就是$r$的话显然定理成立),它必然有个后继$y$满足$sdom(w) \dot \to y \dot \to w$(否则$x$会变成$sdom(w)$),我们取最小的那个$y$。同时,如果$y$不是$sdom(w)$,根据条件,$sdom(y) \geq sdom(w)$,所以$x$不可能是$sdom(y)$,这就意味着$x$到$y$的路径上一定有一个$v$满足$x \overset{+}{\to} v \overset{+}{\to} y$,因为$x$是小于$sdom(w)$的最后一个,所以$v$也满足$sdom(w) \dot \to v \dot \to w$,但是我们取的$y$已经是最小的一个了,矛盾。于是$y$只能是$sdom(w)$,那么我们就证明了对于任意路径都要经过$sdom(w)$,所以$sdom(w)$就是$idom(w)$。
定理3
对于任意$w \neq r$,令$u$为所有满足$sdom(w) \overset{+}{\to} u \dot \to w$的$u$中$sdom(u)$最小的一个,那么$sdom(u) \leq sdom(w) \Rightarrow idom(w) = idom(u)$。
$$ sdom(u) \dot \to sdom(w) \overset{+}{\to} u \dot \to w $$
证明:
由引理5,有$idom(w) \dot \to idom(u)$或$u \dot \to idom(w)$,由引理4排除后面这种。所以只要证明$idom(u)$支配$w$即可。类似定理2的证明,我们取任意$r$到$w$路径上最后一个小于$idom(u)$的$x$(如果$idom(u)$是$r$的话显然定理成立),路径上必然有个后继$y$满足$idom(u) \dot \to y \dot \to w$(否则$x$会变成$sdom(w)$),我们取最小的一个$y$。类似上面的证明,我们知道$x$到$y$的路径上不能有点$v$满足$idom(u) \dot \to v \overset{+}{\to} y$,于是$x$成为$sdom(y)$的候选,所以$sdom(y) \leq x$。那么根据条件我们也知道了$y$不能是$sdom(w)$的真后代,于是$y$满足$idom(u) \dot \to y \dot \to sdom(w)$。但是我们注意到因为$sdom(y) \leq x$,存在一条路径$r \dot \to sdom(y) \leadsto y \dot \to u$,如果$y$不是$idom(u)$的话这就是一条绕过$idom(u)$的到$u$的路径,矛盾,所以$y$必定是$idom(u)$。所以任意到$w$的路径都经过$idom(u)$,所以$idom(w)=idom(u)$ 。
幸苦地完成了上面两个定理的证明,我们就能够通过$sdom$求出$idom$了:
推论1
对于$w \neq r$,令$u$为所有满足$sdom(w) \overset{+}{\to} u \dot \to w$的$u$中$sdom(u)$最小的一个,有
$$ idom(w) = \left \{ \begin{aligned}& sdom(w)&(sdom(u)=sdom(w))&\\ &idom(u)&(sdom(u)<sdom(w))&\end{aligned} \right .$$
通过定理2和定理3可以直接得到。这里一定有$sdom(u) \leq sdom(w)$,因为$w$也是$u$的候选。
接下来我们的问题是,直接通过定义计算$sdom$很低效,我们需要更加高效的方法,所以我们证明下面这个定理:
定理4
对于任意$w \neq r$,$sdom(w) = min(\{v | (v, w) \in E , v < w \} \cup \{sdom(u) | u > w , \exists (v, w) \in E , u \dot \to v\} )$
证明:
令等号右侧为$x$,显然右侧的点集中都存在路径绕过$w$之前的点,所以$sdom(w) \leq x$。然后我们考虑$sdom(w)$到$w$的绕过$w$之前的点的路径,如果只有一条边,那么必定满足$(sdom(w),w) \in E$且$sdom(w)<w$,所以此时$x \leq sdom(w)$;如果多于一条边,令路径上$w$的上一个点为$last$,我们取路径上除两端外满足$p \dot \to last$的最小的$p$(一定能取得这样的$p$,因为$last$是$p$的候选)。因为这个$p$是最小的,所以$sdom(w)$到$p$的路径必定绕过了$p$之前的所有点,于是$sdom(w)$是$sdom(p)$的候选,所以$sdom(p) \leq sdom(w)$。同时,$sdom(p)$还满足右侧的条件($p$在绕过$w$之前的点的路径上,于是$p>w$,并且$p\dot \to last$,同时$last$直接连到了$w$),所以$sdom(p)$是$x$的候选,$x \leq sdom(p)$。所以$x \leq sdom(p) \leq sdom(w)$,$x \leq sdom(w)$。综上,$sdom(w) \leq x$且$x \leq sdom(w)$,所以$x=sdom(w)$。
好啦,最困难的步骤已经完成了,我们得到了$sdom$的一个替代定义,而且这个定义里面的形式要简单得多。这种基本的树上操作我们是非常熟悉的,所以没有什么好担心的了。接下来就可以给出我们需要的算法了。
3、Lengauer-Tarjan算法
算法流程:
1、初始化、跑一遍DFS得到DFS树和标号
2、按标号从大到小求出$sdom$(利用定理4)
3、通过推论1求出所有能确定的$idom$,剩下的点记录下和哪个点的$idom$是相同的
4、按照标号从小到大再跑一次,得到所有点的$idom$
很简单对不对~有了理论基础后算法就很显然了。
具体实现:
大致要维护的东西:
$vertex(x)$ 标号为$x$的点$u$
$pred(u)$ 有边直接连到$u$的点集
$parent(u)$ $u$在DFS树上的父亲$fa_u$
$bucket(u)$ $sdom$为点$u$的点集
以及$idom$和$sdom$数组
第1步没什么特别的,规规矩矩地DFS一次即可,同时初始化$sdom$为自己(这是为了实现方便)。
第2、3步可以一起做。通过一个辅助数据结构维护一个森林,支持加入一条边($link(u,v)$)和查询点到根路径上的点的$sdom$的最小值对应的点($eval(u)$)。那么我们求每个点的$sdom$只需要对它的所有直接前驱$eval$一次,求得前驱中的$sdom$最小值即可。因为定理4中的第一类点编号比它小,它们还没有处理过,所以自己就是根,$eval$就能取得它们的值;对于第二类点,$eval$查询的就是满足$u \dot \to v$的$u$的$sdom(u)$的最小值。所以这么做和定理4是一致的。
然后把该点加入它的$sdom$的$bucket$里,连上它与父亲的边。现在它父亲到它的这棵子树中已经处理完了,所以可以对父亲的$bucket$里的每个点求一次$sdom$并且清空$bucket$。对于$bucket$里的每个点$v$,求出$eval(v)$,此时$parent(w) \overset{+}{\to} eval(v) \dot \to v$,于是直接按照推论1,如果$sdom(eval(v))=sdom(v)$,则$idom(v)=sdom(v)=parent(w)$;否则可以记下$idom(v)=idom(eval(v))$,实现时我们可以写成$idom(v)=eval(v)$,留到第4步处理。
最后从小到大扫一遍完成第4步,对于每个$u$,如果$idom(u)=sdom(u)$的话,就已经是第3步求出的正确的$idom$了,否则就证明这是第3步留下的待处理点,令$idom(u)=idom(idom(u))$即可。
对于这个辅助数据结构,我们可以选择并查集。不过因为我们需要查询到根路径上的信息,所以不方便写按秩合并,但是我们仍然可以路径压缩,压缩时保留路径上的最值就可以了,所以并查集操作的复杂度是$O(\log n)$。这样做的话,最终的复杂度是$O(n \log n)$。(各种常见方法优化的并查集只要没有按秩合并就是做不到$\alpha$的复杂度的,最下面我会提到如何卡路径压缩)
原论文还提到了一个比较奥妙的实现方法,能够把这个并查集优化到$\alpha$的复杂度,不过看上去比较迷,我觉得我会写错,所以就先放着了,如果有兴趣的话可以找原论文A Fast Algorithm for Finding Dominators in a Flowgraph,里面的参考文献14是Tarjan的另一篇东西Applications of Path Compression on Balanced Trees,原论文说用的是这里面的方法…等什么时候无聊想要真正地学习并查集的各种东西的时候再看吧…(我又挖了个大坑)
代码实现
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
using namespace std;
inline int read()
{
int s = ; char c; while((c=getchar())<'0'||c>'9');
do{s=s*+c-'0';}while((c=getchar())>='0'&&c<='9');
return s;
}
const int N = ;
struct eg{ int dt,nx; }e[N];
int n,m,tim,tot;
int h[N],iw[N],li[N],fa[N],sdom[N],idom[N];
int fo[N],vo[N];
vector<int> pre[N],bkt[N];
int findf(int p)
{
if(fo[p]==p) return p;
int r = findf(fo[p]);
if(sdom[vo[fo[p]]]<sdom[vo[p]]) vo[p] = vo[fo[p]];
return fo[p] = r;
}
inline int eval(int p)
{
findf(p);
return vo[p];
}
void dfs(int p)
{
li[iw[p]=++tim] = p, sdom[p] = iw[p];
for(int pt=h[p];pt;pt=e[pt].nx) if(!iw[e[pt].dt])
dfs(e[pt].dt), fa[e[pt].dt] = p;
}
void work()
{
int i,p;
dfs();
for(i=tim;i>=;i--)
{
p = li[i];
for(int k : pre[p]) if(iw[k]) sdom[p] = min(sdom[p],sdom[eval(k)]);
bkt[li[sdom[p]]].push_back(p);
int fp = fa[p]; fo[p] = fa[p];
for(int v : bkt[fp])
{
int u = eval(v);
idom[v] = sdom[u]==sdom[v]?fp:u;
}
bkt[fp].clear();
}
for(i=;i<=tim;i++) p = li[i], idom[p] = idom[p]==li[sdom[p]]?idom[p]:idom[idom[p]];
for(i=;i<=tim;i++) p = li[i], sdom[p] = li[sdom[p]];
}
inline void link(int a,int b)
{
e[++tot].dt = b, e[tot].nx = h[a], h[a] = tot;
pre[b].push_back(a);
}
int main()
{
#ifndef ONLINE_JUDGE
freopen("in.txt","r",stdin);
#endif
int i;
n = read(), m = read();
tim = tot = ;
for(i=;i<=n;i++) h[i] = iw[i] = , fo[i] = vo[i] = i, pre[i].clear(), bkt[i].clear();
for(i=;i<=m;i++){ int a = read(); link(a,read()); }
work();
return ;
}
我的变量名都很迷…不要在意…(它们可是经过了长时间的结合中文+英文+象形+脑洞的演变得出的结果)
稍微需要注意一下的就是实现时点的真实编号和DFS序中的编号的区别,DFS序的编号是用来比较的那个。以及尽量要保持一致性(要么都用真实编号,要么都用DFS序编号),否则很容易写错…我的这段代码里$idom$用的是真实编号,$sdom$用的是DFS序编号,最后再跑一次把$sdom$转成真实编号的。
4、欢快的彩蛋 卡并查集!
是不是听到周围有人说:“我的并查集只写了路径压缩,它是单次操作$\alpha$的”。这时你要坚定你的信念,你要相信这是$O(\log n)$的。如果他告诉你这个卡不了的话…你或许会觉得确实很难卡…我也觉得很难卡…但是Tarjan总知道怎么卡。
现在确认一下纯路径压缩并查集的实现方法:每次基本操作$find(v)$后都把$v$到根路径上的所有点直接接在根的下面,每次合并操作对需要合并的两个点执行$find$找到它们的根。
看起来挺优的。(其实真的挺优的,只是没有$\alpha$那么优)
Tarjan的卡法基于一种特殊定义的二项树(和一般的二项树的定义不同)。
定义这种特殊的二项树$T_k$为一类多叉树,其中$T_1,T_2,\cdots,T_j$都是一个单独的点,对于$T_k, k>j$,$T_k$就是$T_{k-1}$再接上一个$T_{k-j}$作为它的儿子。
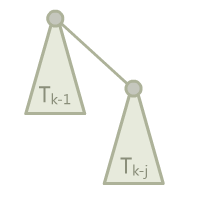
就像这样。这种定义有一个有趣的特性,如果我们把它继续展开,可以得到各种有趣的结果。比如我们把上面图中的$T_{k-j}$继续展开,就会变成$T_{k-j-1}$接着$T_{k-2j}$,以此类推可以展开出一串。而如果对$T_{k-1}$继续展开,父节点就会变成$T_{k-2}$,子节点多出一个$T_{k-j-1}$,以此类推可以展开成一层树。下面的图展示了展开$T_k$的不同方式。
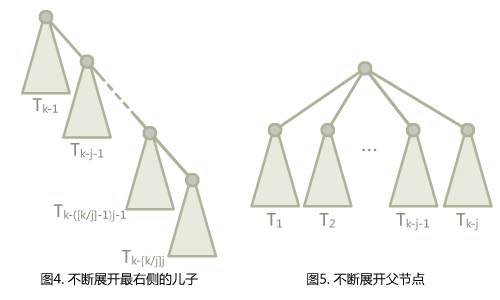
让我们好好考虑一下这意味着什么。从图4到图5…除了这些树的编号没有对应上以外,会不会有一种感觉,图5像是图4路径压缩后的结果。
图4的展开方式中编号的间隔都是$j$,图5的展开方式中间隔都是$1$…那么如果我们用图5的方式展开出$j$棵子树,再按图4展开会怎么样呢?(假设$j$整除$k$)
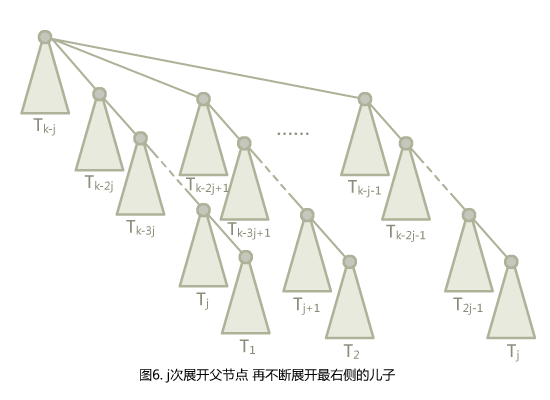
变成了这个样子,就确实和路径压缩扯上关系了。如果在最顶上再加一个点,然后$j$次访问底层的$T_1,T_2,\cdots,T_j$,就可以把树压成图5的样子了,不过会多一个单点的儿子出来,因为图6中其实有两个$T_j$(因为图4展开到最后一层没有了$-1$,所以会和上一层出现一次重复)。这么一来,我们又可以做一次这一系列操作了,非常神奇!(原论文里把这个叫做self-reproduction)至于$T_k$的实际点数,通过归纳法可以得到点数不超过$(j+1)^{\frac{k}{j}-1}$。(我们只对能被$j$整除的$k$进行计算,每次$j$次展开父节点进行归纳)
有了这个我们就有信心卡纯路径压缩并查集了。令$m$代表询问操作数,$n$代表合并操作数,不妨设$m \geq n$,我们取$j=\left \lfloor \frac{m}{n} \right \rfloor, i=\left \lfloor \log_{j+1}\frac{n}{2} \right \rfloor +1, k = ij$。那么$T_k$的大小不超过$(j+1)^{i-1}$即$\frac{n}{2}$。接下来我们做$\frac{n}{2}$组操作,每组在最顶上加入一个点,然后对底层的$j$个节点逐一查询,每次查询的路径长度都是$i+1$。同时总共的查询次数还是不超过$m$。于是总共的复杂度是$\frac{n}{2}j(i+1)=\Omega(m \log_{1+m/n} n)$。
Boom~爆炸了,所以它确实是$\log$级的。
彩蛋到这里就结束啦…如果想知道更多并查集优化方法怎么卡,可以去看这一部分参考的原论文Worst-Case Analysis of Set Union Algorithms,里面还附带了一个表,有写各种并查集实现不带按秩合并和带按秩合并的复杂度,嗯,卡并查集还是挺有趣的(只是一般人想不到呀…Tarjan太强辣)…
(题外话:这次我画了好多图,感觉自己好良心呀w 其实都是对着论文上的例子画的)
康复计划#4 快速构造支配树的Lengauer-Tarjan算法的更多相关文章
- HDU.4694.Important Sisters(支配树)
HDU \(Description\) 给定一张简单有向图,起点为\(n\).对每个点求其支配点的编号和. \(n\leq 50000\). \(Solution\) 支配树. 还是有点小懵逼. 不管 ...
- 带精英策略的快速非支配排序遗传算法 NSGA-II 算法
NSGAII(带精英策略的非支配排序的遗传算法),是基于遗传算法的多目标优化算法,是基于pareto最优解讨论的多目标优化,下面介绍pareto(帕累托)最优解的相关概念. Paerot支配关系 Pa ...
- WC2017游记 & 能力残废康复计划
懒癌晚期的蒟蒻一年多没有更Blog了… 这次冬眠营去绍一省好好地游玩了一番,体验了一段时间的豪华自助餐,成功吃胖… 第一课堂的东西基本还是没吸收…听着觉得有点道理,结果过几分钟就忘了…可能最大的收获就 ...
- 2018.06.27 NOIP模拟 节目(支配树+可持久化线段树)
题目背景 SOURCE:NOIP2015-GDZSJNZX(难) 题目描述 学校一年一度的学生艺术节开始啦!在这次的艺术节上总共有 N 个节目,并且总共也有 N 个舞台供大家表演.其中第 i 个节目的 ...
- [luogu5180]支配树
对于有向图$G$和起点$s$,有以下定义和性质-- 为了方便,不妨假设$s$能到达$G$中所有点,并任意建立一棵以$s$为根的dfs树,以下节点比较默认均按照两点在这棵dfs树上的dfs序 支配点:$ ...
- [HDU]4694 Important Sisters(支配树)
支配树模板 #include<cstdio> #include<cstring> #include<algorithm> using namespace std; ...
- BZOJ_3207_花神的嘲讽计划Ⅰ_哈希+主席树
BZOJ_3207_花神的嘲讽计划Ⅰ_哈希+主席树 Description 背景 花神是神,一大癖好就是嘲讽大J,举例如下: “哎你傻不傻的![hqz:大笨J]” “这道题又被J屎过了!!” “J这程 ...
- 堆应用---构造Huffman树(C++实现)
堆: 堆是STL中priority_queue的最高效的实现方式(关于priority_queue的用法:http://www.cnblogs.com/flyoung2008/articles/213 ...
- luogu2597-[ZJOI2012]灾难 && DAG支配树
Description P2597 [ZJOI2012]灾难 - 洛谷 | 计算机科学教育新生态 Solution 根据题意建图, 新建一个 \(S\) 点, 连向每个没有入边的点. 定义每个点 \( ...
随机推荐
- oracle系列--级联删除和级联更新
必须声明:此博客转载于Oracle外键级联删除和级联更新http://www.2cto.com/database/201507/417496.html 鉴于此前收藏的精彩博客无料被删除了,很是痛心,所 ...
- PHP批量上传一次点击选中多个
首先前端部分需要设置好控件,这里使用HTML5 中 input 的新增属性 multiple 可以很好的解决了以往上传多个需要点击多次"上传按钮"的麻烦: <form act ...
- 让win7安装时出现版本选项
win7有几种版本,win7旗舰版包含各大版本,修改一下ISO,让安装时出现版本选项窗口: 1.准备好一个官方win7旗舰版安装包IOS光盘镜像. 2.用UltraISO打开光盘镜像并删除source ...
- ipyparallel WordCount实现
ipyparallel 之中,可以利用多个engine同时运行一个任务来加快处理的速度.在ipyparallel之中,集群被抽象为view,包括direct_view和balanced ...
- 纯css三角形
三角形原理: 盒子c内容width为0,height为0,盒子给一定宽度的border,分别为四边的border设置不同的颜色,则可以得到不同样式的三角形举个简单的栗子:CSS代码 .box1{ wi ...
- XML 字符串解析
微信红包发送完成后返回xml字符串,解析过程如下: 1.调用解析: public ActionResult GetEntityFromXml() { string str = @"<x ...
- cgLib生成动态代理
package com.stono.cglib; import java.lang.reflect.Method; import net.sf.cglib.proxy.Enhancer; import ...
- Canvas get/putImageData
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- linux下安装TensorFlow(centos)
一.python安装 centos自带python2.7.5,这一步可以省略掉. 二.python-pip pip--python index package,累世linux的yum,安装管理pyth ...
- MongoDB基础之七 用户管理
MongoDB的用户管理 注意:A)在mongodb中,有一个admin数据库, 牵涉到服务器配置层面的操作,需要先切换到admin数据.即 use admin , -->相当于进入超级用户管理 ...