【NLP_Stanford课堂】文本分类2
一、实验评估参数

实验数据本身可以分为是否属于某一个类(即correct和not correct),表示本身是否属于某一类别上,这是客观事实;又可以按照我们系统的输出是否属于某一个类(即selected和not selected),表示是否分到某一类别,这是实验输出。
以垃圾邮件为例:
tp:表示系统认为它是垃圾邮件,而确实它是垃圾邮件,所以为true positive
fn:表示系统不认为它是垃圾邮件,但它其实是垃圾邮件,所以为false negative
fp:表示系统认为是,其实不是,所以为false positive
tn:表示系统认为不是,确实也不是,所以是true negative
对于检测垃圾邮件,只用检测正确率,正确的部分则为tp和tn,所以正确率Acc=(tp+tn)/(tp+fp+fn+tn)
但是如果换一个语境:现在我们要在一篇文档中检测出现的鞋的牌子
那么假设文档中有100,000个词,其中10个是鞋的牌子,99,990个是其他词,如果我们的系统检测出来的鞋的牌子是0个,100,000个词是其他词,那么正确率反而是Acc=99,990/100,000=99.99%,但是显然是不准确的,系统根本没有做任何事,甚至我们用一行代码:for each word: return false。就可以实现,所以在这种情况下,正确率是无法合理评估的,我们更关注的是tp的部分,因此需要用准确率和召回率来评估。
Precision准确率(查准率):selected的部分中正确的比例,tp/(tp+fp)
Recall召回率(查全率):正确的部分中selected的比例,tp/(tp+fn)
两者是相斥的,相加为1,所以召回率越高,准确率反而越低,需要权衡两者,看是查准重要还是查全重要?
the F measure:综合考虑准确率和召回率,为加权调和平均数:

α值取决于作者本身对于应用的评估是查准重要还是查全重要。α=1/(β^2+1)
一般使用F1 measure, 即β=1(即,α=1/2),从而F=2PR/(P+R)
二、实验评估通用数据集
Reuters-21578 Data Set:


混淆矩阵:
横纵坐标为类别,对于每一对<c1,c2>, 其值表示属于c1的文档被错误分到c2的数目,如下:
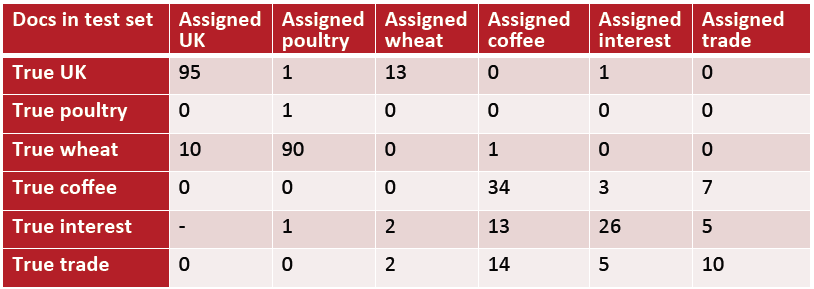
横坐标表头“True XX”表示真实的类别,纵坐标表头“Assigned XX”表示分类器分配的类别。
对角线表示正确分配类别的文档数目。
使用混淆矩阵可以计算各种评估参数:

如果有多个类别,如何结合多项实验参数得到一个参数用以评估:
方法1:Macroaveraging:为每一个类别计算一个值,然后取平均值
方法2:Microaveraging:收集每个类别中的决定,然后计算一个列联表,然后评估
实例:

数据集分为:

在开发测试集中计算各项评估参数:P/R/F1或Accuracy
然后按照评估参数修改模型,继续在训练集中训练模型。
而测试集要求数据跟前两个数据集完全不同,即unseen不可见,这是为了:
- 避免过度拟合
- 对性能的估计更保守
交叉验证:

从训练集中切割出部分开发测试集,然后我们将从每次分割中共享开发测试集的评估结果,然后计算总的开发集性能。从而避免开发测试集过小或者不具有代表性的问题。最后用不可见的测试集验证模型性能。
三、文本分类中的实际问题
1. 没有训练集怎么办?
使用手写规则:非常耗时耗力
2. 训练集很小怎么办?
- 使用Naive Bayes算法:即使训练数据很少,也不至于太过度拟合训练数据
- 获得更多的标签数据:一般也是手动
- 使用半监督训练方法:Bootstrapping, EM over unlabeled documents,...
3. 有足够的训练集
可以尝试任何分类器:SVM、逻辑回归、甚至决策树。
决策树是可以解释的,用户也是乐于去建立决策树的
4. 训练集非常庞大
那就可以达到很高的accuracy正确率,但是大部分分类器比如SVM、KNN都非常慢,逻辑回归会好一些,这种时候训练Naive Bayes反而会非常有效。
实验证明:当数据集非常庞大时,不同的分类器的正确率反而很相近
5. Naive Bayes中的一些关键问题
1)预防下溢:
因为多个小数相乘会导致接近于0。
通过转换成log、将乘法转换为加法可以解决这个问题
2)怎么调整性能:
- 按照领域挑选特定的特征和权重
- 对某些词增加它的计数,即出现一次的时候记成两次,比如:标题、每段的第一句、包含标题单词的句子中的单词
【NLP_Stanford课堂】文本分类2的更多相关文章
- 【NLP_Stanford课堂】文本分类1
文本分类实例:分辨垃圾邮件.文章作者识别.作者性别识别.电影评论情感识别(积极或消极).文章主题识别及任何可分类的任务. 一.文本分类问题定义: 输入: 一个文本d 一个固定的类别集合C={c1,c2 ...
- Tensorflow二分类处理dense或者sparse(文本分类)的输入数据
这里做了一些小的修改,感谢谷歌rd的帮助,使得能够统一处理dense的数据,或者类似文本分类这样sparse的输入数据.后续会做进一步学习优化,比如如何多线程处理. 具体如何处理sparse 主要是使 ...
- Atitti 文本分类 以及 垃圾邮件 判断原理 以及贝叶斯算法的应用解决方案
Atitti 文本分类 以及 垃圾邮件 判断原理 以及贝叶斯算法的应用解决方案 1.1. 七.什么是贝叶斯过滤器?1 1.2. 八.建立历史资料库2 1.3. 十.联合概率的计算3 1.4. 十一. ...
- 基于weka的文本分类实现
weka介绍 参见 1)百度百科:http://baike.baidu.com/link?url=V9GKiFxiAoFkaUvPULJ7gK_xoEDnSfUNR1woed0YTmo20Wjo0wY ...
- LingPipe-TextClassification(文本分类)
What is Text Classification? Text classification typically involves assigning a document to a catego ...
- 文本分类之特征描述vsm和bow
当我们尝试使用统计机器学习方法解决文本的有关问题时,第一个需要的解决的问题是,如果在计算机中表示出一个文本样本.一种经典而且被广泛运用的文本表示方法,即向量空间模型(VSM),俗称“词袋模型”. 我们 ...
- R语言做文本挖掘 Part4文本分类
Part4文本分类 Part3文本聚类提到过.与聚类分类的简单差异. 那么,我们需要理清训练集的分类,有明白分类的文本:測试集,能够就用训练集来替代.预測集,就是未分类的文本.是分类方法最后的应用实现 ...
- Spark ML下实现的多分类adaboost+naivebayes算法在文本分类上的应用
1. Naive Bayes算法 朴素贝叶斯算法算是生成模型中一个最经典的分类算法之一了,常用的有Bernoulli和Multinomial两种.在文本分类上经常会用到这两种方法.在词袋模型中,对于一 ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
随机推荐
- kafka监控服务搭建
wget https://github.com/Morningstar/kafka-offset-monitor/releases/download/0.4.1/KafkaOffsetMonitor- ...
- java中+=与+的区别
public class QQ { public static void main(String[] args) throws ParseException { byte val1 = 5; doub ...
- gson日期转换问题
转:http://blog.csdn.net/liao_leo/article/details/44593095 今天遇到个很奇怪的问题,gson解析日期字符串,本地执行可以,服务器上执行就报错. 这 ...
- Jmeter断言实例—响应断言
断言有很多种,最最最常用的一种就是响应断言,目前我用的最多是这一种,下面列举一个运用响应断言的实例 对相应的请求添加断言 **Main sample and sub-samples:断言应用于主采样器 ...
- selenium+Python(cookie处理)
cookie 处理本节重点: driver.get_cookies() 获得 cookie 信息 add_cookie(cookie_dict) 向 cookie 添加会话信息 delete_cook ...
- Git学习系列之Git是什么?
前言 现在主流IDE里,都集成git了. https://git-scm.com/docs 史上最浅显易懂的Git教程! 为什么要编写这个教程?因为我在学习Git的过程中,买过书,也在网上Google ...
- Orcale 之 SQL 数据定义
SQL 的数据定义功能主要是针对数据对象进行定义的,这些数据对象主要包括:表,视图以及索引. 注意:由于视图是基于表的虚表,而索引是依附在基表上的,所以视图和索引均不提供修改视图和索引定义的操作.如果 ...
- 九度oj 1032 ZOJ 2009年浙江大学计算机及软件工程研究生机试真题
题目1032:ZOJ 时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:4102 解决:2277 题目描述: 读入一个字符串,字符串中包含ZOJ三个字符,个数不一定相等,按ZOJ的顺序输出,当 ...
- iostat命令——监控系统设备的IO负载情况
iostat命令的安装 #yum install sysstat iostat常见选项 -t 输出数据时打印搜集数据的时间 -m 输出的数据以MB为单位 -d 显示磁盘的统计信息 # iost ...
- CF520B——Two Buttons——————【广搜或找规律】
J - Two Buttons Time Limit:2000MS Memory Limit:262144KB 64bit IO Format:%I64d & %I64u Su ...