Node.js 4493图片批量下载爬虫1.00
这个爬虫依然需要iconv转码,想不到如今非utf8的网页还这么多。另外此网页找下一页的方式比较异常,又再次借助了正则表达式。
代码如下:
//======================================================
// 4493图片批量下载爬虫1.00
// 2017年11月19日
//======================================================
// 内置https模块
var https=require("https");
// 内置http模块
var http=require("http");
// 内置文件处理模块,用于创建目录和图片文件
var fs=require('fs');
// 用于转码。非Utf8的网页如gb2132会有乱码问题,需要iconv将其转码
var iconv = require('iconv-lite');
// cheerio模块,提供了类似jQuery的功能,用于从HTML code中查找图片地址和下一页
var cheerio = require("cheerio");
// 请求参数JSON。http和https都有使用
var options;
// request请求
var req;
// 图片数组,找到的图片地址会放到这里
var pictures=[];
// 存放图片的目录
var folder="";
//--------------------------------------
// 爬取网页,找图片地址,再爬
// pageUrl sample:https://www.4493.com/xingganmote/136346/1.htm
// pageUrl sample:
//--------------------------------------
function crawl(pageUrl){
console.log("Current page="+pageUrl);
// 得到hostname和path
var currUrl=pageUrl.replace("https://","");
var pos=currUrl.indexOf("/");
var hostname=currUrl.slice(0,pos);
var path=currUrl.slice(pos);
//console.log("hostname="+hostname);
//console.log("path="+path);
// 初始化options
options={
hostname:hostname,
port:443,
path:path,// 子路径
method:'GET',
};
req=https.request(options,function(resp){
var html = [];
resp.on("data", function(data) {
html.push(data);
})
resp.on("end", function() {
var buffer = Buffer.concat(html);
var body = iconv.decode(buffer,'gb2312'); // header里面有<meta http-equiv="Content-Type" content="text/html; charset=gb2312">字样都需要iconv帮忙转码
//console.log(body);
var $ = cheerio.load(body);
var picCount=0;
// 找图片放入数组
$(".picsbox p img").each(function(index,element){
var picUrl=$(element).attr("src");
console.log(picUrl);
if(picUrl.indexOf('.jpg')!=-1){
pictures.push(picUrl);
picCount++;
}
})
console.log("找到图片"+picCount+"张.");
var curr=0;
$(".page a.current").each(function(index,element){
var text=$(element).text();
curr=parseInt(text);
//console.log("curr="+curr);
})
var next=0;
$("#nextpage").each(function(index,element){
var text=$(element).attr("href");
var reg=/javascript:gotourl[(]'(\d+).htm'[)]/g;
var res;
while((res = reg.exec(text)) != null){
next=parseInt(res[1]);
//console.log("next="+next);
}
})
var nextPageUrl=null;
if(curr!=next){
var pos=pageUrl.lastIndexOf("/");
nextPageUrl= pageUrl.slice(0,pos+1)+next+".htm";
//console.log("nextPageUrl="+nextPageUrl);
}
// 找下一页
if(nextPageUrl==null){
console.log(pageUrl+"已经是最后一页了.\n");
saveFile(pageUrl,pictures);// 保存
download(pictures);
}else{
console.log("继续下一页");
crawl(nextPageUrl);
}
}).on("error", function() {
saveFile(pageUrl,pictures);// 保存
console.log("crawl函数失败,请进入断点续传模式继续进行");
})
});
// 超时处理
req.setTimeout(7500,function(){
req.abort();
});
// 出错处理
req.on('error',function(err){
console.log('请求发生错误'+err);
saveFile(pageUrl,pictures);// 保存
console.log("crawl函数失败,请进入断点续传模式继续进行");
});
// 请求结束
req.end();
}
//--------------------------------------
// 下载图片
//--------------------------------------
function download(pictures){
var total=0;
total=pictures.length;
console.log("总计有"+total+"张图片将被下载.");
appendToLogfile(folder,"总计有"+total+"张图片将被下载.\n");
for(var i=0;i<pictures.length;i++){
var picUrl=pictures[i];
downloadPic(picUrl,folder);
}
}
//--------------------------------------
// 写log文件
//--------------------------------------
function appendToLogfile(folder,text){
fs.appendFile('./'+folder+'/log.txt', text, function (err) {
if(err){
console.log("不能书写log文件");
console.log(err);
}
});
}
//--------------------------------------
// 取得当前时间
//--------------------------------------
function getNowFormatDate() {
var date = new Date();
var seperator1 = "-";
var seperator2 = "_";
var month = date.getMonth() + 1;
var strDate = date.getDate();
if (month >= 1 && month <= 9) {
month = "0" + month;
}
if (strDate >= 0 && strDate <= 9) {
strDate = "0" + strDate;
}
var currentdate =date.getFullYear() + seperator1 + month + seperator1 + strDate
+ " " + date.getHours() + seperator2 + date.getMinutes()
+ seperator2 + date.getSeconds();
return currentdate;
}
//--------------------------------------
// 下载单张图片
// picUrl sample:http://img.1985t.com/uploads/attaches/2017/11/136398-mrani71.jpg
//--------------------------------------
function downloadPic(picUrl,folder){
console.log("图片:"+picUrl+"下载开始");
// 得到hostname,path和port
var currUrl=picUrl.replace("http://","");
var pos=currUrl.indexOf("/");
var hostname=currUrl.slice(0,pos);
var path=currUrl.slice(pos);
// 有端口加端口,没有端口默认80
var port=80;
//console.log("hostname="+hostname);
//console.log("path="+path);
//console.log("port="+port);
var picName=currUrl.slice(currUrl.lastIndexOf("/"));
// 初始化options
options={
hostname:hostname,
port:port,
path:path,
method:'GET',
};
req=http.request(options,function(resp){
var imgData = "";
resp.setEncoding("binary");
resp.on('data',function(chunk){
imgData+=chunk;
});
resp.on('end',function(){
// 创建文件
var fileName="./"+folder+picName;
fs.writeFile(fileName, imgData, "binary", function(err){
if(err){
console.log("[downloadPic]文件 "+fileName+" 下载失败.");
console.log(err);
appendToLogfile(folder,"文件 "+picUrl+" 下载失败.\n");
}else{
appendToLogfile(folder,"文件 "+picUrl+" 下载成功.\n");
console.log("文件"+fileName+"下载成功");
}
});
});
});
// 超时处理
req.setTimeout(7500,function(){
req.abort();
});
// 出错处理
req.on('error',function(err){
if(err){
console.log('[downloadPic]文件 '+picUrl+" 下载失败,"+'因为'+err);
appendToLogfile(folder,"文件"+picUrl+"下载失败.\n");
}
});
// 请求结束
req.end();
}
//--------------------------------------
// 程序入口
//--------------------------------------
function getInput(){
process.stdin.resume();
process.stdout.write("\033[33m 新建模式输入第一页URL,断点续传模式输入0,请输入: \033[39m");// 草黄色
process.stdin.setEncoding('utf8');
process.stdin.on('data',function(text){
var input=text.trim();
process.stdin.end();// 退出输入状态
if(text.trim()=='0'){
process.stdout.write("\033[36m 进入断点续传模式. \033[39m"); // 蓝绿色
// Read File
fs.readFile('./save.dat','utf8',function(err,data){
if(err){
console.log('读取文件save.dat失败,因为'+err);
}else{
//console.log(data);
var obj=JSON.parse(data);
pictures=obj.pictures;
console.log('提取图片'+pictures.length+'张');
folder=obj.folder;
// 创建目录
fs.mkdir('./'+folder,function(err){
if(err){
console.log("目录"+folder+"已经存在");
}
});
crawl(obj.url);
}
});
// Resume crawl
}else{
process.stdout.write("\033[35m 进入新建模式. \033[039m"); //紫色
folder='pictures('+getNowFormatDate()+")";
// 创建目录
fs.mkdir('./'+folder,function(err){
if(err){
console.log("目录"+folder+"已经存在");
}
});
crawl(input);
}
});
}
//--------------------------------------
// 将爬行中信息存入数据文件
//--------------------------------------
function saveFile(url,pictures){
var obj=new Object;
obj.url=url;
obj.pictures=pictures;
obj.folder=folder;
var text=JSON.stringify(obj);
fs.writeFile('./save.dat',text,function(err){
if(err){
console.log('写入文件save.dat失败,因为'+err);
}
});
}
// 调用getInput函数,程序开始
getInput();
附个运行时控制台贴图:
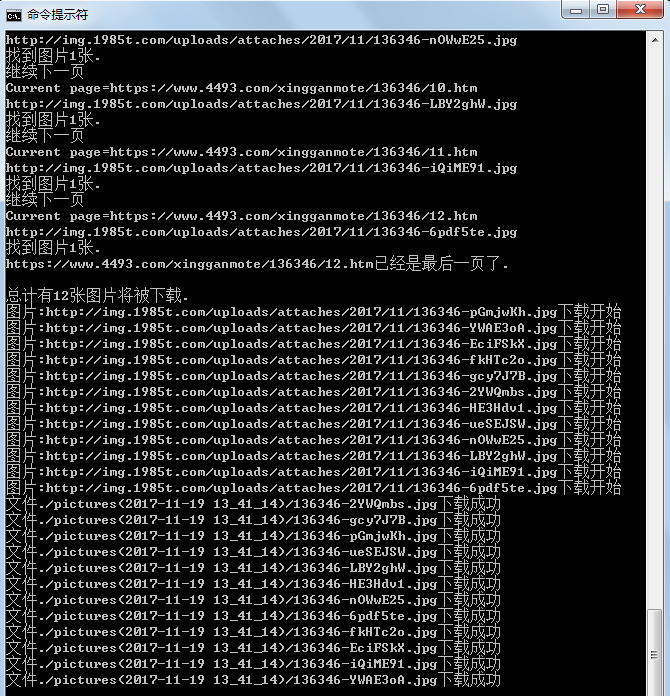
Node.js 4493图片批量下载爬虫1.00的更多相关文章
- Node.js mzitu图片批量下载爬虫1.00
又攻下一座山头. //====================================================== // mzitu图片批量下载爬虫1.00 // 2017年11月19 ...
- Node.js monly图片批量下载爬虫1.00
此爬虫又用到了iconv转码,代码如下: //====================================================== // mmonly图片批量下载爬虫1.00 ...
- Node.js m03122图片批量下载爬虫1.00
//====================================================== // m03122图片批量下载爬虫1.00 // 2017年11月18日 //==== ...
- Node.js mm131图片批量下载爬虫1.00 iconv协助转码
//====================================================== // mm131图片批量下载爬虫1.00 // 2017年11月15日 //===== ...
- Node.js mimimn图片批量下载爬虫 1.00
这个爬虫在Referer设置上和其它爬虫相比有特殊性.代码: //====================================================== // mimimn图片批 ...
- Node.js nvshens图片批量下载爬虫 1.00
//====================================================== // www.nvshens.com图片批量下载Node.js爬虫1.00 // 此程 ...
- Node.js mm131图片批量下载爬虫1.01 增加断点续传功能
这里的断点续传不是文件下载时的断点续传,而是指在爬行页面时有时会遇到各种网络中断而从中断前的页面及其数据继续爬行的过程,这个过程和断点续传原理上相似故以此命名.我的具体做法是:在下载出现故障或是图片已 ...
- Node.js abaike图片批量下载爬虫1.02
//====================================================== // abaike图片批量下载爬虫1.02 // 用最近的断点续传框架改写原有1.01 ...
- Node.js nvshens图片批量下载爬虫1.01
//====================================================== // nvshens图片批量下载爬虫1.01 // 用最近的断点续传框架改写原有1.0 ...
随机推荐
- hdu 5117 数学公式展开 + dp
题目大意:有n个灯泡,m个按钮,(1 <= n, m <= 50),每个按钮和ki 个灯泡相关, 按下后,转换这些灯泡的状态,问你所有2^m的按下按钮的 组合中亮着的灯泡的数量的三次方的和 ...
- YII2 源码阅读 综述
如何阅读源码呢? 我的方法是,打开xdebug的auto_trace [XDebug] ;xdebug.profiler_append = 0 ;xdebug.profiler_enable = 1 ...
- 子树(LintCode)
子树 有两个不同大小的二进制树: T1 有上百万的节点:T2 有好几百的节点.请设计一种算法,判定 T2 是否为 T1的子树. 样例 下面的例子中 T2 是 T1 的子树: 1 3 / \ / T1 ...
- 线段树+扫描线【bzoj1645】[USACO07OPEN]城市的地平线City Horizon
Description 约翰带着奶牛去都市观光.在落日的余晖里,他们看到了一幢接一幢的摩天高楼的轮廓在地平线 上形成美丽的图案.以地平线为 X 轴,每幢高楼的轮廓是一个位于地平线上的矩形,彼此间可能有 ...
- 洛谷——P1123 取数游戏
P1123 取数游戏 题目描述 一个N×M的由非负整数构成的数字矩阵,你需要在其中取出若干个数字,使得取出的任意两个数字不相邻(若一个数字在另外一个数字相邻8个格子中的一个即认为这两个数字相邻),求取 ...
- 【OpenStack】源码级深入了解删除虚拟机操作
首先看一下虚拟机有多少种状态:(/nova/compute/vmstates.py) ACTIVE = 'active' # VM is running BUILDING = 'building' # ...
- shell 指定行插入
#如果知道行号可以用下面的方法 sed -i '88 r b.file' a.file #在a.txt的第88行插入文件b.txt awk '1;NR==88{system("cat ...
- 发现一个FreeSWITCH bug
在研究FreeSWITCH视频会议的混屏问题时候发现一个bug. 已提交jira. 附上代码,问题很明显,不解释 =========================================== ...
- 【BZOJ 4025】 (CDQ?还是整体二分?+并查集及它的恢复操作)
4025: 二分图 Description 神犇有一个n个节点的图.因为神犇是神犇,所以在T时间内一些边会出现后消失.神犇要求出每一时间段内这个图是否是二分图.这么简单的问题神犇当然会做了,于是他想考 ...
- 【博弈论】【SG函数】【线段树】Petrozavodsk Summer Training Camp 2016 Day 9: AtCoder Japanese Problems Selection, Thursday, September 1, 2016 Problem H. Cups and Beans
一开始有n个杯子,每个杯子里有一些豆子,两个人轮流操作,每次只能将一个豆子移动到其所在杯子之前的某个杯子里,不过可以移动到的范围只有一段区间.问你是否先手必胜. 一个杯子里的豆子全都等价的,因为sg函 ...