stable diffusion论文解读
High-Resolution Image Synthesis with Latent Diffusion Models
论文背景
LDM是Stable Diffusion模型的奠基性论文
于2022年6月在CVPR上发表

传统生成模型具有局限性:
- 扩散模型(DM)通过逐步去噪生成图像,质量优于GAN,但直接在像素空间操作导致高计算开销。
- 随着分辨率提升,扩散模型的优化和推理成本呈指数级增长,限制了实际应用
如DDPM生成的图像分辨率普遍不超过256×256,而LDM生成的图像分辨率可以超过1024×1024.
而LDM通过将扩散过程迁移至潜在空间,解决了传统模型的计算瓶颈,同时保持生成质量与灵活性。
论文框架方法
论文中框架示意图如图所示:
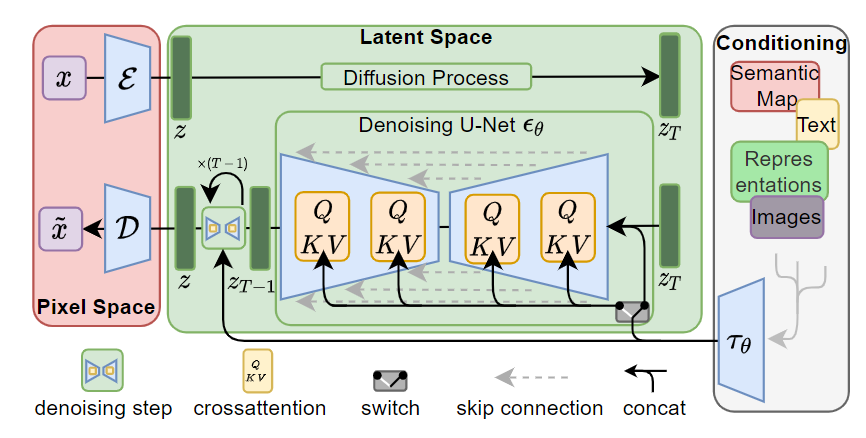
在训练阶段:
- 预训练自动编码器(AE)和条件生成编码器(如clip)
- 输入图片x,经过自动编码器压缩到隐空间ε(x)=z
- 随机采样时间步T,对Z进行加噪到\(Z_{T}\)
- 对右边框里的条件进行条件编码\(\tau_\theta(y)\)和\(Z_{T}\)一起输入UNet网络中
- 进行交叉注意力计算,其中\(Z_{T}\)作为Q向量,\(\tau_\theta(y)\)作为K,V向量计算注意力,这样做是让图像的每个位置根据文本的语义来决定关注哪些部分
- 最后Unet输出两个向量,一个是无条件预测噪声,一个是文本预测噪声。
无条件预测噪声输入是空字符串
- 使用CFG计算最终预测噪声\(\epsilon_{\text{guided}}(z_t, t, \tau_\theta(y)) = \epsilon_\theta(z_t, t,\tau_\theta(y)) + s \cdot (\epsilon_\theta(z_t, t, \tau_\theta(y)) - \epsilon_\theta(z_t, t, \varnothing))\)
- 使用损失函数进行反向传播计算
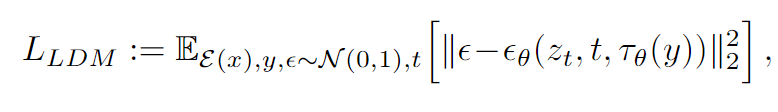
在生成阶段:
- 以随机噪声\(Z_{T}\)作为起点
- 输入文本作为条件,编码后一起进入Unet进行交叉注意力计算
- 输出预测噪声\(\epsilon_{\text{guided}}(z_t, t, \tau_\theta(y))\)
- 使用调度器进行逐步去噪计算(如DDPM,DDIM)成为\(Z_{T-1}\)
- 重复以上过程,直到Z
- 通过自动编码器的解码器部分把Z迁移到像素空间,D(z),即生成图像
交叉注意力机制中的维度变换
图像编码后变成 C=4, H'=64, W'=64,展平后作为Q(\(z_t \Rightarrow Q \in \mathbb{R}^{(H'W') \times d}\)),文本通过编码器的编码表示为\(c = [t_1, t_2, ..., t_L] \Rightarrow \text{Embedding} \in \mathbb{R}^{L \times d}\),K和V表示为\(K, V \in \mathbb{R}^{L \times d}\),计算注意力权重\(A = \text{softmax}\left( \frac{Q K^\top}{\sqrt{d}} \right) \in \mathbb{R}^{(H'W') \times L}\),输出为\(\text{Attention}(Q, K, V) = A \cdot V \in \mathbb{R}^{(H'W') \times d}\)
# 潜在空间输入(prepare_latents生成)
latents.shape = (batch_size * num_images_per_prompt, 4, H//8, W//8)
# 文本嵌入处理(encode_prompt输出)
prompt_embeds.shape = (batch_size, max_sequence_length, embedding_dim)
# IP适配器图像嵌入处理
image_embeds[0].shape = (batch_size * num_images_per_prompt, num_images, emb_dim)
# UNet输入/输出维度
latent_model_input.shape = [batch*2, 4, H//8, W//8] # 当启用CFG时
noise_pred.shape = [batch*2, 4, H//8, W//8] # UNet输出噪声预测
假设参数设置
prompt = "一只坐在月球上的猫"
height = 512
width = 512
num_images_per_prompt = 1
guidance_scale = 7.5
batch_size = 1 # 根据prompt长度自动确定
# 关键计算步骤演示
# ---------------------------
# 步骤1:潜在空间(latents)维度计算
latents_shape = (
batch_size * num_images_per_prompt, # 1*1=1
4, # UNet输入通道数
height // 8, # 512/8=64
width // 8 # 512/8=64
)
print(f"潜在空间维度: {latents_shape}") # -> (1, 4, 64, 64)
# 步骤2:文本编码维度(假设使用CLIP模型)
prompt_embeds_shape = (
batch_size,
77, # CLIP最大序列长度
768 # CLIP文本编码维度
)
print(f"文本嵌入维度: {prompt_embeds_shape}") # -> (1, 77, 768)
# 步骤3:CFG处理后的嵌入
if guidance_scale > 1:
prompt_embeds = torch.cat([negative_embeds, positive_embeds])
print(f"CFG嵌入维度: {prompt_embeds.shape}") # -> (2, 77, 768)
# 步骤4:UNet输入维度(假设启用CFG)
latent_model_input = torch.cat([latents] * 2)
print(f"UNet输入维度: {latent_model_input.shape}") # -> (2, 4, 64, 64)
# 步骤5:噪声预测输出
noise_pred = unet(latent_model_input, ...)[0]
print(f"噪声预测维度: {noise_pred.shape}") # -> (2, 4, 64, 64)
# 步骤6:CFG调整后的噪声
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
print(f"调整后噪声维度: {noise_pred.shape}") # -> (1, 4, 64, 64)
# 最终输出图像
image = vae.decode(latents / vae.config.scaling_factor)[0]
print(f"输出图像维度: {image.shape}") # -> (1, 3, 512, 512)
def cross_attention(query, key, value):
# 输入维度说明
# query: 来自潜在噪声 [batch=2, 4*64*64=16384] → 投影为 [2, 16384, 768]
# key/value: 来自文本嵌入 [2, 77, 768]
# 步骤1:计算注意力分数
attention_scores = torch.matmul(
query, # [2, 16384, 768]
key.transpose(-1, -2) # [2, 768, 77] → 转置后维度
) # 矩阵乘法结果 → [2, 16384, 77]
# 步骤2:计算注意力权重
attention_probs = torch.softmax(
attention_scores, # [2, 16384, 77]
dim=-1 # 对最后一个维度(文本标记维度)做归一化
) # 保持维度 [2, 16384, 77]
# 步骤3:应用注意力到value
output = torch.matmul(
attention_probs, # [2, 16384, 77]
value # [2, 77, 768]
) # 结果维度 → [2, 16384, 768]
# 步骤4:重塑为潜在空间维度
output = output.view(2, 4, 64, 64, 768) # 恢复空间结构
output = output.permute(0, 4, 1, 2, 3) # [2, 768, 4, 64, 64]
output = self.to_out(output) # 通过最后的线性层投影回4通道
return output # [2, 4, 64, 64]
数据集以及指标介绍
数据集介绍

CelebA-HQ 256 × 256数据集,是一个大规模的人脸属性数据集,拥有超过200K张名人图片,每张图片都有40个属性注释(如身份,年龄、表情、发型等)。

从Flickr网站爬取的人脸数据集集合,涵盖多样化的年龄、种族、表情、配饰(如眼镜、帽子)等属性

这两个数据集都是LSUN(大规模场景理解)数据集的子集,两个数据集分别表示教堂和卧室场景的数据,包含教堂建筑的不同视角、结构和环境条件,覆盖多样化的卧室场景,包括不同装修风格、家具布局和光照条件
指标介绍
IS分数介绍
Inception Score 的定义为:
\(IS(G) = \exp \left( \mathbb{E}_{x \sim p_g} \left[ D_{KL} ( p(y|x) \| p(y) ) \right] \right)\)
x~pg:生成图像样本来自生成模型的分布 。
p(y|x):通过预训练分类器(如Inception v3)对生成图像的类别预测概率分布。
p(y):预测类别的边缘分布。类别可以是猫,狗,猪等诸如此类的动物。
其中如果生成图像明确、质量高,则p(y|x)的熵就会比较低,如果生成图像比较多样,则p(y)的熵就会较高,体现在公式中则IS分数会较高。
FID分数介绍
主要是计算生成图像分布和真实图像分布在特征空间中的距离
公式\(\text{FID} = \| \mu_r - \mu_g \|_2^2 + \text{Tr}(\Sigma_r + \Sigma_g - 2 (\Sigma_r \Sigma_g)^{\frac{1}{2}})\)
\(\mu_r,\Sigma_r\):真实图像分布的均值和协方差矩阵。
\(\mu_g,\Sigma_g\):生成图像分布的均值和协方差矩阵。
\(\| \mu_r - \mu_g \|_2^2\):欧几里得距离的平方。
\(\text{Tr}\):矩阵的迹。
\((\Sigma_r \Sigma_g)^{\frac{1}{2}}\):协方差矩阵的乘积的平方根。
两个分布的均值和协方差越低,FID越低,生成图像质量越接近生成的图像
prec和recall
这里的指标和一般理解的不一样。
会先用Inception网络分别提取真实图像和生成图像的特征点
用集合的角度解释:
Precision ≈ 生成图像中,有多少落在真实图像分布的“支持区域”里(真实性)
Recall ≈ 真实图像中,有多少被生成图像的“支持区域”覆盖(多样性)
实验分析
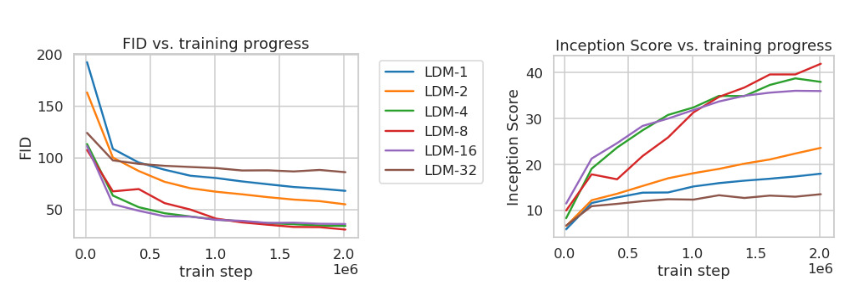
研究不同下采样因子f对生成图像质量和训练效率的影响
下采样因子:指的是自动编码器中的参数。
可以看到下采样因子为4或8时表现最好。因为如果因子过小,会导致维度高,计算缓慢,因子过大,会损失很多信息,导致最后生成图像生成质量较差
后续的实验将基于此展开
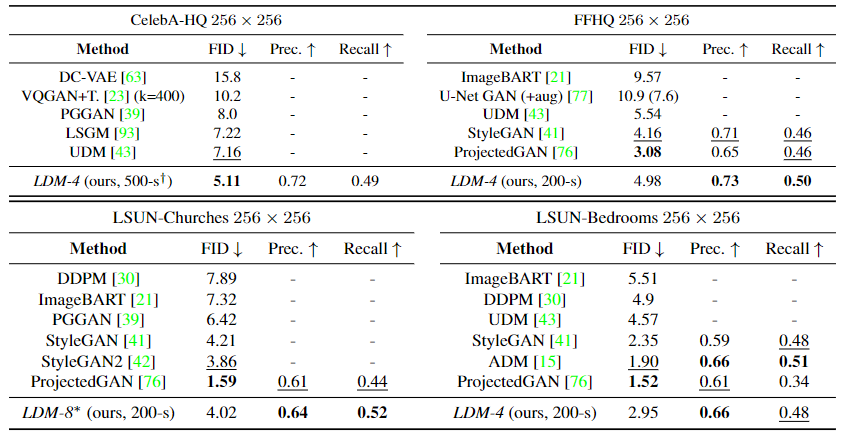
在这个实验里可以看到,LDM在CelebA-HQ中取得了最优的FID分数,在其他数据集上的表现也是中规中矩。
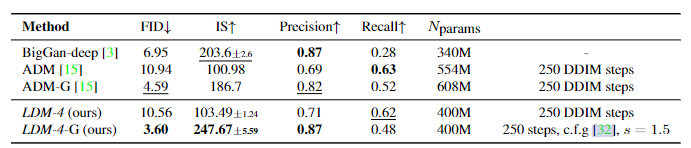
这个实验里展示了LDM在类别生成任务中的表现,可以看到使用cfg引导的LDM展现出了非常优秀的性能,在FID和IS分数上表现优异,虽然recall略低,但是使用的参数量也大幅减少了。
stable diffusion论文解读的更多相关文章
- 使用 LoRA 进行 Stable Diffusion 的高效参数微调
LoRA: Low-Rank Adaptation of Large Language Models 是微软研究员引入的一项新技术,主要用于处理大模型微调的问题.目前超过数十亿以上参数的具有强能力的大 ...
- 论文解读(KP-GNN)《How Powerful are K-hop Message Passing Graph Neural Networks》
论文信息 论文标题:How Powerful are K-hop Message Passing Graph Neural Networks论文作者:Jiarui Feng, Yixin Chen, ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- Gaussian field consensus论文解读及MATLAB实现
Gaussian field consensus论文解读及MATLAB实现 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.Introduction ...
- zz扔掉anchor!真正的CenterNet——Objects as Points论文解读
首发于深度学习那些事 已关注写文章 扔掉anchor!真正的CenterNet——Objects as Points论文解读 OLDPAN 不明觉厉的人工智障程序员 关注他 JustDoIT 等 ...
- NIPS2018最佳论文解读:Neural Ordinary Differential Equations
NIPS2018最佳论文解读:Neural Ordinary Differential Equations 雷锋网2019-01-10 23:32 雷锋网 AI 科技评论按,不久前,NeurI ...
- [论文解读] 阿里DIEN整体代码结构
[论文解读] 阿里DIEN整体代码结构 目录 [论文解读] 阿里DIEN整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x04 模型基类 4.1 基本逻辑 ...
- 【抓取】6-DOF GraspNet 论文解读
[抓取]6-DOF GraspNet 论文解读 [注]:本文地址:[抓取]6-DOF GraspNet 论文解读 若转载请于明显处标明出处. 前言 这篇关于生成抓取姿态的论文出自英伟达.我在读完该篇论 ...
随机推荐
- 阿里巴巴开源ETL(数据的抽取、转换、加载)工具-----DataX
一个比Sqoop好用的数据传输工具 下载maven的时候,加一个 -P让下载的压缩包到指定目录 而要让档案自动储存到指令的目录下,则需要借用-P这个参数wget -p 目录 网址wget -P /ro ...
- 低代码 + DeepSeek:赋能开发者,效率飞跃新高度
活字格接入 DeepSeek 前段时间,小编陆续发布了关于葡萄城旗下产品 Wyn 和 SpreadJS 成功接入DeepSeek的技术文章,分享了两款产品与 DeepSeek 集成后的功能优势和应用场 ...
- 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
昨天DD以为阿里开源的QwQ-32B会刷爆全网,毕竟对标的是上一个热门项目deepseek-r1.但是,万万没想到,获得更多关注的居然是:Manus. 简单的从网上介绍信息了解了一下,感觉跟OpenA ...
- xss学习及xss-lab解题记录
什么是XSS(跨站脚本攻击) SQL注入是服务端将用户输入的数据当成SQL代码去执行 XSS可以理解为服务端把用户输入的数据当成前端代码去执行 前端代码->主要是js代码 两个关键条件: 第一个 ...
- AWVS安装使用
AWVS安装使用 1.双击exe文件,然后点击下一步. 2.选择我接受,然后下一步. 3.选择路径(我选择的默认路径)然后下一步. 4.还是下一步. 5.设置邮箱,用户名密码,用户名12345678@ ...
- Loongson Log
就看看能坚持多久吧 22/2/2及以前: 参照想象中的p7内容增添部分版CP0.部分中断/异常机制: 改sram接口:查阅文档func_test.sram相关内容:查阅vivado bram IP核相 ...
- 视频笔记软件JumpVideo技术解析一:Electron案例-调用VLC播放器
大家好,我是TheGodOfKing,是 最强考研学习神器,免费视频笔记应用JumpVideo,可以快速添加截图时间戳,支持所有笔记软件,学习效率MAX!的开发者之一,分享技术的目的是想找到更多志同道 ...
- 【FAQ】HarmonyOS SDK 闭源开放能力 —Push Kit(10)
1.问题描述: 离线推送,锁屏的时候没有弹出消息,只有下拉在通知中心里面显示.请问是否是正常的? 解决方案: 检查一下是否存在图片风控:https://developer.huawei.com/con ...
- linux怎么关闭selinux
关闭方法:1.临时关闭,只需执行"setenforce 0"命令即可.2.永久关闭,需要执行"vi /etc/selinux/config"命令打开config ...
- 继承内存图--java进阶 day01
主方法进栈,有new进堆 堆内存中先存自己类中有的变量 又因为继承了父类,所以父类中的变量也要存入 即使被私有化,依旧可以继承,只是没有权限使用! 创建对象时,会调用构造方法,所以走构造方法,实参传形 ...