transfomer架构探究
一 前置知识
1. Embedding表示语义
想想两一百多年前,第一位西方传教士来到中国清朝,面对完全陌生的汉字体系,他该如何与中国人进行初步的沟通呢?最简单的方法是:根据中间实物对应。比如,他面前有一个苹果,中国人指着苹果说“苹果”,他就把“苹果”这个词和实物苹果,以及英文单词apple对应起来了。这样,他就学会了第一个中文词汇。
对于机器学习中的翻译任务,我们的思路也是一致的。中文"苹果"之所以能翻译为英文"apple",就是因为它们在语义上是相同的,换言之,他们代表的实物语义,在某个空间中是相似的。机器学习的翻译任务就是要找到这样一个latent space,让语义相似的词在这个空间中距离更近。而这个空间中的向量们,就是我们常说的词向量(word embedding)。
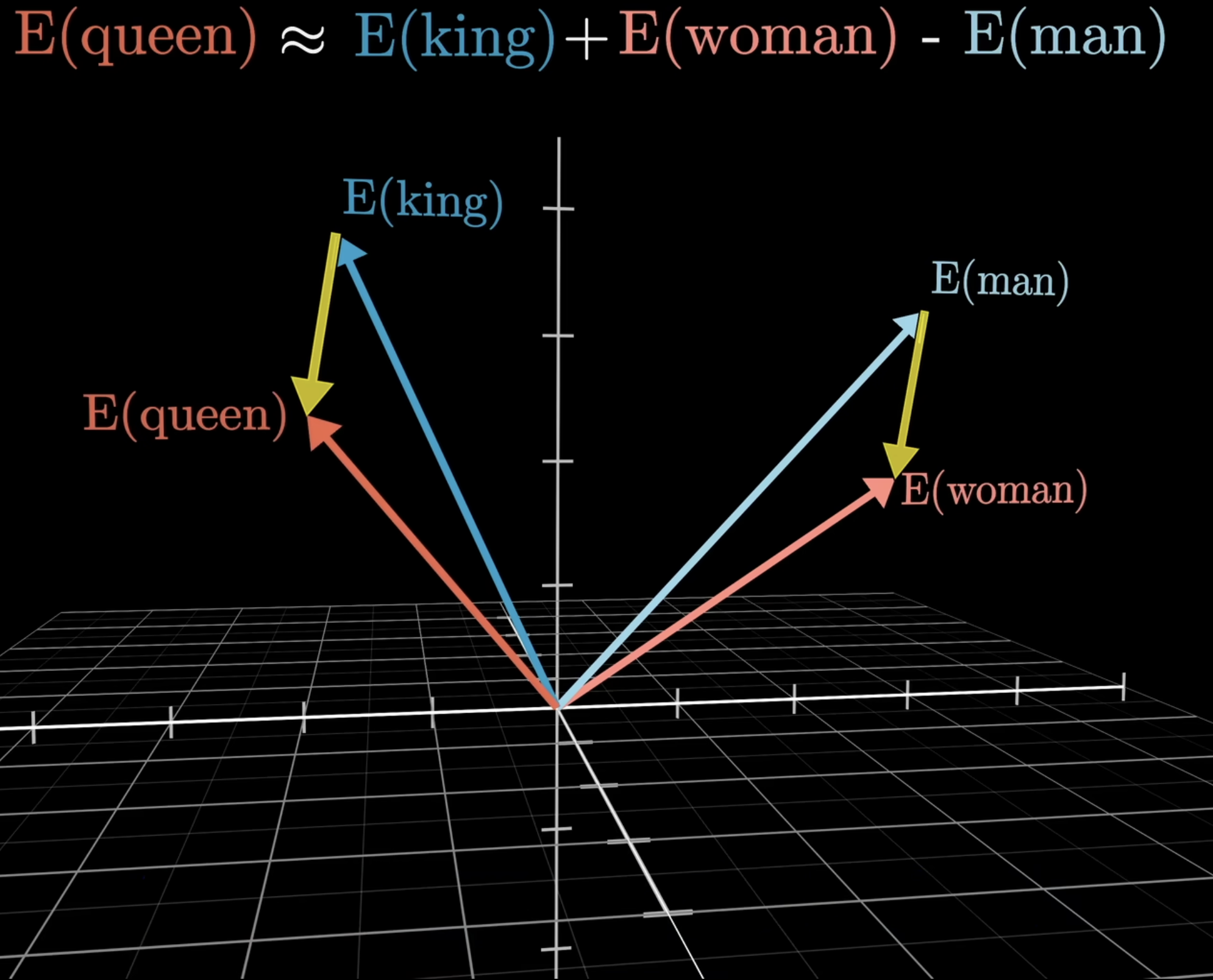
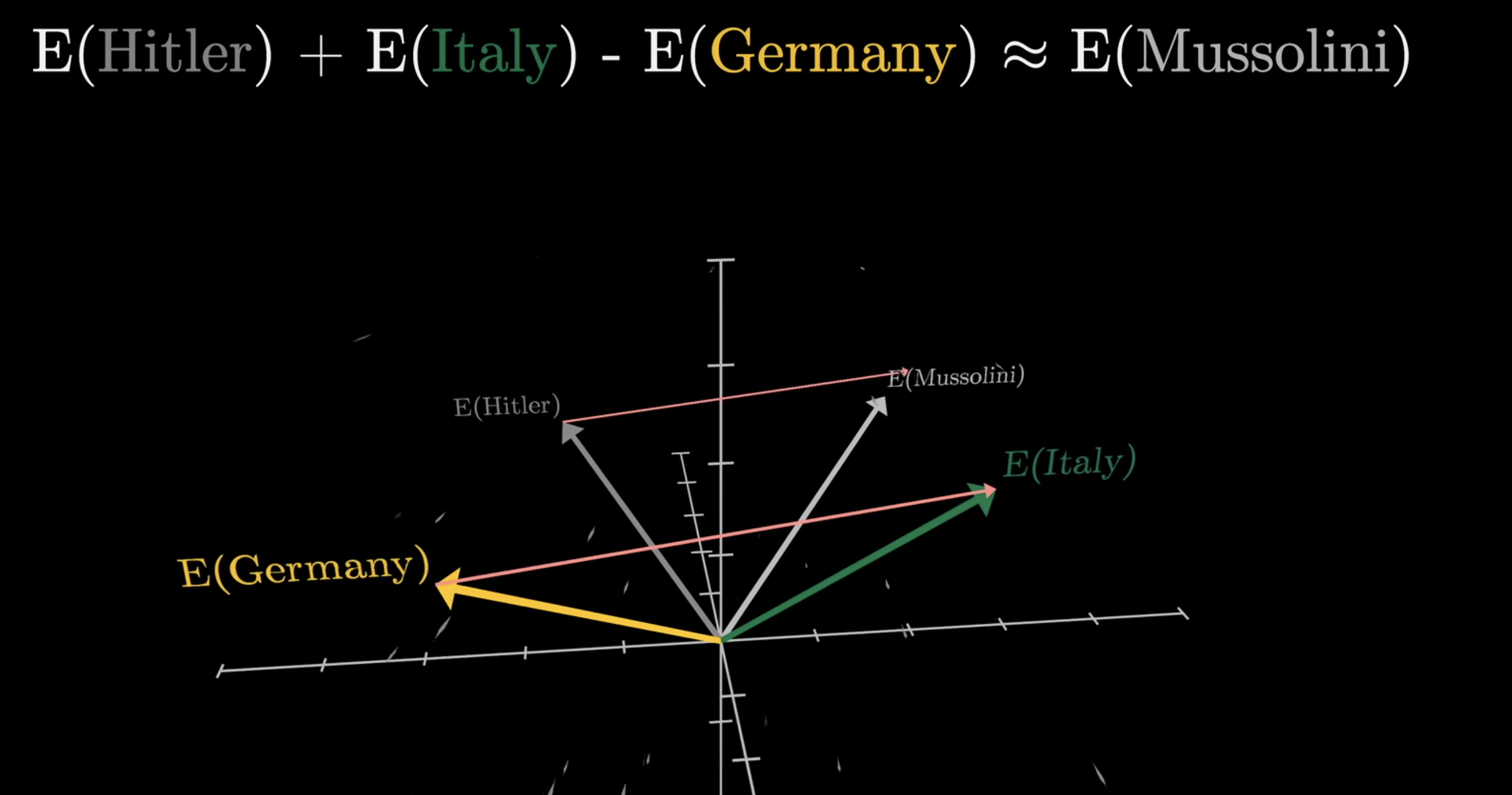
初看潜空间一词,会感到抽象与迷惑,不妨看下面的例子:潜空间中有四个向量分别表示queen,king,man,woman四个词。可以看到,向量queen和king在空间中距离很近,向量man和woman在空间中距离也很近。更有趣的是,向量queen和king的差值向量(红色)与向量woman和man的差值向量(蓝色)几乎平行,这说明这两个差值向量在语义上是相似的。也就是说,空间中的这些向量蕴含了丰富的语义信息。也就是说:潜空间存在一个方向,这个方向蕴含着性别信息。
2. 注意力机制的发展
假设有一个数据库,数据形式以键值对\((\mathbf{k,v})\)的形式存储着,{(“Zhang”, “Aston”), (“Lipton”, “Zachary”), (“Li”, “Mu”), (“Smola”, “Alex”), (“Hu”, “Rachel”), (“Werness”, “Brent”)} ,当发出查询(\(\mathbf{q}=\)Li)的时候,数据库返回值‘’Mu’’。如果我们想要用一种更鲁棒的形式去查询:例如,发出查询\(\mathbf{q}=\)Lii,数据库中没有严格对应的值,此时我们希望,数据库应当输出一个与‘’Mu‘’十分接近的值,因为Li与Lii更接近
系统定义上述行为:定义一个数据库\(D\),由多个键值对组成,即:\(\mathcal{D}\overset{\mathrm{def}}{\operatorname*{\operatorname*{=}}}\{(\mathbf{k}_1,\mathbf{v}_1),\ldots(\mathbf{k}_m,\mathbf{v}_m)\}\),我们可以定义给定查询\(q\)在数据集D上的注意力得分
\]
其中\(\alpha(\mathbf{q},\mathbf{k}_i)\in\mathbb{R}\left(i=1,\ldots,m\right)\)是一个权重函数,应当满足两点性质:
- 他用于刻画\(\mathbf{q},\mathbf{k}_i\)之间的相似程度,q与k越接近,权重应当越接近于1
- 同时满足归一化条件,可以用简单的softmax满足这一点,比如直接令\(\alpha(\mathbf{q},\mathbf{k}_i)=\frac{\exp(a(\mathbf{q},\mathbf{k}_i))}{\sum_j\exp(a(\mathbf{q},\mathbf{k}_j))}.\)
现在的问题是,如何寻找到一个可以刻画\(\mathbf{q},\mathbf{k}_i\)之间的相似程度的\(a\)函数呢?一个自然地想法是直接计算向量间的几何距离,然后平方展开。
\]
我们发现:如果\(\mathbf{k},\mathbf{q}\)的模长恒定,那么可以直接得到
\]
也就是说:直接使用两向量的点积,就可以很好的刻画二者的相似程度,点积越大,二者越相似!但是这样做存在两个问题
- 当\(q,k\)的维度\(d_k\)很大时,点积的数值会很大。
- 送进 softmax 之后,指数函数会放大差异,导致 softmax 输出非常极端!
为了解决发散问题,我们需要引入一个缩放因子\(\sqrt{d_k}\),其中\(d_k\)是键向量的维度。具体地,我们可以将注意力权重的计算改为(为什么除以他,可以参见附录的证明):
\]
二 经典架构的transformer
1. 整体推理流程
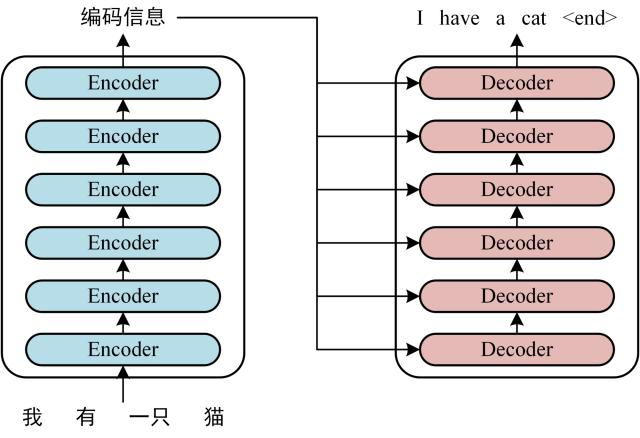
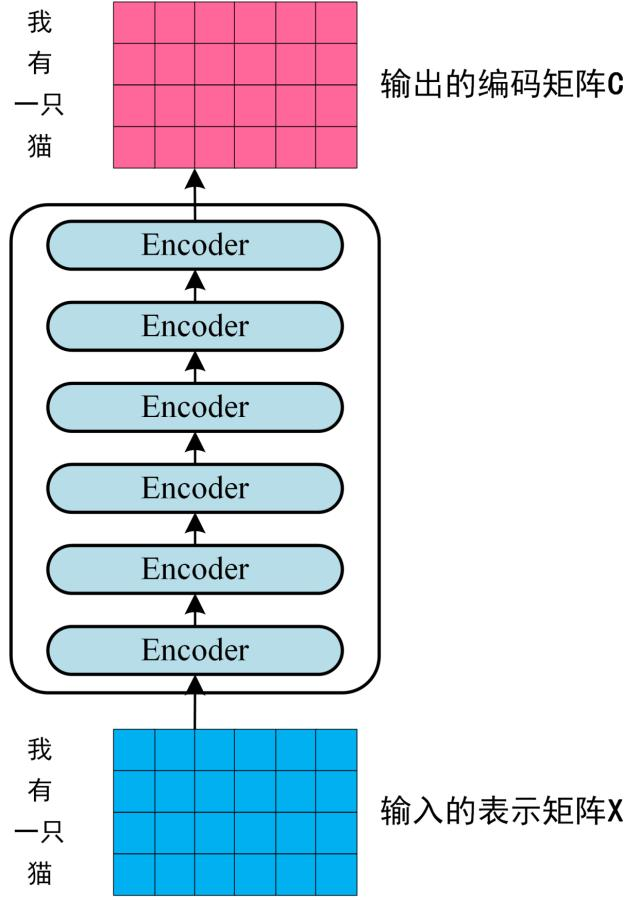
可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
第一步:获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
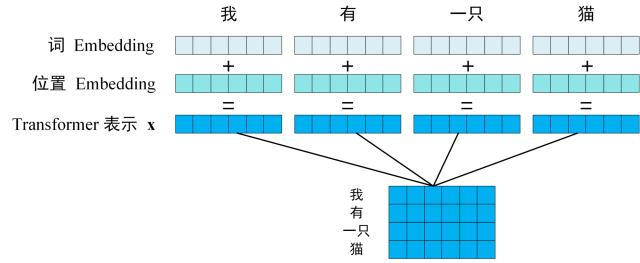
第二步:将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图:
第三步:将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
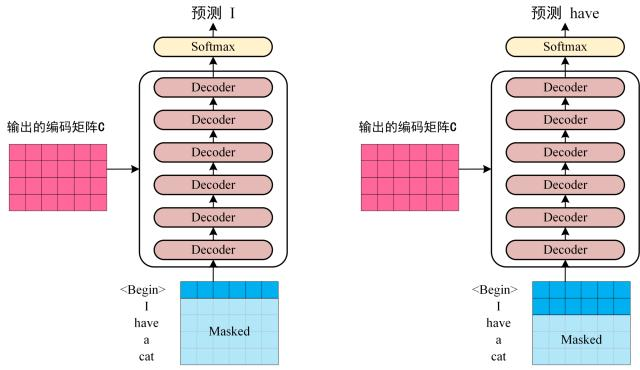
上图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 "",预测第一个单词 "I";然后输入翻译开始符 "" 和单词 "I",预测单词 "have",以此类推。
2. transfomer的输入
2.1 词向量Embedding
可以通过 Word2Vec等方法预训练,或者直接跟着transfomer一起训练。
2.2 位置编码Embedding
在Transformer的论文中,比较了用positional encoding和learnable position embedding(让模型自己学位置参数)两种方法,得到的结论是两种方法对模型最终的衡量指标差别不大。不过在后面的BERT中,已经改成用learnable position embedding的方法。
3. Self-Attention
3.1 单头注意力矩阵
让我们先来看看自注意力机制中,一个注意力头内部发生了什么
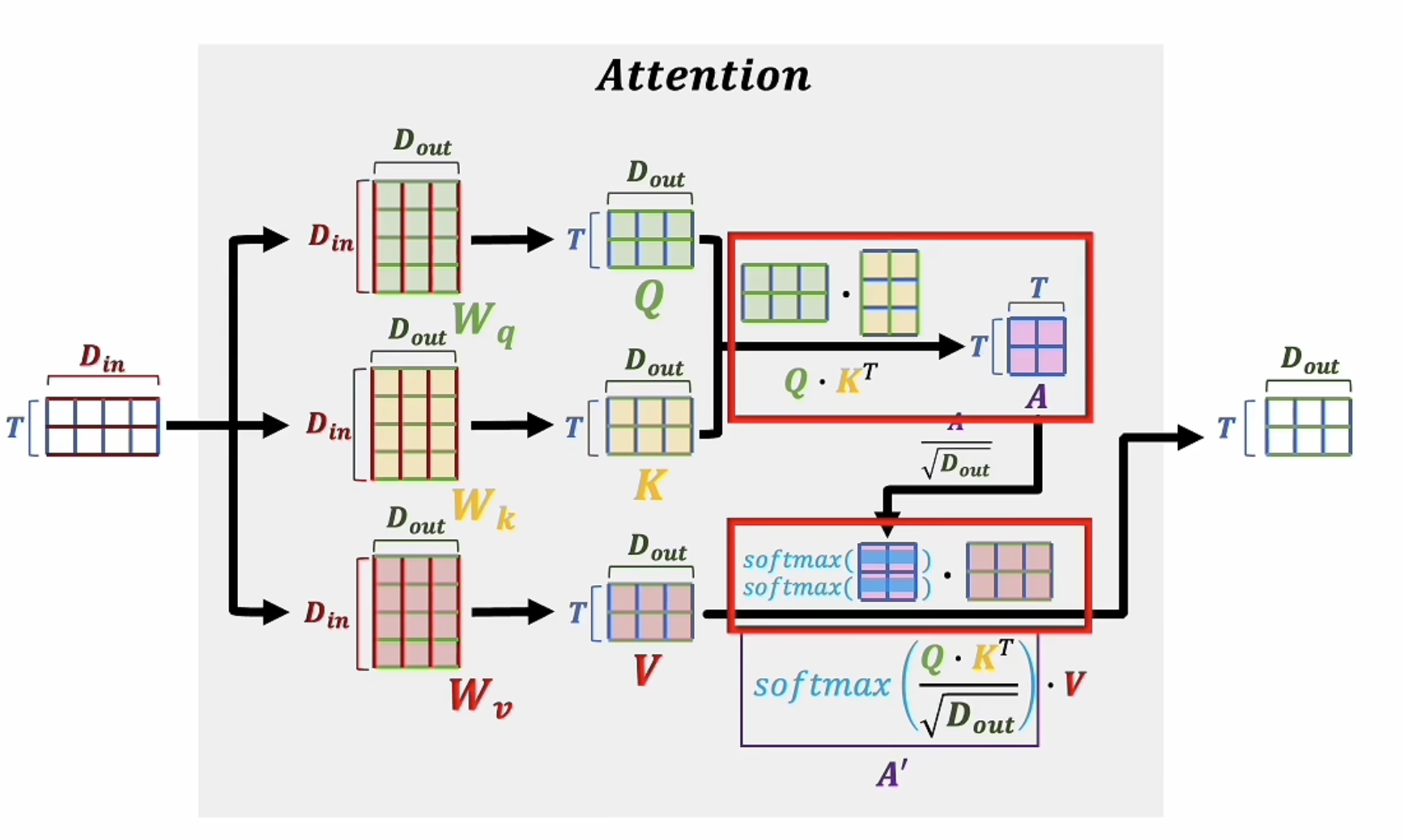
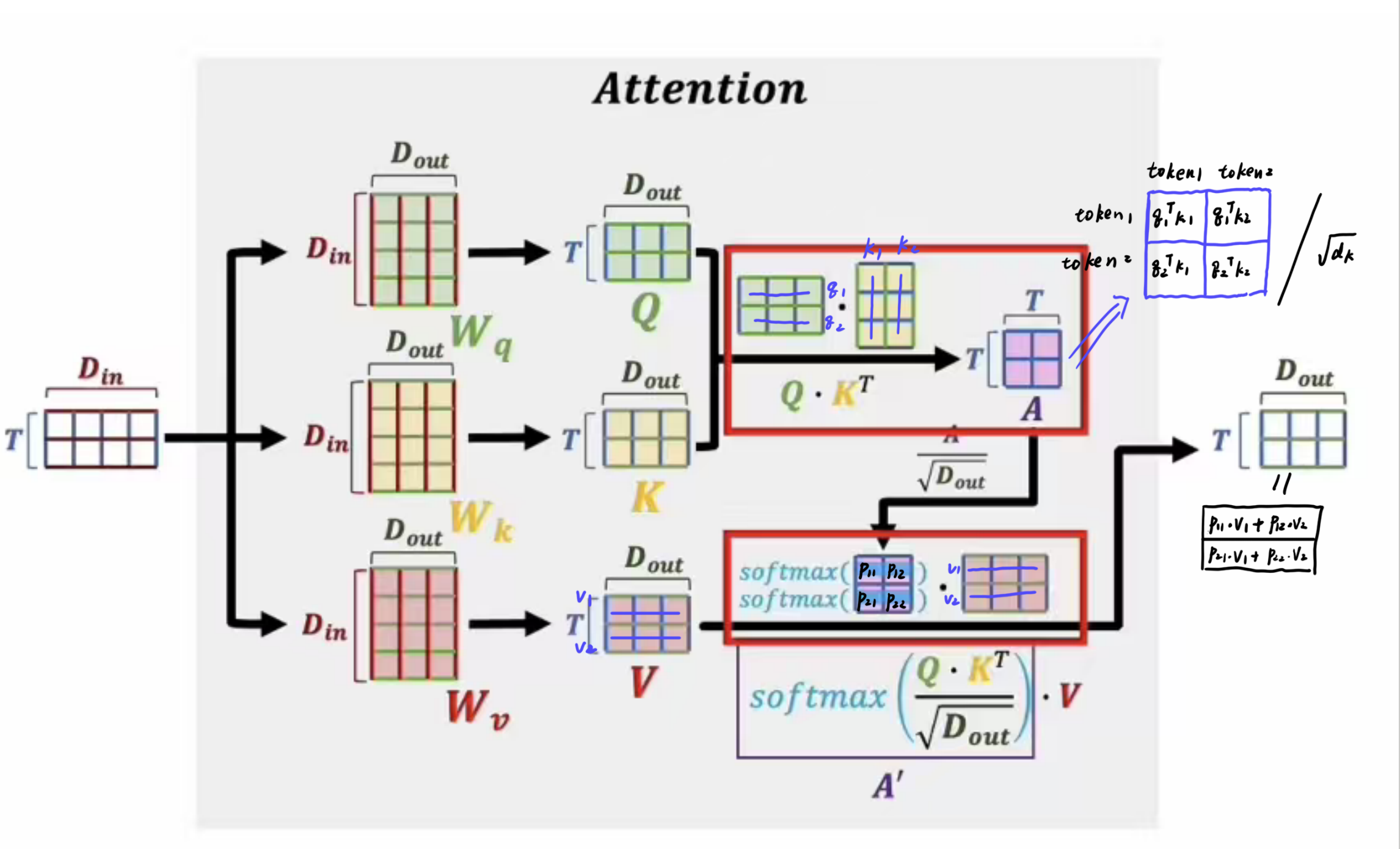
首先需要三个转换矩阵\(W_q,W_k,W_v\),这三个矩阵的维度均为\((D_{in},D_{out})\),其中\(D_{in}\)是初始的Embedding的维度,\(D_{out}\)是经过线性变换后的,降维的维度。用\(E_i\)表示第i个token的Embedding,\(E_i\)的维度为\((D_{in},)\),那么经过线性变换后,可以得到:
\]
\(q_i,k_i,v_i\)的维度均为\((D_{out},)\)。这三个向量分别表示query,key,value。
- query表示当前token的询问向量,其具体含义是:我想要找与我相关的token,我应该发出怎样的查询?
- key表示当前token的键向量,其具体含义是:我是谁?
- value表示当前token的值向量,其具体含义是:我能提供什么信息?
\(k,q\),本质上是在表征token之间的相关性,\(v\)则是表征某个token的语义,在翻译任务中,我们希望通过注意力模块,把每一个token变为蕴含着其他token信息的token,这就是自注意力机制的核心思想。

3.2 多头注意力机制
通常认为,每一个注意力头可以学习到一种token相关性的表达模式,类似于卷积神经网络,并行的多个卷积核可以学习到不同的图像特征一样,并行的多个注意力头可以学习到不同的token相关性模式。具体的可以用下图表示:
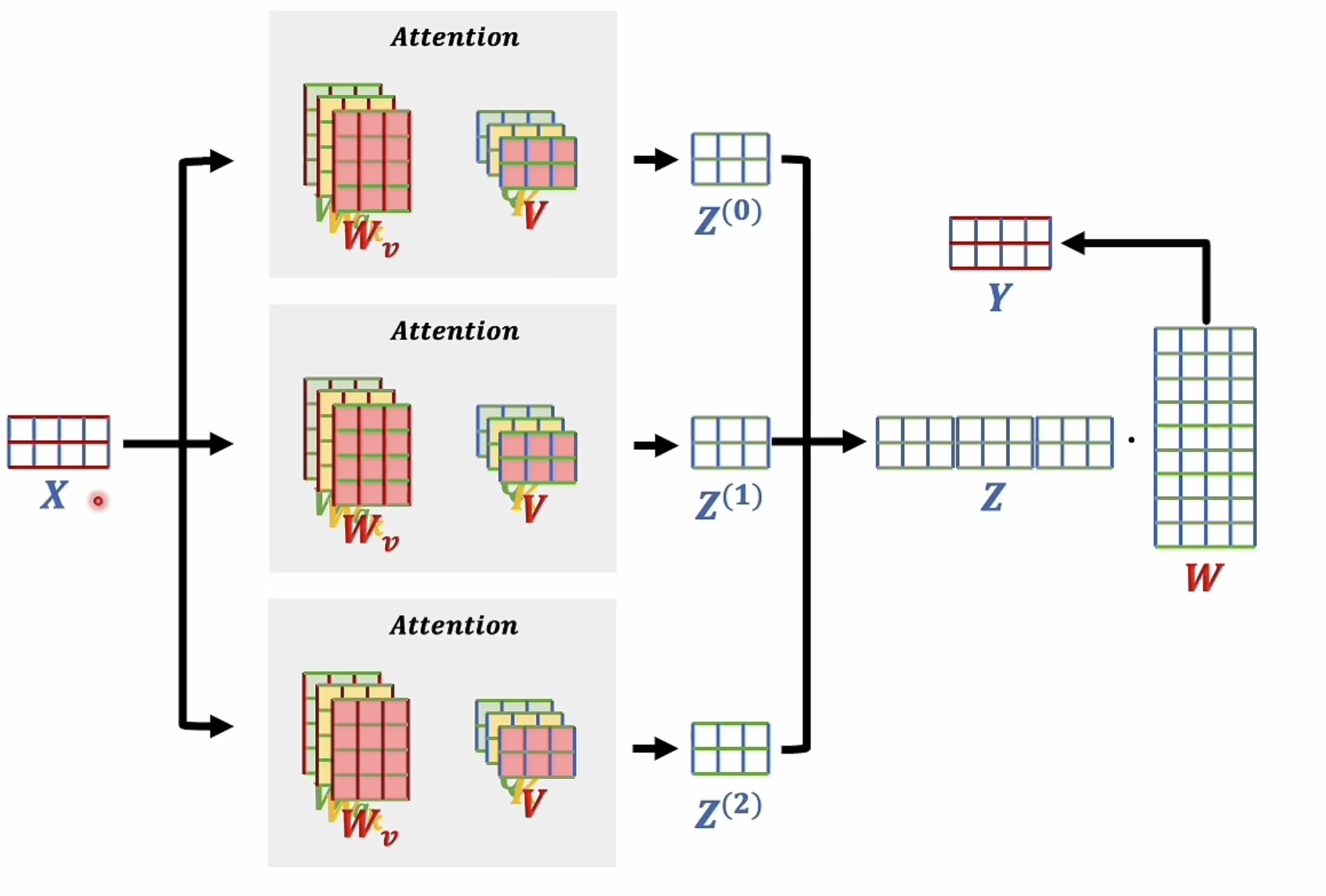
将不同的模式concat在一起,可以得到更丰富的token相关性表达,然后通过线性变换,用于保证输入输出形状不变,同时得到最终的token表示,此时输出的信息矩阵式一个高度抽象的token语义表示矩阵。
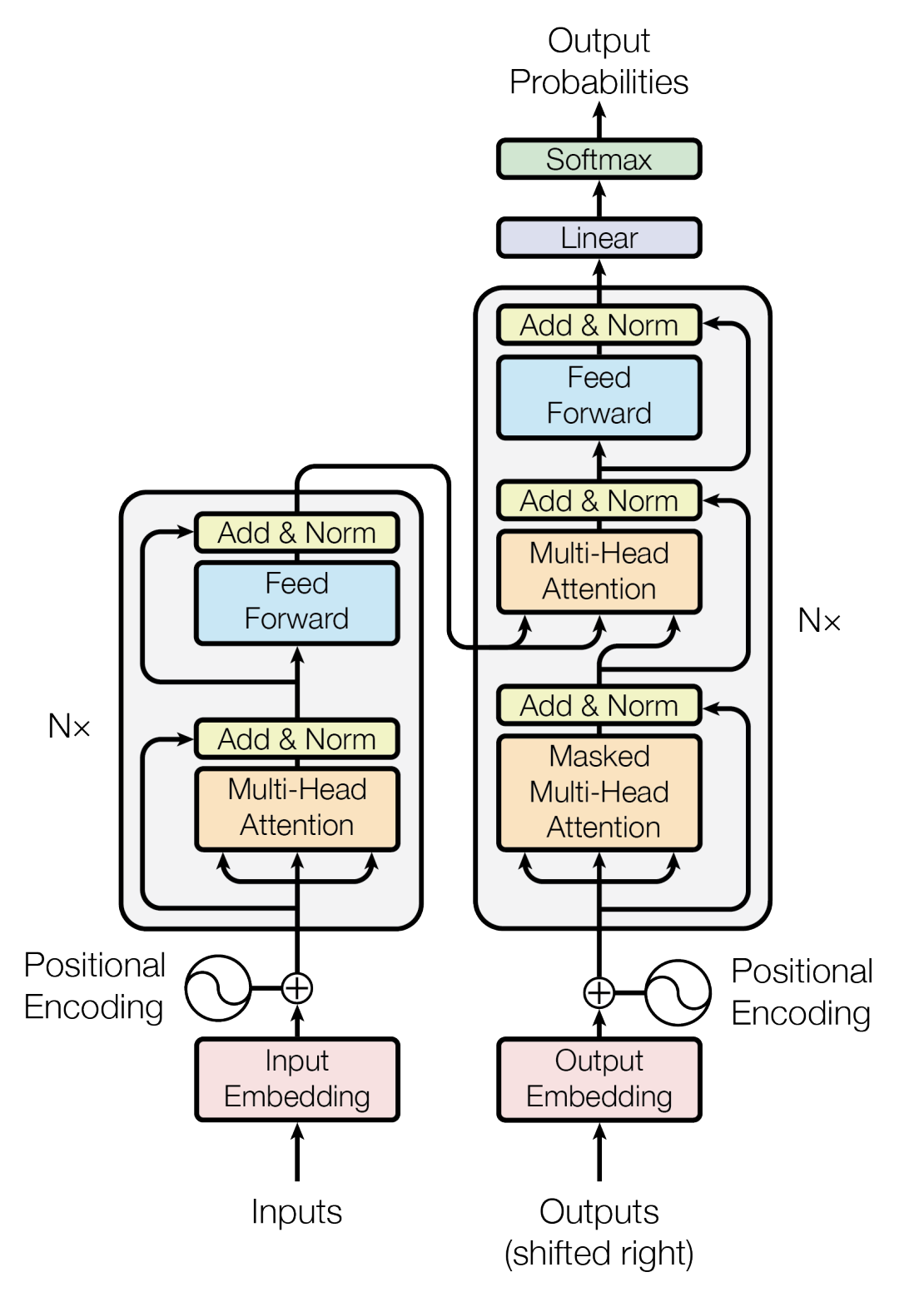
4. Encoder
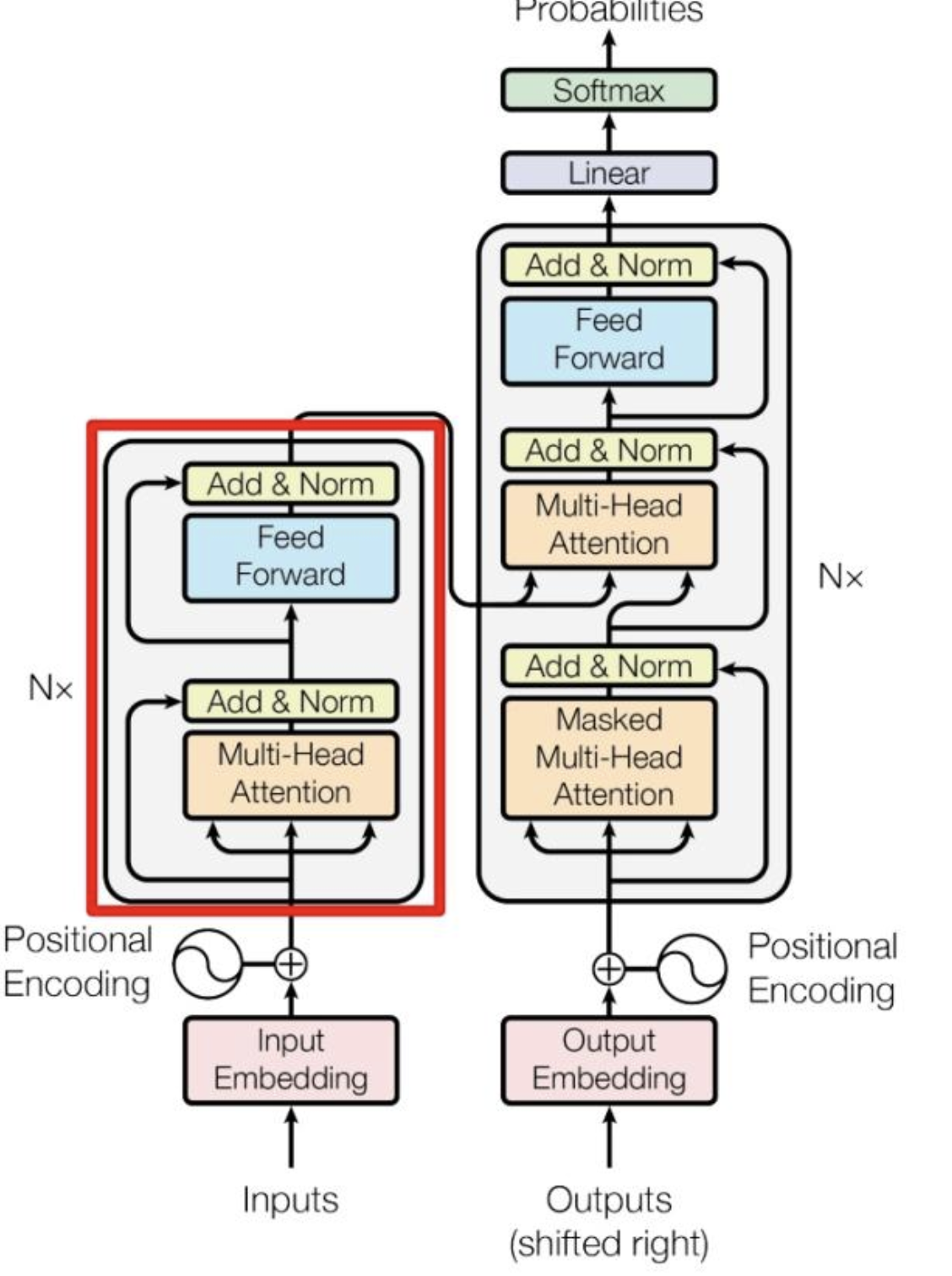
上图红色部分是 Transformer 的 Encoder block 结构,可以看到是由 Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm 组成的。刚刚已经了解了 Multi-Head Attention 的计算过程,
- 后面加了一个残差连接和归一化层,接着是一个前馈神经网络(Feed Forward),
- 再加一个残差连接和归一化层。
最终可以保证,一个Encoder block的输入输出形状是一样的。可以使用多个Encoder block 堆叠起来,形成一个深度的 Encoder,提取更丰富的句子信息。
5. Decoder
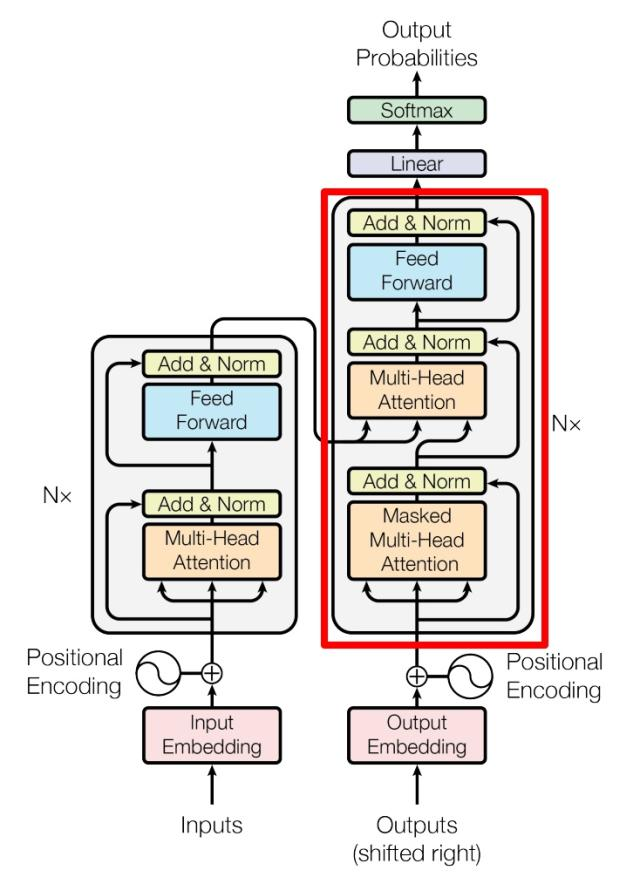
上图红色部分为 Transformer 的 Decoder block 结构,与 Encoder block 相似,但是存在一些区别:
- 包含两个 Multi-Head Attention 层。
- 第一个 Multi-Head Attention 层采用了 Masked 操作。
- 第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
- 最后有一个 Softmax 层计算下一个翻译单词的概率。
5.1 第一个 Multi-Head Attention
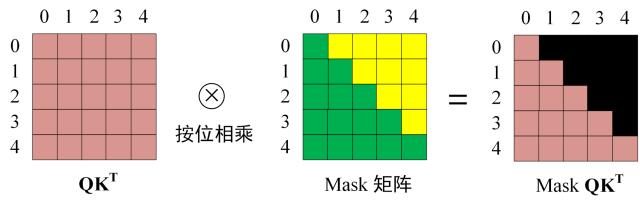
Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。 因此在翻译第 i+1 个单词的时候,不能使用第 i+1 个单词之后的信息,否则会造成信息泄露,影响模型的训练效果。
Masked 操作就是将第 i+1 个单词之后的单词的注意力权重置为负无穷,这样经过 Softmax 之后,这些单词的注意力权重就变为 0,不会对当前单词的翻译产生影响。
5.2 第二个 Multi-Head Attention
Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。
根据 Encoder 的输出 C计算得到 K, V,根据上一个 Decoder block 的输出 Z 计算 Q (如果是第一个 Decoder block 则使用输入矩阵 X 进行计算),后续的计算方法与之前描述的一致。
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息,相当于直在潜在语义空间中进行了对齐 (这些信息无需 Mask,因为中文翻译为英文的时候的时候,你虽然不能直接看英文的全文答案,但是可以看中文上下文去推断语义,交叉注意力机制也是如此)。
5.3 输出预测概率
最后一个 Decoder block 的输出经过一个线性变换和 Softmax 层,得到下一个翻译单词的概率分布。对于大型翻译模型,Linear层的输出维度是词库所有单词的个数,例如你的词库收集了常见的英文2000词,那么输出的linear节点就有2000个,softmax后每个节点就代表着每个单词的概率。
三 GPT-3 decoder-only的transformer
现在的主流大模型都是decoder-only的结构,就是说他们使用的transfomer都是只有右半边的,是一个单纯的生成模型,生成依据仅仅是给定的文本,也就是用户输入的文本。
GPT-3采用一个巨大的Embedding矩阵,其大小为 50257 * 12288 (词数量*Embedding维度)
.png)
GPT-3的思路就是不断堆叠注意力矩阵和前馈神经网络,来不断地提取token之间的相关性,并且将这种相关性融入到token的表示中去。最终,经过多层注意力矩阵和前馈神经网络的处理后,得到的每一个token的表示中都蕴含了其他token的信息,这样就可以用这些表示来预测下一个token。

所能接受的矩阵最大token数量,叫做Context Size,GPT3的Context Size是2048。
具体的参数:
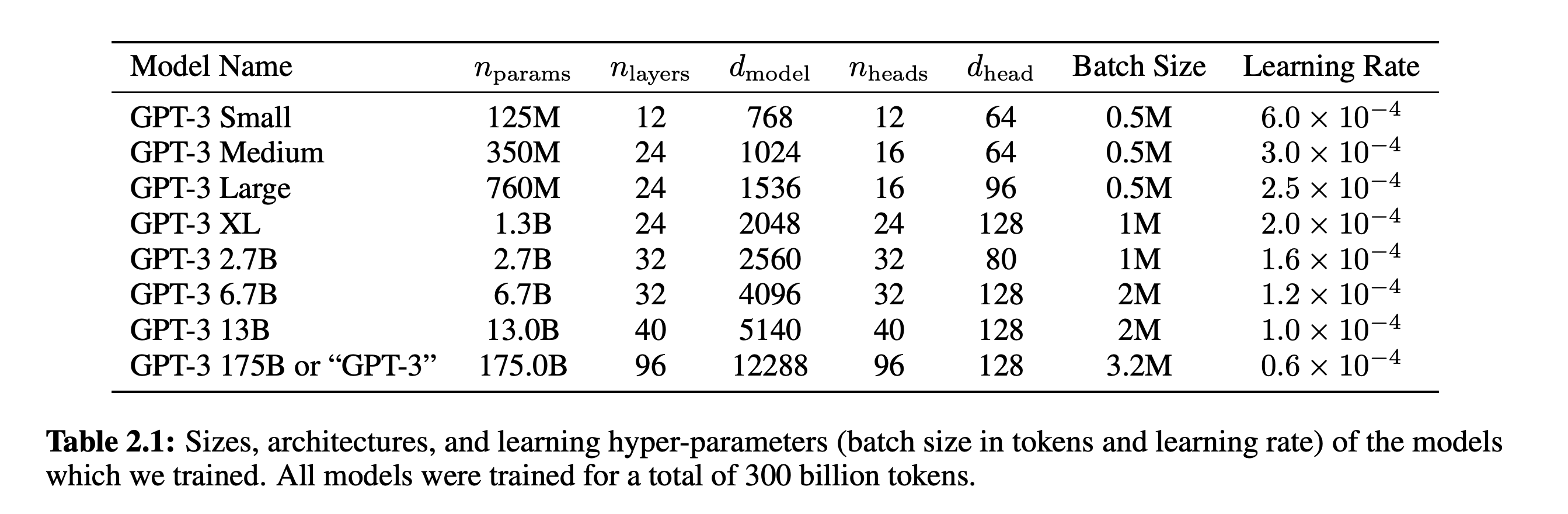
- \(n_{layers}\)Transformer 堆叠的层数(即多少个 Decoder block)
- \(d_{model}\)Transformer 中每个 token 的表示维度(压缩前)
- \(n_{heads}\)Multi-Head Attention 中的头数
- \(d_{head}\) Multi-Head Attention 中每个头的表示维度(压缩后)
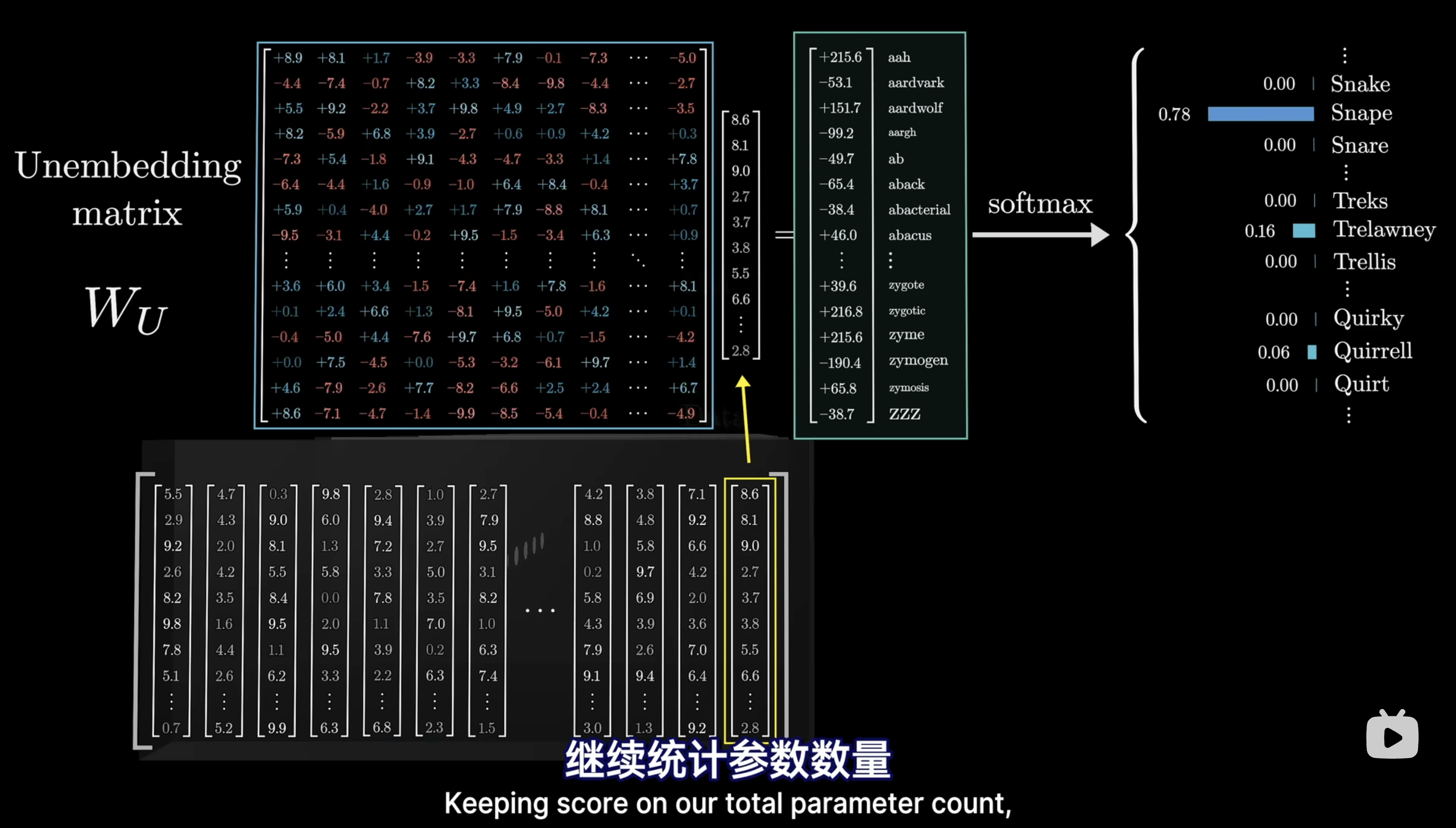
总体来说,GPT-3模型采用了九十六个Transformer block,每个block包含了96个并行训练的注意力头,每个注意力头将12288维的Embedding压缩为128维度的高级语义表示,然后再将96个128维的表示concat在一起,通过前馈+残差连接等模块恢复为12288维的表示。
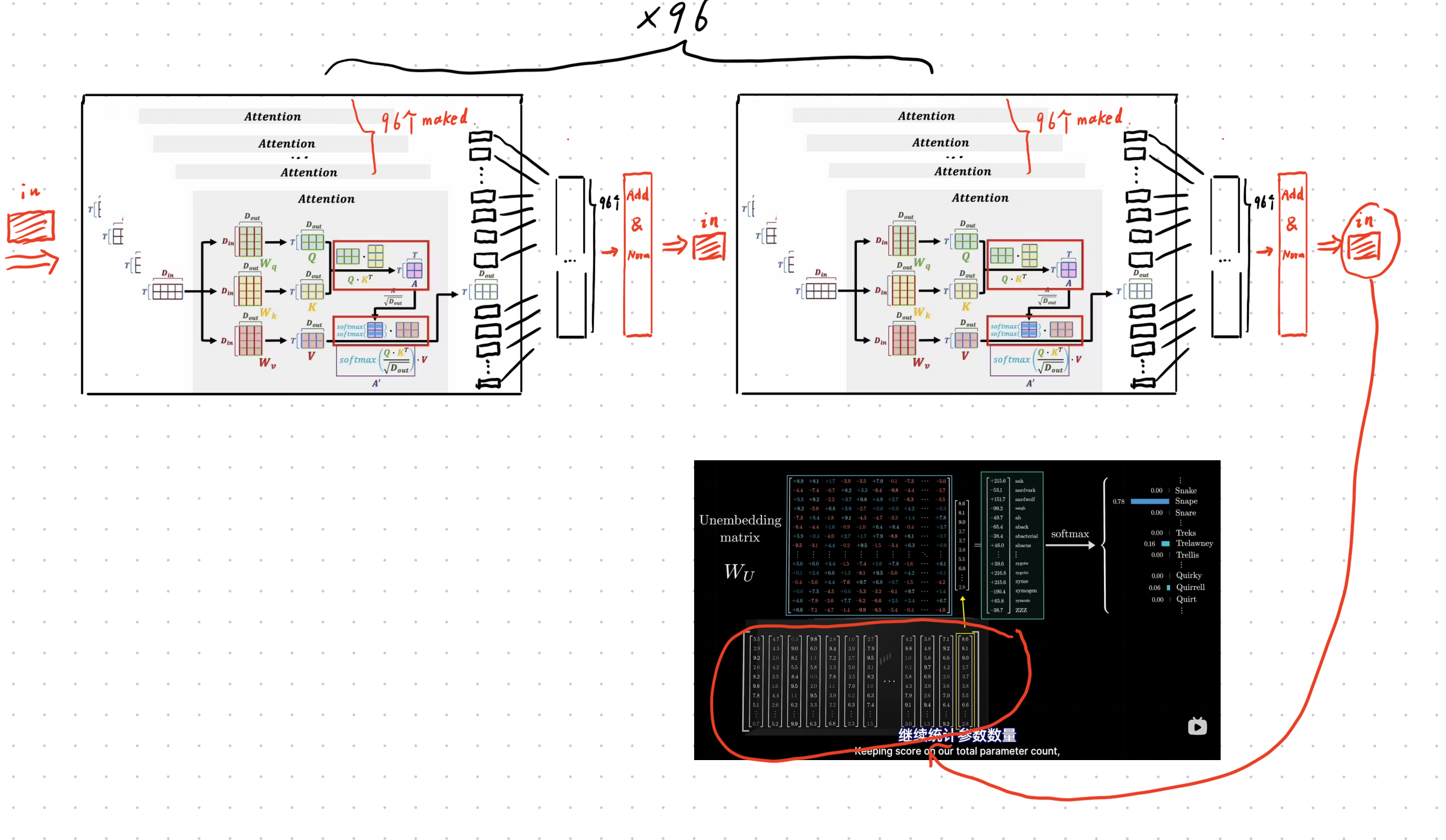
最后输出概率,只使用了高级抽象语义矩阵的最后一列。
四 BERT encoder-only的transformer
BERT模型的全称是:BidirectionalEncoder Representations from Transformer。从名字中可以看出,BERT模型的目标是利用大规模无标注语料训练、获得文本的包含丰富语义信息的Representation
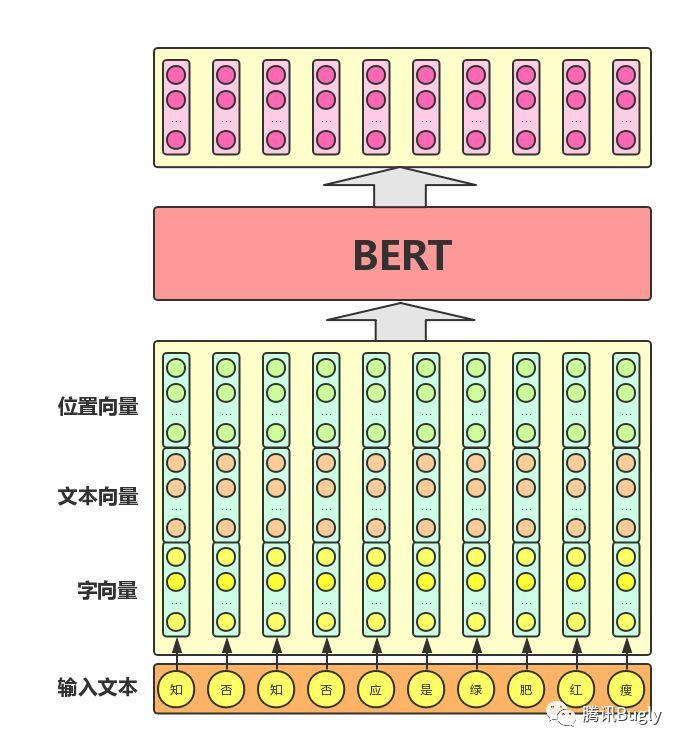
从上图中可以看出,BERT模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入;模型输出则是输入各字对应的融合全文语义信息后的向量表示。此外,模型输入除了字向量,还包含另外两个部分:
文本向量:该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合
位置向量:由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:“我爱你”和“你爱我”),因此,BERT模型对不同位置的字/词分别附加一个不同的向量以作区分
BERT应用场景
文本分类
对于文本分类任务,BERT模型在文本前插入一个[CLS]符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类,如下图所示。可以理解为:与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息。
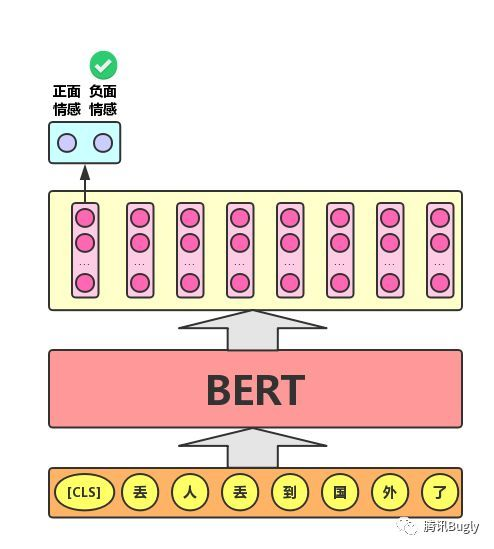
情感分析
加入一个softmax层,输出正面和负面情感的概率。也可以多种情感去分析
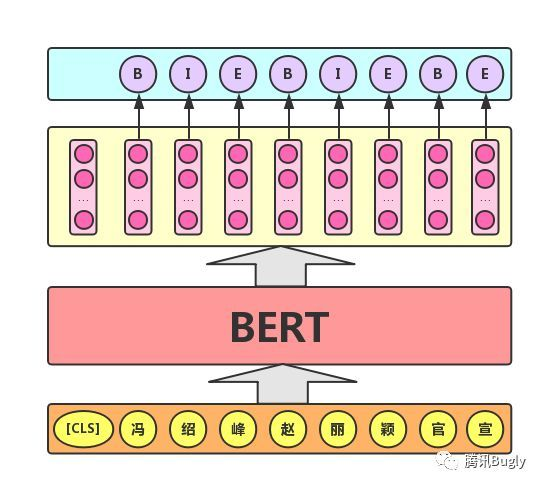
序列标注
序列标注任务:该任务的实际应用场景包括:中文分词&新词发现(标注每个字是词的首字、中间字或末字)、答案抽取(答案的起止位置)等。对于该任务,BERT模型利用文本中每个字对应的输出向量对该字进行标注(分类),如下图所示(B、I、E分别表示一个词的第一个字、中间字和最后一个字)。
实际上,利用预训练好的BERT,可以完成的场景是极其丰富的,以上仅是其中的几个典型场景。
预训练
BERT模型的预训练任务包括:掩码语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)。其中,MLM任务用于学习字/词的语义表示,NSP任务用于学习文本的全局语义表示。
MLM
Masked Language Model 的训练就是:随机遮盖输入序列中的部分词,用 Transformer Encoder 将整个序列映射成上下文感知的向量,再通过线性层 + softmax 预测被遮盖的词,利用交叉熵损失让模型学会根据上下文推断缺失词,从而捕捉全局语义信息。
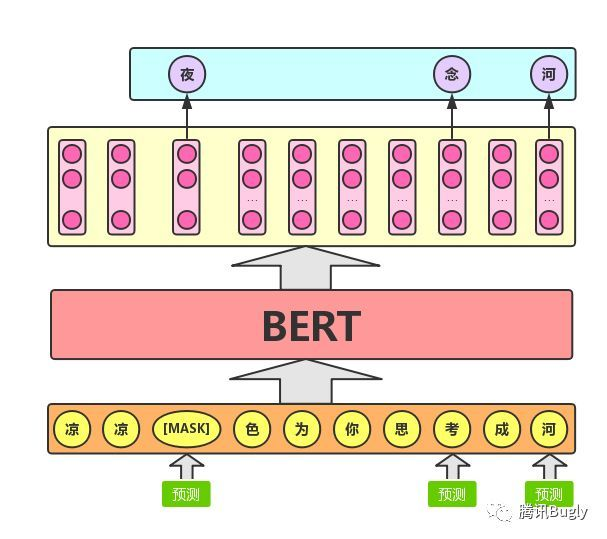
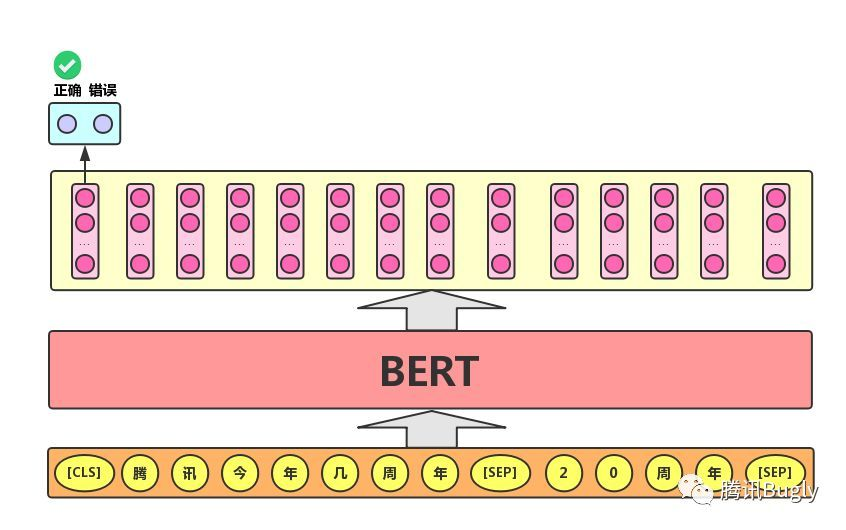
NSP
Next Sentence Prediction的任务描述为:给定一篇文章中的两句话,判断第二句话在文本中是否紧跟在第一句话之后,如下图所示。
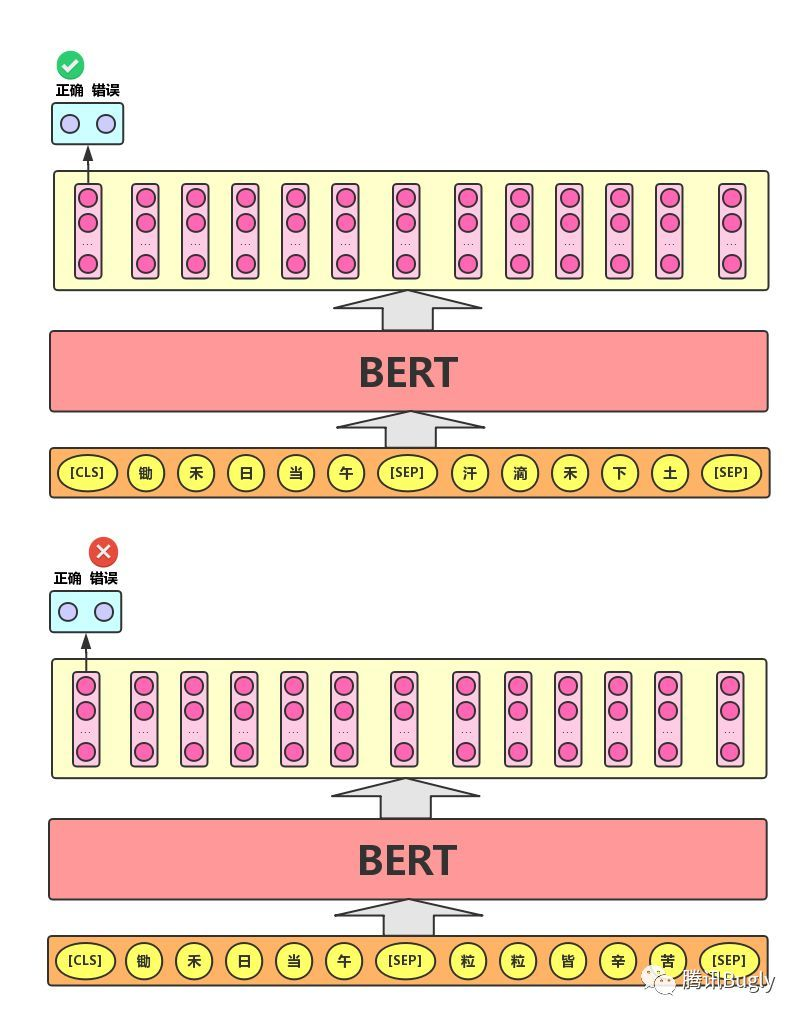
MLM 只能学习单句上下文的信息。
NSP 则让模型理解句子之间的逻辑关系,例如前后句衔接、因果关系等。
在下游任务(如问答、自然语言推理、文本匹配)中,这种句子关系信息非常重要。
当然,上面提到的[CLS]、[SEP] 都是可训练的 token embedding。
五 transfomer用于视觉任务
ViT
2021 年,谷歌研究院在里程碑式论文《一张图片胜过 16x16 个单词》中推出了 ViT,ViT 将这种变革性方法从语言数据应用到视觉数据。正如传统的 Transformer 将句子分解成单词 token 一样,ViT 将图像划分为固定大小的 patch,并将每个 patch 视为一个“视觉 token”。然后,这些 patch 被线性嵌入,并补充位置编码以保留空间信息——这与 NLP Transformer 中单词的嵌入和排序方式如出一辙。
图像块嵌入序列被输入到 Transformer 编码器中,自注意力机制在其中学习图像不同区域之间的关系,就像它们捕捉句子中单词之间的依赖关系一样。一个特殊的分类标记(类似于 NLP 模型中的 [CLS] 标记)用于聚合来自所有图像块的信息,以用于图像级任务。通过这种类比,Vision Transformer 利用了彻底改变语言理解的相同架构,在图像识别领域取得了最先进的成果,展现了 Transformer 框架在不同领域的多功能性和强大功能。
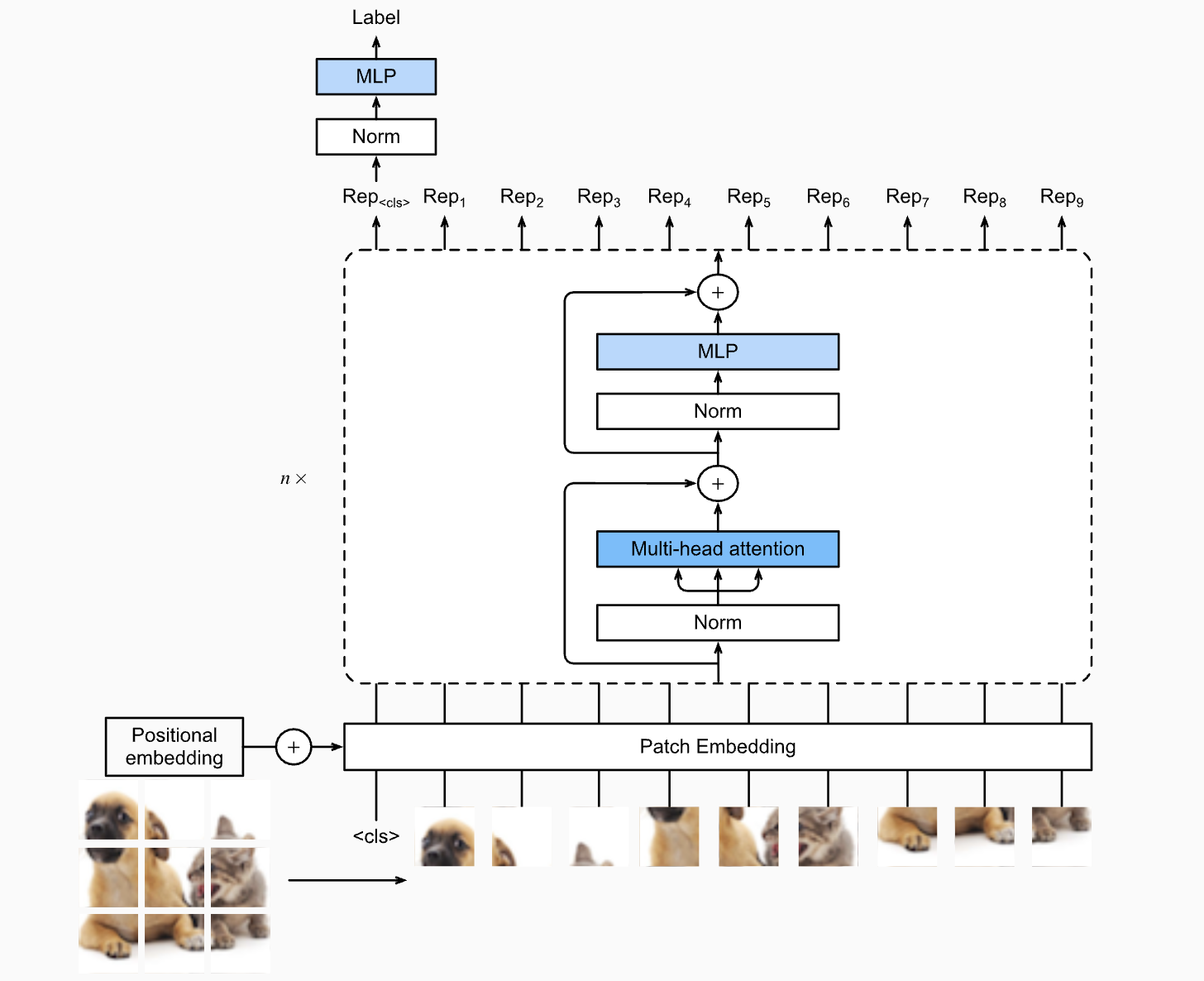
应当讲,ViT的在直觉上与人类观察图片的方式是相似的。人类在观察一张图片时,通常会先关注图片的整体结构和主要元素,然后逐渐注意到细节部分。ViT通过将图像划分为多个patch,并利用自注意力机制来捕捉这些patch之间的关系,模拟了人类从整体到局部的观察过程。

相比之下,Vision Transformers 从一开始就使用自注意力机制来建模图像块之间的全局关系,从而使其能够捕捉图像中的长距离依赖关系和整体上下文。这种全局视角使 ViT 在大规模数据集和需要全面理解视觉内容的任务上的表现优于 CNN。
然而,ViT 通常需要更多数据才能有效训练,并且通常计算量更大,尤其是在更高分辨率下。
CNN与ViT本质区别何在?
推荐一篇论文HOW DO VISION TRANSFORMERS WORK? ICIR 2022
这篇论文认为:cnn本质上就是一堆算子的结合,可视为一堆高通滤波器的叠加,其会不断强化高频信息,而transformer由于其大量线性计算+聚合的特性,本质上是个低通滤波器,会不断强化图像的底层语义信息,说简单些,cnn是自顶向下的学习,transformer相反,是自底向上去构建特征的,这就导致transformer的训练十分困难,需要大量的数据构建起正确的地基,上层的建筑才能稳固。
cnn做检测就是,这张图那里有个鸟嘴,所以这里有只鸟。transformer做检测就是,这张图那里有棵树,树上有个东西,有可能是鸟。
Appendix
Proof.关于归一化的证明
Setup. \(q,k\in\mathbb{R}^d\), \(q_i,k_i\) i.i.d., mutually independent, \(\mathbb{E}[q_i]=\mathbb{E}[k_i]=0\), \(\mathrm{Var}(q_i)=\mathrm{Var}(k_i)=1\).
\langle q,k\rangle &= \sum_{i=1}^d q_i k_i.\\[4pt]
\mathbb{E}[\langle q,k\rangle] &= \sum_{i=1}^d \mathbb{E}[q_i k_i]
= \sum_{i=1}^d \mathbb{E}[q_i]\mathbb{E}[k_i] = 0.\\[6pt]
\mathrm{Var}(\langle q,k\rangle)
&= \mathbb{E}\!\left[\left(\sum_{i=1}^d q_i k_i\right)^2\right]
- \big(\mathbb{E}[\langle q,k\rangle]\big)^2 \\[2pt]
&= \mathbb{E}\!\left[\sum_{i=1}^d (q_i k_i)^2
+ 2\!\!\sum_{1\le i<j\le d}\! q_i k_i q_j k_j\right] \\[2pt]
&= \sum_{i=1}^d \mathbb{E}[q_i^2]\mathbb{E}[k_i^2]
+ 2\!\!\sum_{i<j}\! \mathbb{E}[q_i]\mathbb{E}[k_i]\mathbb{E}[q_j]\mathbb{E}[k_j] \quad (\text{indep.})\\[2pt]
&= \sum_{i=1}^d (1)(1) + 0 = d.
\end{aligned}
\]
\]
Discussion:位置编码向量的选择
观点:三角函数的位置编码数学优美,但不如直接训练
https://spaces.ac.cn/archives/8231
\]
观点:两种路线
https://zhuanlan.zhihu.com/p/712276260
GPT-3.5、LLaMA 系列、Mistral、ChatGLM 等生成型大模型使用了相对位置编码相对位置编码 / RoPE,训练型(Learned)位置编码则在BERT家族中经常使用,(以短文本 NLP 任务为主)
参考文献
- Attention is All You Need. https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
- Language Models are Few-Shot Learners https://arxiv.org/pdf/2005.14165.pdf
- HOW DO VISION TRANSFORMERS WORK? ICIR 2022 https://arxiv.org/pdf/2202.06709
- 李沐:动手学pytorch https://d2l.ai/chapter_attention-mechanisms-and-transformers/index.html
- https://zhuanlan.zhihu.com/p/338817680
- https://www.cnblogs.com/Milburn/p/12031501.html
- 3blue1brown 直观解释注意力机制 https://www.bilibili.com/video/BV1TZ421j7Ke/?spm_id_from=333.337.search-card.all.click&vd_source=84b977d2834d5eca6c0ca78bd619156f
- 王木头,从编解码和词嵌入开始,一步一步理解Transformer,注意力机制(Attention)的本质是卷积神经网络(CNN) https://www.bilibili.com/video/BV1XH4y1T76e/?spm_id_from=333.337.search-card.all.click&vd_source=84b977d2834d5eca6c0ca78bd619156f
- 从位置编码到rope https://zhuanlan.zhihu.com/p/712276260
- 苏剑林博客 https://spaces.ac.cn/archives/8231
- 知乎回答 https://www.zhihu.com/question/507503981/answer/2693830944
transfomer架构探究的更多相关文章
- 关于nginx架构探究(1)
nginx的架构主要是有一个主监控进程:master;三个工作进程:worker:还有Cache的两个进程.back-end-server是后端服务器,主要是处理后台逻辑.nginx作为代理服务器需要 ...
- 死磕安卓前序:MVP架构探究之旅—基础篇
前言 了解相关更多技术,可参考<我就死磕安卓了,怎么了?>,接下来谈一谈我们来学习一下MVP的基本认识. 大家对MVC的架构模式再熟悉不过.今天我们就学习一下MVP架构模式. MVC和MV ...
- 关于nginx架构探究(4)
事件管理机制 Nginx是以事件驱动的,也就是说Nginx内部流程的向前推进基本都是靠各种事件的触发来驱动,否则Nginx将一直阻塞在函数epoll_wait()或suspend函数,Nginx事件一 ...
- 关于nginx架构探究(3)
Nginx 模块综述 Nginx 所有的代码都是以模块的新式组织的,包括核心模块和功能模块.Nginx加载模块的时候不想Apache一样动态加载,它是直接被编译到二进制执行文件中,所以,如果想要加载新 ...
- 关于nginx架构探究(2)
nginx 数据结构 1.Hash table nginx 对虚拟主机的管理使用到了HASH数据结构,假设配置文件里有如下的配置. Server{ listen 192.168.0.1 server_ ...
- 改造 Android 官方架构组件 ViewModel
前言 Android 官方架构组件在今年 5 月份 Google I/O 大会上被公布, 直到 11 月份一直都是测试版, 由于工作比较繁忙, 期间我只是看过类似的文章, 但没有在实际项目中使用过, ...
- 高性能高并发服务器架构设计探究——以flamigo服务器代码为例
这篇文章我们将介绍服务器的开发,并从多个方面探究如何开发一款高性能高并发的服务器程序. 所谓高性能就是服务器能流畅地处理各个客户端的连接并尽量低延迟地应答客户端的请求:所谓高并发,指的是服务器可以同时 ...
- 庐山真面目之十四微服务架构的Docker虚拟技术深入探究
庐山真面目之十四微服务架构的Docker虚拟技术深入探究 一.我的开场白 曾几何时,分布式的发展也影响了后来的微服务架构的实现方式.到了现在,只要涉及到互联网技术领域,就会设计一个概念,那就是微服务. ...
- 【深入浅出 Yarn 架构与实现】4-5 RM 行为探究 - 启动 ApplicationMaster
本节开始,将对 ResourceManager 中一些常见行为进行分析探究,看某些具体关键的行为,在 RM 中是如何流转的.本节将深入源码探究「启动 ApplicationMaster」的具体流程. ...
- 【深入浅出 Yarn 架构与实现】4-6 RM 行为探究 - 申请与分配 Container
本小节介绍应用程序的 ApplicationMaster 在 NodeManager 成功启动并向 ResourceManager 注册后,向 ResourceManager 请求资源(Contain ...
随机推荐
- 企业微信hook,自定义工具,收发消息
协议版本 示例: 企业微信协议开发, 配置服务器开启服务端,接口开发企业微信协议接口开发,接收发送json数据即可: 接口调用:http请求 接下来 拿uuid去调用其他接口即可 例:发送位置 请求方 ...
- Java 集合框架底层数据结构实现深度解析
Java 集合框架(Java Collections Framework, JCF)是支撑高效数据处理的核心组件,其底层数据结构的设计直接影响性能与适用场景.本文从线性集合.集合.映射三大体系出发,系 ...
- 探索大模型:袋鼠云在 Text To SQL 上的实践与优化
Text To SQL 指的是将自然语言转化为能够在关系型数据库中执行的结构化查询语言(简称 SQL).近年来,伴随人工智能大模型技术的不断进步,Text To SQL 任务的成功率显著提升,这得益于 ...
- 开源共建 | TIS整合数据同步工具ChunJun,携手完善开源生态
TIS整合ChunJun实操 B站视频: https://www.bilibili.com/video/BV1QM411z7w5/?spm_id_from=333.999.0.0 一.ChunJun ...
- 未能加载文件或程序集“System.Runtime.WindowsRuntime, Version=4.0.14.0, Culture=neutral, PublicKeyToken=b77a5c561934e089”或它的某一个依赖项。不应出于执行的目的加载引用程序集。只能在仅限反射的加载程序上下文中加载引用程序集。 (异常来自 HRESULT:0x80131058)
VS项目编译时报错: 未能加载文件或程序集"System.Runtime.WindowsRuntime, Version=4.0.14.0, Culture=neutral, PublicK ...
- Web前端入门第 69 问:JavaScript Promise 提供的方法都使用过吗?
Promise 这个 API 曾在 JS 领域掀起过血雨腥风,以前的大佬们都喜欢手搓一个自己的 Promise 用以理解 Promise 的原理. Promise 的诞生,应该多少都有受到 jQuer ...
- 一文看懂——SimSolid的优势
在当今日益复杂的工程设计领域,大型装配体的分析变得愈发重要.装配体是由多个零件.部件或子装配体按照一定规则和技术要求组合而成的整体,其性能的好坏直接影响到整个产品的质量和可靠性. 然而,传统的有限元分 ...
- 免费开源 .NET OpenCV 迷你运行时全平台发布
免费开源 .NET OpenCV 迷你运行时全平台发布 --Sdcb.OpenCvSharp4 Mini Runtime v4.11.0.35 上线 各位朋友好! 经过数周的持续打磨,我一次性放出了 ...
- Krpano krpanotools 命令行工具包
PHP Krpano 工具包 集成krpanotools工具命令,不用看官方文档.即可使用的工具包几行代码搞定krpanotools搞定生涩的命令. krpano Tools (Command-Lin ...
- 开源 vGPU 方案 HAMi 原理分析 Part1:hami-device-plugin-nvidia 实现
本文为开源的 vGPU 方案 HAMi 实现原理分析第一篇,主要分析 hami-device-plugin-nvidia 实现原理. 之前在 开源 vGPU 方案:HAMi,实现细粒度 GPU 切分 ...