轻松的工作(deepseek)
组长:“这里有一百多个地震波形文件,把每一个地震建立一个文件夹,并把地震波形放到对应日期的地震中。”
我想:一个一个整好麻烦想摸会鱼 让我们来deepseek吧~
首先,生成文件夹:告诉deepseek,我想要什么

使用Python脚本(适合批量处理)
import os
from openpyxl import load_workbook
# 设置路径和Excel文件
excel_path = 'test.xlsx' # Excel文件路径
save_path = './' # 目标文件夹路径
column_letter = 'A' # 数据所在列(如A列)
# 读取Excel数据
wb = load_workbook(excel_path)
ws = wb.active
# 遍历单元格创建文件夹
for row in ws[column_letter]:
folder_name = str(row.value).strip()
if folder_name and folder_name != 'None': # 跳过空单元格
full_path = os.path.join(save_path, folder_name)
os.makedirs(full_path, exist_ok=True) # exist_ok避免重复报错
print("文件夹创建完成!")
这是我的Excel文件(test.xlsx)
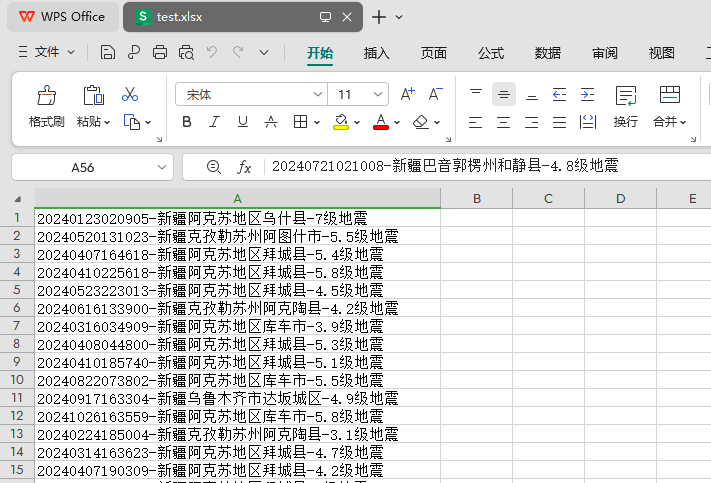
然后,运行python app.py命令,就会得到:所有我想要的文件夹
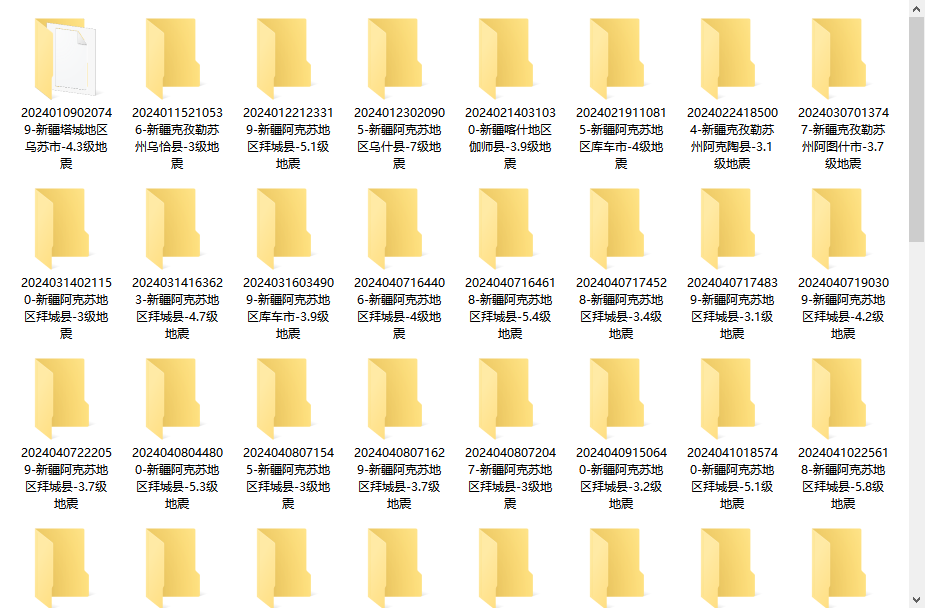
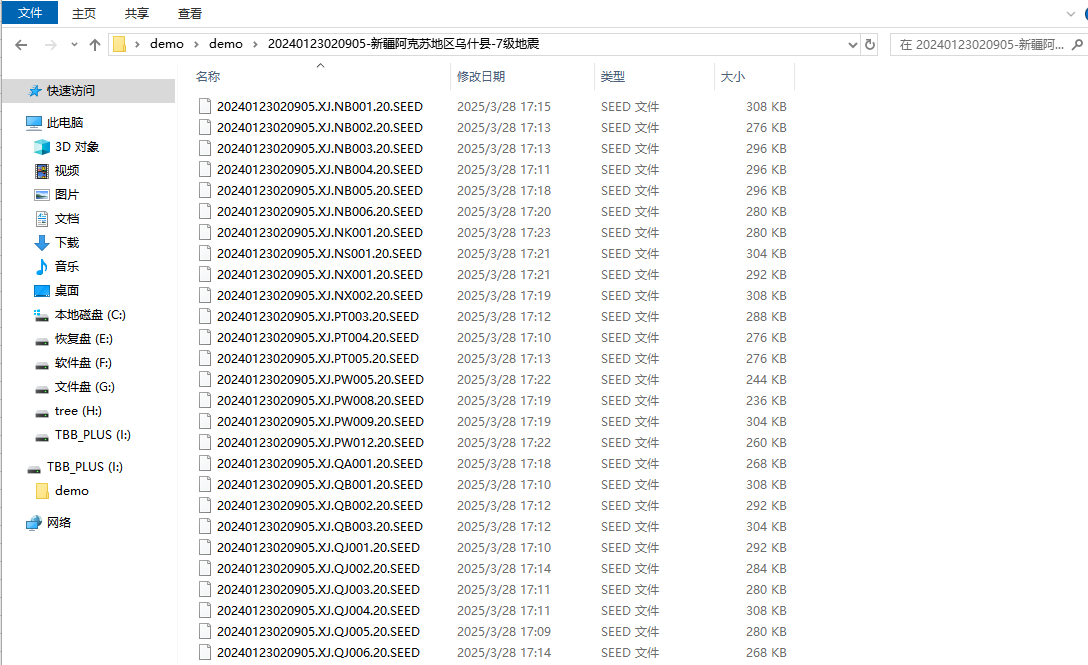
下一步,怎么把那么多的文件,放入到对应日期的文件夹呢?
这次,我们要形容的详细一点,告诉deepseek我的文件命名规则,和文件夹的命名规则,以及我们想要到达什么效果。

import os
import shutil
import re
def organize_files_by_time(source_dir):
# 创建文件夹时间戳索引字典 {时间戳: 文件夹路径}
folder_time_map = {}
# 遍历所有目录(第一级)
for item in os.listdir(source_dir):
item_path = os.path.join(source_dir, item)
# 处理文件夹(时间格式:yyyymmddHHMMSS-***)
if os.path.isdir(item_path):
# 使用正则匹配时间戳部分
match = re.match(r"^(\d{14})-.+", item)
if match:
time_str = match.group(1)
folder_time_map[time_str] = item_path
# 遍历所有文件(第一级)
for filename in os.listdir(source_dir):
file_path = os.path.join(source_dir, filename)
# 处理SEED文件(格式:yyyymmddHHMMSS.***.SEED)
if os.path.isfile(file_path) and filename.endswith(".SEED"):
# 提取时间戳部分
match = re.match(r"^(\d{14})\..+", filename)
if not match:
continue
time_str = match.group(1)
# 查找匹配的文件夹
target_folder = folder_time_map.get(time_str)
if not target_folder:
print(f"未找到匹配文件夹:{filename}")
continue
# 移动文件到目标文件夹
try:
shutil.move(file_path, os.path.join(target_folder, filename))
print(f"已移动:{filename} -> {os.path.basename(target_folder)}")
except Exception as e:
print(f"移动失败:{filename} | 错误:{str(e)}")
if __name__ == "__main__":
# 设置要处理的目录路径(当前目录)
current_directory = os.getcwd()
# 执行整理操作
organize_files_by_time(current_directory)
print("文件整理完成!")
最后,用了十分钟,我们就完成了这件事(编程小白,能摸鱼还是很快乐的 嘻嘻 (≧▽≦)/)
其实这篇博客也是在deepseek的帮助下完成的
轻松的工作(deepseek)的更多相关文章
- 使用Excel表格的记录单功能轻松处理工作表中数据的方法
使用Excel表格的记录单功能轻松处理工作表中数据的方法 记录单是将一条记录分别存储在同一行的几个单元格中,在同一列中分别存储所有记录的相似信息段.使用记录单功能可以轻松地对工作表中的数据进行查看.查 ...
- 用python处理excel文件有多轻松?工作从未如此简单
最近需要频繁读写 excel 文件,想通过程序对 excel 文件进行自动化处理,发现使用 python 的 openpyxl 库进行 excel 文件读写实在太方便了,结构清晰,操作简单.本文对 o ...
- 彻底搞懂Redis持久化机制,轻松应对工作面试
1. 为什么要持久化 Redis是基于内存存储的数据库,如果遇到服务重启或者崩溃,内存中的数据将会被清空.所以为了确保数据安全性和可靠性,我们需要将内存中的数据持久化到磁盘上. 持久化不仅可以防止由于 ...
- 学习-工作:GTD
ylbtech-学习-工作:GTD GTD就是Getting Things Done的缩写,翻译过来就是“把事情做完”,是一个管理时间的方法.GTD的核心理念概括就是必须记录下来要做的事,然后整理安排 ...
- 《Visual C++ 2010入门教程》系列五:合理组织项目、使用外部工具让工作更有效
原文:http://www.cnblogs.com/Mrt-02/archive/2011/07/24/2115631.html 这一章跟大家分享一些与c++项目管理.VAX.SVN.VS快捷键等方面 ...
- 掌握这些常用Linux命令,一起提升工作效率
开始上班了,新一年的奋斗的之路启程了,要继续[奔赴山海,奔赴热爱]. 汪国真在<热爱生命>这首诗中写到:既然选择了远方,便只顾风雨兼程.技术上还是持续精进和学习,远方虽远,要迈开脚步,一步 ...
- 干货|工作中要使用Git,看这篇文章就够了
本文将从 Git 入门到进阶.由浅入深,从常用命令.分支管理.提交规范.vim 基本操作.进阶命令.冲突预防.冲突处理等多方面展开,足以轻松应对工作中遇到的各种疑难杂症,如果觉得有所帮助,还望看官高抬 ...
- IT公司的女流之辈
声明:并不是对女性怎么怎么滴歧视, 我只是想陈述事实. 女性来IT公司工作, 真的适合吗? 如果是杰出女性也就罢了, 如果只是一般女性呢? 她能够像一般男性一样的 努力工作, 像牛马一样的工作? 在某 ...
- python框架之django
python框架之django 本节内容 web框架 mvc和mtv模式 django流程和命令 django URL django views django temple django models ...
- Django基础之安装配置
安装配置 一 MVC和MTV模式 著名的MVC模式:所谓MVC就是把web应用分为模型(M),控制器(C),视图(V)三层:他们之间以一种插件似的,松耦合的方式连接在一起. 模型负责业务对象与数据库的 ...
随机推荐
- golang1.23版本之前 Timer Reset方法无法正确使用
golang1.23版本之前 Timer Reset方法无法正确使用 golang1.23 之前 Reset 到底有什么问题 在 golang 的 time.Reset 文档中有这么一句话,为了防止 ...
- dart方法之间的调用和可选参数的使用
01==> 方法封装 void main() { //直接调用 say('好好读书,天天向上'); } say(say) { print(say); } 02==>方法之间的调用 void ...
- RoboMaster- RDK X5能量机关实现案例(一)识别
作者:SkyXZ CSDN:https://blog.csdn.net/xiongqi123123 博客园:https://www.cnblogs.com/SkyXZ 在RoboMaster的25赛季 ...
- Rocksdb原理简介
本文分享自天翼云开发者社区<Rocksdb原理简介>,作者:l****n Rocksdb作为当下nosql中性能的代表被各个存储组件(mysql.tikv.pmdk.bluestore)作 ...
- Python pika消费Rabbit MQ数据,慢消费引起的connection reset问题
问题描述 使用python pika框架,从Rabbit MQ消费数据时,遇到了connection reset的错误,错误内容如下: Traceback (most recent call last ...
- Linux安装Kafka(依赖zookeeper)
一.版本 kafka:kafka_2.12-2.4.0 zk:zookeeper-3.4.14 二.单机版安装 修改 server.properties ,支持外网访问 [1]创建日志文件夹: mkd ...
- WPF 创建自定义鼠标光标指针
WPF Cursor类中的两个构造函数: public Cursor(Stream cursorStream) public Cursor(string cursorFile) 以上的构造函数所使用的 ...
- 在python中通过模型api
前言 首先我选择的siliconflow(硅基流动)平台来调用它的api,无为啥,就是因为我点击了别人的邀请链接它送了我14块余额,那个人同样也获得14块余额 这时候,就不得不说一下我的邀请链接了ht ...
- Docker 镜像存储目录的位置修改教程
以下是在 Linux 系统中修改 Docker 镜像存储目录位置的一般步骤: 查看当前 Docker 的默认存储目录:使用docker info命令可以查看 Docker 存储驱动程序和默认存储位置, ...
- Netty - [01] 概述
题记部分 一.介绍 Netty 是由JBOSS提供的一个Java开源框架,现为Github上的独立项目. Netty是一个异步的.基于事件驱动的网络应用框架,用以快速开发高性能.高可靠性的网络I/O程 ...