kmeans算法
KMeans算法
基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。
k-means 算法基本步骤
算法分析和评价
# coding:utf-8
import numpy as np
import matplotlib.pyplot as plt def dis(x, y): #计算距离
return np.sum(np.power(y - x, 2)) def dataN(length,k):#生成数据
z=range(k)
c=[5]*length
a1= [np.sin(i*2*np.pi/k) for i in range(k)]
a2= [np.cos(i*2*np.pi/k) for i in range(k)]
x=[[[i*j + np.random.uniform(0,5)]for i in c]for j in a1]
y=[[[i*j + np.random.uniform(0,5)]for i in c]for j in a2]
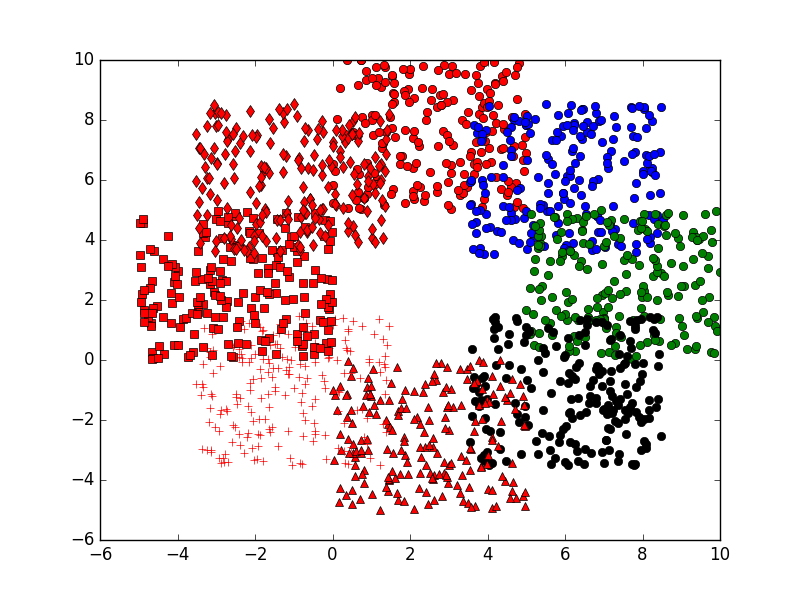
return x,y,z def showP(x,y,z):#原始点作图
plt.figure(1)
color=['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
for j in z:
for i in xrange(length):
plt.plot(x[j][i], y[j][i],color[j]) def initCentroids(dataSet, k):#初始化中心点
n, d = dataSet.shape
centroids = np.zeros((k, d))
for i in range(k):
index = int(np.random.uniform(0, n))
centroids[i] = dataSet[index]
return centroids def kmeans(dataSet, k): #kmeans算法
n = dataSet.shape[0]
clusterAssment = np.mat(np.zeros((n, 2)))
clusterChanged = True
centroids = initCentroids(dataSet, k)
while clusterChanged:
clusterChanged = False
for i in xrange(n):
distance=[[dis(centroids[j], dataSet[i])] for j in range(k)]
minDist= min(distance)
minIndex=distance.index(minDist)
if clusterAssment[i, 0] != minIndex:
clusterChanged = True
clusterAssment[i] = minIndex, minDist[0]
for j in range(k):
pointsInCluster = dataSet[np.nonzero(clusterAssment[:, 0]== j)[0]]
centroids[j] = np.mean(pointsInCluster, axis = 0)
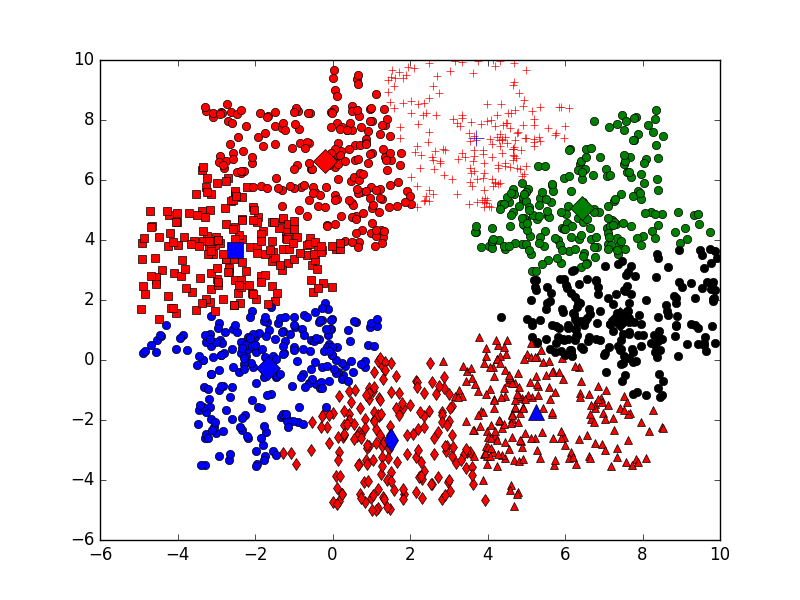
return centroids, clusterAssment def showCluster(dataSet, k, centroids, clusterAssment):#结果作图
plt.figure(2)
n=len(dataSet)
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
for i in xrange(n):
markIndex = int(clusterAssment[i, 0])
plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex])
mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', '<b', 'pb']
for i in range(k):
plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize =8)
plt.show() length=200
k=8 #k<=8
x,y,z=dataN(length,k)
showP(x,y,z) dataSet=np.mat(zip(np.reshape(x,(1,length*k))[0],np.reshape(y,(1,length*k))[0]))
centroids, clusterAssment = kmeans(dataSet, k)
showCluster(dataSet, k, centroids, clusterAssment)
kmeans算法的更多相关文章
- kmeans算法并行化的mpi程序
用c语言写了kmeans算法的串行程序,再用mpi来写并行版的,貌似参照着串行版来写并行版,效果不是很赏心悦目~ 并行化思路: 使用主从模式.由一个节点充当主节点负责数据的划分与分配,其他节点完成本地 ...
- 【原创】数据挖掘案例——ReliefF和K-means算法的医学应用
数据挖掘方法的提出,让人们有能力最终认识数据的真正价值,即蕴藏在数据中的信息和知识.数据挖掘 (DataMiriing),指的是从大型数据库或数据仓库中提取人们感兴趣的知识,这些知识是隐含的.事先未知 ...
- kmeans算法c语言实现,能对不同维度的数据进行聚类
最近在苦于思考kmeans算法的MPI并行化,花了两天的时间把该算法看懂和实现了串行版. 聚类问题就是给定一个元素集合V,其中每个元素具有d个可观察属性,使用某种算法将V划分成k个子集,要求每个子集内 ...
- kmeans算法实践
这几天学习了无监督学习聚类算法Kmeans,这是聚类中非常简单的一个算法,它的算法思想与监督学习算法KNN(K近邻算法)的理论基础一样都是利用了节点之间的距离度量,不同之处在于KNN是利用了有标签的数 ...
- 二分K-means算法
二分K-means聚类(bisecting K-means) 算法优缺点: 由于这个是K-means的改进算法,所以优缺点与之相同. 算法思想: 1.要了解这个首先应该了解K-means算法,可以看这 ...
- 视觉机器学习------K-means算法
K-means(K均值)是基于数据划分的无监督聚类算法. 一.基本原理 聚类算法可以理解为无监督的分类方法,即样本集预先不知所属类别或标签,需要根据样本之间的距离或相似程度自动进行分类.聚 ...
- EM算法(1):K-means 算法
目录 EM算法(1):K-means 算法 EM算法(2):GMM训练算法 EM算法(3):EM算法运用 EM算法(4):EM算法证明 EM算法(1) : K-means算法 1. 简介 K-mean ...
- K-means算法及文本聚类实践
K-Means是常用的聚类算法,与其他聚类算法相比,其时间复杂度低,聚类的效果也还不错,这里简单介绍一下k-means算法,下图是一个手写体数据集聚类的结果. 基本思想 k-means算法需要事先指定 ...
- K-means算法和矢量量化
语音信号的数字处理课程作业——矢量量化.这里采用了K-means算法,即假设量化种类是已知的,当然也可以采用LBG算法等,不过K-means比较简单.矢量是二维的,可以在平面上清楚的表示出来. 1. ...
- [聚类算法] K-means 算法
聚类 和 k-means简单概括. 聚类是一种 无监督学习 问题,它的目标就是基于 相似度 将相似的子集聚合在一起. k-means算法是聚类分析中使用最广泛的算法之一.它把n个对象根据它们的属性分为 ...
随机推荐
- mysql 与 oracle 比较(一)group by 容易产生的误解
注:本文并不是列举出两者之间的所有不同,而是在实际应用中发现的不同的功能点或者处理模式,之所以记录下来,就是为了提醒自己,勿忘 group by : (1)oracle 中,总所周知,select ( ...
- SVG 2D入门6 - 坐标与变换
坐标系统 SVG存在两套坐标系统:视窗坐标系与用户坐标系.默认情况下,用户坐标系与视窗坐标系的点是一一对应的,都为原点在视窗的左上角,x轴水平向右,y轴竖直向下:如下图所示: SVG的视窗位置一般是由 ...
- 2016- 1- 16 NSThread 的学习
一:NSThread的概念: 二:NSThread的使用: 1.创建一个Thread 1.1第一种方法: - (void)test1{ NSString *str = @"zhengli&q ...
- (spring-第5回【IoC基础篇】)spring容器从加载配置文件到实例化bean的内部工作机制
前面讲过,spring的生命周期为:实例化前奏-->实例化-->实例化后期-->初始化前期-->初始化-->初始化后期-->bean的具体调用-->销毁前-- ...
- BZOJ 4131 并行博弈
发现必胜态只和(1,1)的状态有关. 无法得知必胜的方法,只知道谁会必胜. #include<iostream> #include<cstdio> #include<cs ...
- 【LeetCode OJ】Pascal's Triangle II
Problem Link: http://oj.leetcode.com/problems/pascals-triangle-ii/ Let T[i][j] be the j-th element o ...
- 【LEETCODE OJ】Single Number II
Problem link: http://oj.leetcode.com/problems/single-number-ii/ The problem seems like the Single Nu ...
- css position: absolute、relative详解
CSS2.0 HandBook上的解释: 设置此属性值为 absolute 会将对象拖离出正常的文档流绝对定位而不考虑它周围内容的布局.假如其他具有不同 z-index 属性的对象已经占据了给定的位置 ...
- LeetCode Pow(x, n) (水题)
题意: 求浮点型x的n次幂结果. 思路: logN直接求,注意n可能为负数!!!当n=-2147483648的时候,千万别直接n=-n,这样的结果是多少?其他求法大同小异. class Solutio ...
- Java Super 覆盖方法
子类从父类中继承方法,有时候,子类需要修改父类中定义的方法的实现,这称作方法覆盖. 比如,GeometricObject类中的toString方法返回表示集合对象的字符串,这个方法就可以被覆盖,返回表 ...