利用Python抓取CSDN博客
这两天发现了一篇好文章,陈皓写的makefile的教程,具体地址在这里《跟我一起写makefile》
这篇文章一共分成了14个部分,我看东西又习惯在kindle上面看,感觉一篇一篇地复制成txt文本太弱了,索性就用python写了一个小爬虫,把这些文章全部都下载下来。
这个程序主要可以分成这么几块内容,获取,分析,转换。
程序的整体结构如下图所示:

get_html.py程序的功能就是实现获取功能,将下载到的原始的html文件都存放到ori_html文件夹中。ana_html.py程序实现了上面的分析和转换两个功能,通过分析原始html文件,将包含正文的div块提取出来,存放到div_html文件夹的html文件中,再利用lynx函数将这些html文本转换成txt文本,存放到text文件夹中。
第一,获取。
这一步做的事情就是把这几篇文章的html文件全部都下载下来。这个就是构造一个http请求,然后请求回来一个html页面就好了。需要注意的就是这几篇文章存放路径的编号。比如第一篇文章,它的链接是这个:http://blog.csdn.net/haoel/article/details/2886,最后编号是2886。第二篇文章的链接是这个:http://blog.csdn.net/haoel/article/details/2887。最后编号是2887。至于最后一篇文章,第14篇文章的链接是这个:http://blog.csdn.net/haoel/article/details/2899,最后的编号是2899。相信从这里大家可以看出规律来了吧,从第一篇文章到最后一篇文章,存放路径的编号依次就是从2886到2899递增。那我下载html页面的时候,其实就是只要把这个编号不断递增,就可以把所有14篇文章都给下载下来了。具体代码如下:
#!/usr/bin/env python
# -* - coding: UTF-8 -* - import httplib
from time import sleep def writeFile(html,list_num):
filename = "./ori_html/htmlfile%d.html" % list_num
file_obj = open(filename,"w")
file_obj.write(html)
file_obj.close()
print "%s文件已经写入" % filename
def getHTML(list_num):
print '准备获取%d号HTML文档成功' % list_num
url = "http://blog.csdn.net/haoel/article/details/%d" % list_num
conn = httplib.HTTPConnection("blog.csdn.net")
conn.request(method="GET",url=url)
response = conn.getresponse()
res= response.read()
print '获取%d号HTML文档成功' % list_num
writeFile(res,list_num)
def getHTMLs():
for num in range(2886,2900):
sleep(1)
getHTML(num) getHTMLs()
主函数getHTMLs通过调用getHTML来下载多个页面。每下载完一个页面,就暂停一秒钟,这是为了防止访问速度过快,让服务器认定这是攻击行为,把本机IP给屏蔽掉了。getHTML函数就是根据不同的编号,下载不同的页面,然后将下载到的页面存放到ori_html文件夹中,意思就是原始的html文件(original html)。
第二,分析
上面把所有的html文件都给下载好了,但是并不是这个页面的所有的内容都是我们想要的,我们只想要中间的正文部分,如下图所示:

在这个页面中我们只想要那个画红线的部分。
这个要具体怎么做呢,就是通过chrome分析原界面,可以看到中间的正文部分是通过一个id为article_content的div来表示的,如下图所示,

我们只要把这个div给获取出来了,那么就能得到正文内容了。
获取了这个div之后,再把它存放到一个html文件中,然后再来通过lynx命令,就能把这个篇文章下载到本地了,具体代码如下:
#!/usr/bin/env python
# -* - coding: UTF-8 -* - from bs4 import BeautifulSoup
import os def readFile(filename):
print "read the %s" % filename
file_obj = open(filename,"r")
html = file_obj.read()
file_obj.close()
return html def writeFile(html,list_num):
filename = "./div_html/div_html_%d.html" % list_num
if os.path.exists(filename):
print "%s 已经存在" % filename
return -1
file_obj = open(filename,"w")
print >> file_obj,html
print "%s已经写入" % filename def formFile(list_num):
outnum = list_num - 2886 + 1
filename = "./div_html/div_html_%d.html" % list_num
outname = "text/makefile_%d.txt" % outnum
cmd = "lynx --dump %s > %s" % (filename,outname)
os.system(cmd)
print "%s已经写入" % outname def main():
for num in range(2886,2900):
filename = "./ori_html/htmlfile%d.html" % num
if not os.path.exists(filename):
print "%s donn't exist" % filename
continue
html_doc = readFile(filename)
soup = BeautifulSoup(html_doc)
div_html = soup.find_all("div",id="article_content")
writeFile(div_html[0],num)
formFile(num) main()
在主函数中通过for循环依次遍历每个文件,readFile函数的功能就是读取html文件内的html代码存放到html_doc里面。然后再通过bs4的find_all方法,找到id为article_content的div节点。这里返回的结果是一个tag元素列表,所以底下给writeFile函数传递的参数为div_html[0],将这个tag元素传递进去。
在writeFile函数中,将传递进来的tag元素的所有内容都写入到div_html文件夹的文件中。然后再在formFile(格式化文件,format file)函数中,利用lynx命令,将这个包含正文的div转换成txt文本,写入到text文件夹的文本文件中去。
这里需要注意的一点就是writeFile函数中,将print函数打印的内容写入文件的方法直接就是print >> 文件对象名,print的参数,这样相当于做了一个数据流重定向,将本应打印到屏幕上的东西打印到文件中去了。
最后下载下来的文档如下所示:
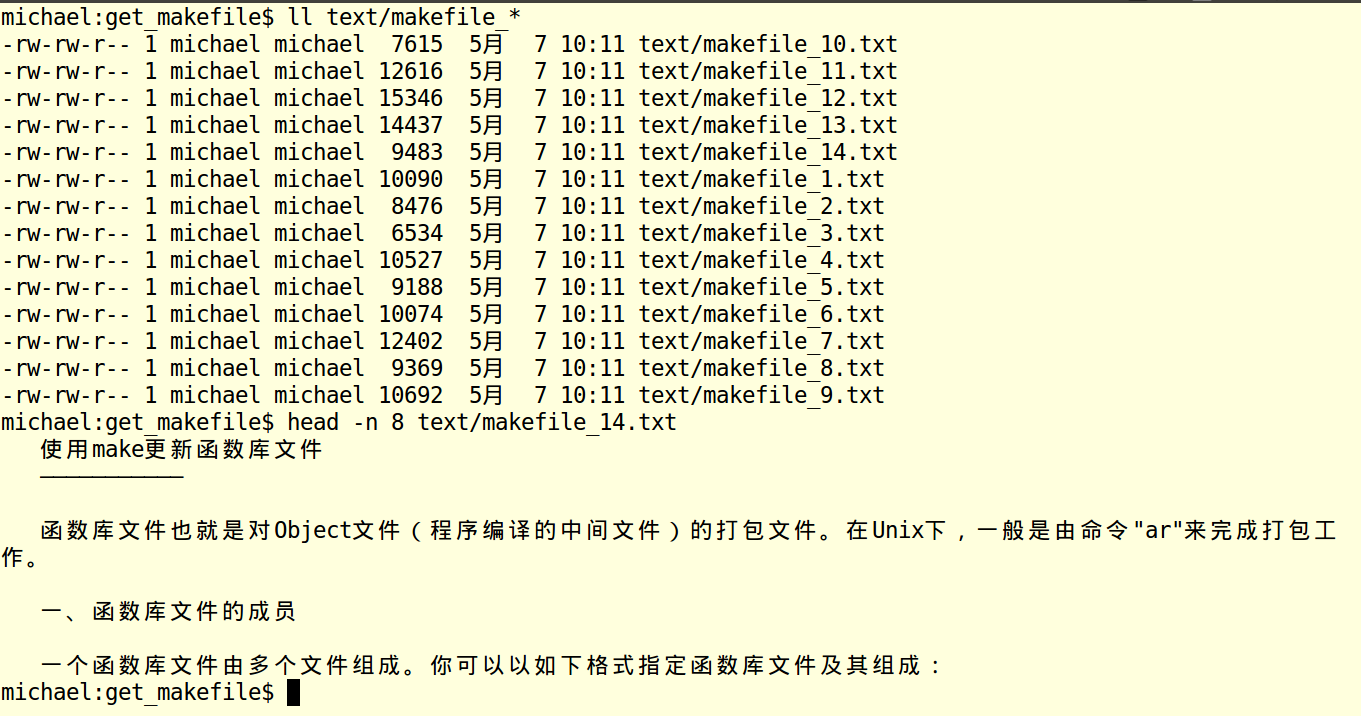
OK,就是这么多了。这个程序写的比较仓促,感觉程序中还有许多冗余的地方,欢迎各位指正!
利用Python抓取CSDN博客的更多相关文章
- python抓取51CTO博客的推荐博客的全部博文,对标题分词存入mongodb中
原文地址: python抓取51CTO博客的推荐博客的全部博文,对标题分词存入mongodb中
- Python实现抓取CSDN博客首页文章列表
1.使用工具: Python3.5 BeautifulSoup 2.抓取网站: csdn首页文章列表 http://blog.csdn.net/ 3.分析网站文章列表代码: 4.实现抓取代码: __a ...
- Python爬取CSDN博客文章
0 url :http://blog.csdn.net/youyou1543724847/article/details/52818339Redis一点基础的东西目录 1.基础底层数据结构 2.win ...
- Python 爬取CSDN博客频道
初次接触python,写的很简单,开发工具PyCharm,python 3.4很方便 python 部分模块安装时需要其他的附属模块之类的,可以先 pip install wheel 然后可以直接下载 ...
- Hello Python!用 Python 写一个抓取 CSDN 博客文章的简单爬虫
网络上一提到 Python,总会有一些不知道是黑还是粉的人大喊着:Python 是世界上最好的语言.最近利用业余时间体验了下 Python 语言,并写了个爬虫爬取我 csdn 上关注的几个大神的博客, ...
- Python爬虫抓取csdn博客
昨天晚上为了下载保存某位csdn大牛的所有博文,写了一个爬虫来自己主动抓取文章并保存到txt文本,当然也能够 保存到html网页中. 这样就能够不用Ctrl+C 和Ctrl+V了,很方便.抓取别的站点 ...
- 用python爬虫监控CSDN博客阅读量
作为一个博客新人,对自己博客的访问量也是很在意的,刚好在学python爬虫,所以正好利用一下,写一个python程序来监控博客文章访问量 效果 代码会自动爬取文章列表,并且获取标题和访问量,写入exc ...
- JAVA爬虫挖取CSDN博客文章
开门见山,看看这个教程的主要任务,就去csdn博客,挖取技术文章,我以<第一行代码–安卓>的作者为例,将他在csdn发表的额博客信息都挖取出来.因为郭神是我在大学期间比较崇拜的对象之一.他 ...
- 使用python抓取CSDN关注人的全部公布的文章
# -*- coding: utf-8 -*- """ @author: jiangfuqiang """ import re import ...
随机推荐
- php 封装mysql 数据库操作类
<?phpheader('content-type:text/html;charset=utf-8');//封装mysql 连接数据库php_mysql//封装mysql 连接数据库ph ...
- ICE安装
第一步,基于Windows下的安装,所以下载windows版的Ice: http://www.zeroc.com/download 第二步,安装Ice: 常规安装即可,可以选择安装目录,本 ...
- Spring读取配置文件
在spring中可以通过下面的方式将配置文件中的项注入到配置中 <bean class="org.springframework.beans.factory.config.Proper ...
- ubuntu 16.04 64bit安装 Julia
sudo add-apt-repository ppa:staticfloat/juliareleases sudo add-apt-repository ppa:staticfloat/julia- ...
- [FlashPlyaer] FP版本20.0.267对Win10的64位系统的不兼容问题
Win10近日推送了一个新的升级补丁KB3132372,它专门用来修复Adobe Flash Player里的安全漏洞.但是很多用户反映升级了这个补丁之后导致浏览器上网时出现崩溃.卡死.空白等现象,尤 ...
- DataTable.select() 返回 DataTable
DataTable.select() 默认返回值为 DataRow[]数组 代码来自网络: /**/ /// <summary> /// 执行DataTable中的查询返回新的DataTa ...
- 给a标签herf属性赋值时,必须加http://
新建一个web工程,FirstWeb,在其中新建一个页面:test.jsp <%@ page language="java" contentType="text/h ...
- C#中修改Dll文件 (反编译后重新编译)
Dll文件生成后,如没有源代码,又要修改其中内容 可以用微软自带的ildasm和ilasm程序 先用ildasm将dll文件反编译成il文件 ildasm Test.dll /out=Test.il ...
- Delphi Alpha皮肤控件使用方法
//用于刷新控件颜色. FsSkinManager.BeginUpdate; FsSkinManager.EndUpdate(True); //动态选择皮肤 begin if not FIsswitc ...
- Golang 开发移动应用的OpenGL(Android为例)的渲染管线
golang.org/x/mobile/gl 实现的是 OpenGL ES 2 的封装. 参考:https://godoc.org/golang.org/x/mobile/gl OpenGL ES(O ...