Stream Processing for Everyone with SQL and Apache Flink
Where did we come from?
With the 0.9.0-milestone1 release, Apache Flink added an API to process relational data with SQL-like expressions called the Table API. The central concept of this API is a Table, a structured data set or stream on which relational operations can be applied. The Table API is tightly integrated with the DataSet and DataStream API. A Table can be easily created from a DataSet or DataStream and can also be converted back into a DataSet or DataStream as the following example shows
从0.9开始,引入Table API来支持关系型操作,
val execEnv = ExecutionEnvironment.getExecutionEnvironment
val tableEnv = TableEnvironment.getTableEnvironment(execEnv) // obtain a DataSet from somewhere
val tempData: DataSet[(String, Long, Double)] = // convert the DataSet to a Table
val tempTable: Table = tempData.toTable(tableEnv, 'location, 'time, 'tempF)
// compute your result
val avgTempCTable: Table = tempTable
.where('location.like("room%"))
.select(
('time / (3600 * 24)) as 'day,
'Location as 'room,
(('tempF - 32) * 0.556) as 'tempC
)
.groupBy('day, 'room)
.select('day, 'room, 'tempC.avg as 'avgTempC)
// convert result Table back into a DataSet and print it
avgTempCTable.toDataSet[Row].print()
可以看到可以很简单的把dataset转换为Table,指定其元数据即可
然后对于table就可以进行各种关系型操作,
最后还可以把Table再转换回dataset
Although the example shows Scala code, there is also an equivalent Java version of the Table API. The following picture depicts the original architecture of the Table API.
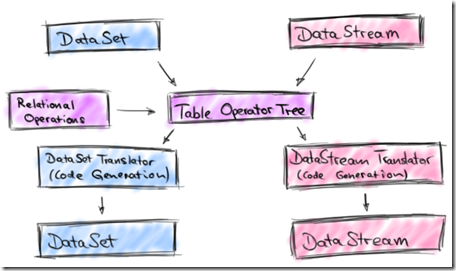
对于table的关系型操作,最终通过code generation还是会转换为dataset的逻辑
Table API joining forces with SQL
the community was also well aware of the multitude of dedicated “SQL-on-Hadoop” solutions in the open source landscape (Apache Hive, Apache Drill,Apache Impala, Apache Tajo, just to name a few).
Given these alternatives, we figured that time would be better spent improving Flink in other ways than implementing yet another SQL-on-Hadoop solution.
What we came up with was a revised architecture for a Table API that supports SQL (and Table API) queries on streaming and static data sources.
We did not want to reinvent the wheel and decided to build the new Table API on top of Apache Calcite, a popular SQL parser and optimizer framework. Apache Calcite is used by many projects including Apache Hive, Apache Drill, Cascading, and many more. Moreover, the Calcite community put SQL on streams on their roadmap which makes it a perfect fit for Flink’s SQL interface.
虽然社区已经有很多的Sql-on-Hadoop方案,flink希望把时间花在更有价值的地方,而不是再实现一套
但是当前这样的需要非常强烈,所以在revise Table API的基础上实现对SQL的支持
对于SQL的支持,借助于Calcite,并且Calcite已经把SQL on streams放在roadmap上,有希望成为streaming sql的标准
Calcite is central in the new design as the following architecture sketch shows:
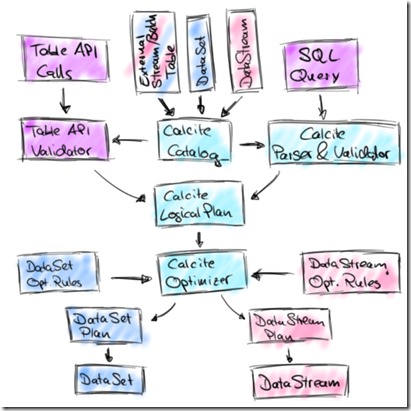
The new architecture features two integrated APIs to specify relational queries, the Table API and SQL.
Queries of both APIs are validated against a catalog of registered tables and converted into Calcite’s representation for logical plans.
In this representation, stream and batch queries look exactly the same.
Next, Calcite’s cost-based optimizer applies transformation rules and optimizes the logical plans.
Depending on the nature of the sources (streaming or static) we use different rule sets.
Finally, the optimized plan is translated into a regular Flink DataStream or DataSet program. This step involves again code generation to compile relational expressions into Flink functions.
这里Table API和SQL都统一的转换为Calcite的逻辑plans,然后再通过Calcite Optimizer进行优化,最终通过code generation转换为Flink的函数
With this effort, we are adding SQL support for both streaming and static data to Flink.
However, we do not want to see this as a competing solution to dedicated, high-performance SQL-on-Hadoop solutions, such as Impala, Drill, and Hive.
Instead, we see the sweet spot of Flink’s SQL integration primarily in providing access to streaming analytics to a wider audience.
In addition, it will facilitate integrated applications that use Flink’s API’s as well as SQL while being executed on a single runtime engine
再次说明,支持SQL并不是为了再造一个专用的SQL-on-Hadoop solutions;而是为了让更多的人可以来使用Flink,说白了,这块不是当前的战略重点
How will Flink’s SQL on streams look like?
So far we discussed the motivation for and architecture of Flink’s stream SQL interface, but how will it actually look like?
// get environments
val execEnv = StreamExecutionEnvironment.getExecutionEnvironment
val tableEnv = TableEnvironment.getTableEnvironment(execEnv) // configure Kafka connection
val kafkaProps = ...
// define a JSON encoded Kafka topic as external table
val sensorSource = new KafkaJsonSource[(String, Long, Double)](
"sensorTopic",
kafkaProps,
("location", "time", "tempF")) // register external table
tableEnv.registerTableSource("sensorData", sensorSource) // define query in external table
val roomSensors: Table = tableEnv.sql(
"SELECT STREAM time, location AS room, (tempF - 32) * 0.556 AS tempC " +
"FROM sensorData " +
"WHERE location LIKE 'room%'"
) // define a JSON encoded Kafka topic as external sink
val roomSensorSink = new KafkaJsonSink(...) // define sink for room sensor data and execute query
roomSensors.toSink(roomSensorSink)
execEnv.execute()
跟Table API相比,可以通过纯粹的SQL来做相应的操作
当前SQL不支持,windows aggregation,
但是Calcite的Streaming SQL是支持的,比如,
SELECT STREAM
TUMBLE_END(time, INTERVAL '1' DAY) AS day,
location AS room,
AVG((tempF - 32) * 0.556) AS avgTempC
FROM sensorData
WHERE location LIKE 'room%'
GROUP BY TUMBLE(time, INTERVAL '1' DAY), location
可以用Table API实现,
val avgRoomTemp: Table = tableEnv.ingest("sensorData")
.where('location.like("room%"))
.partitionBy('location)
.window(Tumbling every Days(1) on 'time as 'w)
.select('w.end, 'location, , (('tempF - 32) * 0.556).avg as 'avgTempCs)
What’s up next?
The Flink community is actively working on SQL support for the next minor version Flink 1.1.0. In the first version, SQL (and Table API) queries on streams will be limited to selection, filter, and union operators. Compared to Flink 1.0.0, the revised Table API will support many more scalar functions and be able to read tables from external sources and write them back to external sinks. A lot of work went into reworking the architecture of the Table API and integrating Apache Calcite.
In Flink 1.2.0, the feature set of SQL on streams will be significantly extended. Among other things, we plan to support different types of window aggregates and maybe also streaming joins. For this effort, we want to closely collaborate with the Apache Calcite community and help extending Calcite’s support for relational operations on streaming data when necessary.
1.2会有window aggregates和streaming joins,值得期待。。。
Stream Processing for Everyone with SQL and Apache Flink的更多相关文章
- Building real-time dashboard applications with Apache Flink, Elasticsearch, and Kibana
https://www.elastic.co/cn/blog/building-real-time-dashboard-applications-with-apache-flink-elasticse ...
- Apache Flink 为什么能够成为新一代大数据计算引擎?
众所周知,Apache Flink(以下简称 Flink)最早诞生于欧洲,2014 年由其创始团队捐赠给 Apache 基金会.如同其他诞生之初的项目,它新鲜,它开源,它适应了快速转的世界中更重视的速 ...
- 腾讯大数据平台Oceanus: A one-stop platform for real time stream processing powered by Apache Flink
January 25, 2019Use Cases, Apache Flink The Big Data Team at Tencent In recent years, the increa ...
- Stream Processing 101: From SQL to Streaming SQL in 10 Minutes
转自:https://wso2.com/library/articles/2018/02/stream-processing-101-from-sql-to-streaming-sql-in-ten- ...
- Stream processing with Apache Flink and Minio
转自:https://blog.minio.io/stream-processing-with-apache-flink-and-minio-10da85590787 Modern technolog ...
- Apache Samza - Reliable Stream Processing atop Apache Kafka and Hadoop YARN
http://engineering.linkedin.com/data-streams/apache-samza-linkedins-real-time-stream-processing-fram ...
- 13 Stream Processing Patterns for building Streaming and Realtime Applications
原文:https://iwringer.wordpress.com/2015/08/03/patterns-for-streaming-realtime-analytics/ Introduction ...
- Introducing KSQL: Streaming SQL for Apache Kafka
Update: KSQL is now available as a component of the Confluent Platform. I’m really excited to announ ...
- Storm(2) - Log Stream Processing
Introduction This chapter will present an implementation recipe for an enterprise log storage and a ...
随机推荐
- 不同java 版本的新功能
Java 5 泛型 自动装箱/拆箱 增强的for 类型安全的枚举 可变参数 静态导入 Annotation Concurrent Package Java 6 Web Service 支持Annota ...
- HDU4871 Shortest-path tree(最短路径树 + 树的点分治)
题目大概要先求一张边有权的图的根为1的最短路径树,要满足根到各点路径序列的字典序最小:然后求这棵最短路径树包含k个结点的最长路径的长度和个数. 首先先构造出这棵字典序最小的最短路径树..好吧,我太傻逼 ...
- Java类加载
类的生命周期是: 在一个类编译完成之后,下一步就需要开始使用类,如果要使用一个类,肯定离不开JVM.在程序执行中JVM通过装载,链接,初始化这3个步骤完成. 类的装载是通过类加载器完成的,加载器将.c ...
- [转]linux(centos)搭建SVN服务器
转自:http://blog.163.com/longsu2010@yeah/blog/static/173612348201202114212933/ 安装步骤如下: 1.yum install ...
- Codeforces Round #253 (Div. 2) D. Andrey and Problem
关于证明可以参考题解http://codeforces.com/blog/entry/12739 就是将概率从大到小排序然后,然后从大到小计算概率 #include <iostream> ...
- ACM Same binary weight
Same binary weight 时间限制:300 ms | 内存限制:65535 KB 难度:3 描述 The binary weight of a positive integer ...
- ACM 笨小熊
笨小熊 时间限制:2000 ms | 内存限制:65535 KB 难度:2 描述 笨小熊的词汇量很小,所以每次做英语选择题的时候都很头疼.但是他找到了一种方法,经试验证明,用这种方法去选择选项 ...
- 2001. Counting Sheep
After a long night of coding, Charles Pearson Peterson is having trouble sleeping. This is not onl ...
- Codeforces Beta Round #3
A题,水题,还是无法1Y. B题,题意是类似背包的问题,在v的容量下,有1重量和2重量的,如果达到价值最大. 贪心,写的很恶心.看着数据过了. 奇数的时候,先选一个1.之后然后1+1 和 2 比较就行 ...
- 【BZOJ2818】Gcd 欧拉筛
Description 给定整数N,求1<=x,y<=N且Gcd(x,y)为素数的数对(x,y)有多少对. Input 一个整数N Output 如题 Sample Input 4 Sam ...