CutMix&Mixup详解与代码实战
摘要:本文将通过实践案例带大家掌握CutMix&Mixup。
本文分享自华为云社区《CutMix&Mixup详解与代码实战》,作者:李长安。
引言
最近在回顾之前学到的知识,看到了数据增强部分,对于CutMix以及Mixup这两种数据增强方式发现理解不是很到位,所以这里写了一个项目再去好好看这两种数据增强方式。最开始在目标检测中,未对数据的标签部分进行思考,对于图像的处理,大家是可以很好理解的,因为非常直观,但是通过阅读相关论文,查看一些相关的资料发现一些新的有趣的东西。接下来为大家讲解一下这两种数据增强方式。下图从左至右分别为原图、mixup、cutout、cutmix。

Mixup离线实现
Mixup相信大家有了很多了解,并且大家也能发现网络上有很多大神的解答,所以我这里就不在进行详细讲解了。
- Mixup核心思想:两张图片采用比例混合,label也需要按照比例混合

- 论文关键点
- 考虑过三个或者三个以上的标签做混合,但是效果几乎和两个一样,而且增加了mixup过程的时间。
- 当前的mixup使用了一个单一的loader获取minibatch,对其随机打乱后,mixup对同一个minibatch内的数据做混合。这样的策略和在整个数据集随机打乱效果是一样的,而且还减少了IO的开销。
- 在同种标签的数据中使用mixup不会造成结果的显著增强
下面的Cell为Mixup的图像效果展示,具体实现请参考下面的在线实现。
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.image as Image
import numpy as np
im1 = Image.imread("work/data/10img11.jpg")
im1 = im1/255.
im2 = Image.imread("work/data/14img01.jpg")
im2 = im2/255.
for i in range(1,10):
lam= i*0.1
im_mixup = (im1*lam+im2*(1-lam))
plt.subplot(3,3,i)
plt.imshow(im_mixup)
plt.show()
CutMix离线实现
简单来说cutmix相当于cutout+mixup的结合,可以应用于各种任务中。
mixup相当于是全图融合,cutout仅仅对图片进行增强,不改变label,而cutmix则是采用了cutout的局部融合思想,并且采用了mixup的混合label策略,看起来比较make sense。
- cutmix和mixup的区别是: 其混合位置是采用hard 0-1掩码,而不是soft操作,相当于新合成的两张图是来自两张图片的hard结合,而不是Mixup的线性组合。但是其label还是和mixup一样是线性组合。
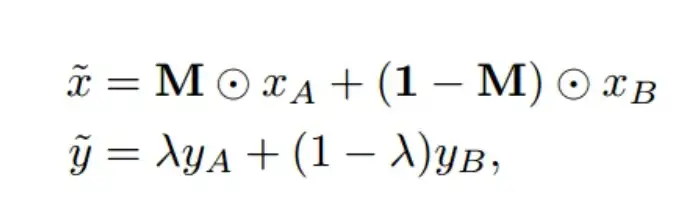
下面的代码为了消除随机性,对cut的位置进行了固定,主要是为了展示效果。代码更改位置如下所示,注释的部分为大家通用的实现。
# bbx1 = np.clip(cx - cut_w // 2, 0, W)
# bby1 = np.clip(cy - cut_h // 2, 0, H)
# bbx2 = np.clip(cx + cut_w // 2, 0, W)
# bby2 = np.clip(cy + cut_h // 2, 0, H)
bbx1 = 10
bby1 = 600
bbx2 = 10
bby2 = 600
%matplotlib inline
import glob
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [10,10]
import cv2
# Path to data
data_folder = f"/home/aistudio/work/data/"
# Read filenames in the data folder
filenames = glob.glob(f"{data_folder}*.jpg")
# Read first 10 filenames
image_paths = filenames[:4]
image_batch = []
image_batch_labels = []
n_images = 4
print(image_paths)
for i in range(4):
image = cv2.cvtColor(cv2.imread(image_paths[i]), cv2.COLOR_BGR2RGB)
image_batch.append(image)
image_batch_labels=np.array([[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]])
def rand_bbox(size, lamb):
W = size[0]
H = size[1]
cut_rat = np.sqrt(1. - lamb)
cut_w = np.int(W * cut_rat)
cut_h = np.int(H * cut_rat)
# uniform
cx = np.random.randint(W)
cy = np.random.randint(H)
# bbx1 = np.clip(cx - cut_w // 2, 0, W)
# bby1 = np.clip(cy - cut_h // 2, 0, H)
# bbx2 = np.clip(cx + cut_w // 2, 0, W)
# bby2 = np.clip(cy + cut_h // 2, 0, H)
bbx1 = 10
bby1 = 600
bbx2 = 10
bby2 = 600
return bbx1, bby1, bbx2, bby2
image = cv2.cvtColor(cv2.imread(image_paths[0]), cv2.COLOR_BGR2RGB)
# Crop a random bounding box
lamb = 0.3
size = image.shape
print('size',size)
def generate_cutmix_image(image_batch, image_batch_labels, beta):
c=[1,0,3,2]
# generate mixed sample
lam = np.random.beta(beta, beta)
rand_index = np.random.permutation(len(image_batch))
print(f'iamhere{rand_index}')
target_a = image_batch_labels
target_b = np.array(image_batch_labels)[c]
print('img.shape',image_batch[0].shape)
bbx1, bby1, bbx2, bby2 = rand_bbox(image_batch[0].shape, lam)
print('bbx1',bbx1)
print('bby1',bby1)
print('bbx2',bbx2)
print('bby2',bby2)
image_batch_updated = image_batch.copy()
image_batch_updated=np.array(image_batch_updated)
image_batch=np.array(image_batch)
image_batch_updated[:, bbx1:bby1, bbx2:bby2, :] = image_batch[[c], bbx1:bby1, bbx2:bby2, :]
# adjust lambda to exactly match pixel ratio
lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (image_batch.shape[1] * image_batch.shape[2]))
print(f'lam is {lam}')
label = target_a * lam + target_b * (1. - lam)
return image_batch_updated, label
# Generate CutMix image
input_image = image_batch[0]
image_batch_updated, image_batch_labels_updated = generate_cutmix_image(image_batch, image_batch_labels, 1.0)
# Show original images
print("Original Images")
for i in range(2):
for j in range(2):
plt.subplot(2,2,2*i+j+1)
plt.imshow(image_batch[2*i+j])
plt.show()
# Show CutMix images
print("CutMix Images")
for i in range(2):
for j in range(2):
plt.subplot(2,2,2*i+j+1)
plt.imshow(image_batch_updated[2*i+j])
plt.show()
# Print labels
print('Original labels:')
print(image_batch_labels)
print('Updated labels')
print(image_batch_labels_updated)
['/home/aistudio/work/data/11img01.jpg', '/home/aistudio/work/data/10img11.jpg', '/home/aistudio/work/data/14img01.jpg', '/home/aistudio/work/data/12img11.jpg']
size (2016, 1512, 3)
iamhere[2 1 0 3]
img.shape (2016, 1512, 3)
bbx1 10
bby1 600
bbx2 10
bby2 600
lam is 1.0
Original Images

CutMix Images

Original labels:
[[1 0 0 0]
[0 1 0 0]
[0 0 1 0]
[0 0 0 1]]
Updated labels
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]
Mixup&CutMix在线实现
大家需要注意的是,通常我们在实际的使用中都是使用在线的方式进行数据增强,也就是本小节所讲的方法,所以大家在实际的使用中可以使用下面的代码。mixup实现原理同cutmix相差不多,大家可以根据我下面的的代码更改一下即可。
!cd 'data/data97595' && unzip -q nongzuowu.zip
from paddle.io import Dataset
import cv2
import paddle
import random
# 导入所需要的库
from sklearn.utils import shuffle
import os
import pandas as pd
import numpy as np
from PIL import Image
import paddle
import paddle.nn as nn
from paddle.io import Dataset
import paddle.vision.transforms as T
import paddle.nn.functional as F
from paddle.metric import Accuracy
import warnings
warnings.filterwarnings("ignore")
# 读取数据
train_images = pd.read_csv('data/data97595/nongzuowu/train.csv')
# 划分训练集和校验集
all_size = len(train_images)
# print(all_size)
train_size = int(all_size * 0.8)
train_df = train_images[:train_size]
val_df = train_images[train_size:]
# CutMix 的切块功能
def rand_bbox(size, lam):
if len(size) == 4:
W = size[2]
H = size[3]
elif len(size) == 3:
W = size[0]
H = size[1]
else:
raise Exception
cut_rat = np.sqrt(1. - lam)
cut_w = np.int(W * cut_rat)
cut_h = np.int(H * cut_rat)
# uniform
cx = np.random.randint(W)
cy = np.random.randint(H)
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
return bbx1, bby1, bbx2, bby2
# 定义数据预处理
data_transforms = T.Compose([
T.Resize(size=(256, 256)),
T.Transpose(), # HWC -> CHW
T.Normalize(
mean=[0, 0, 0], # 归一化
std=[255, 255, 255],
to_rgb=True)
])
class JSHDataset(Dataset):
def __init__(self, df, transforms, train=False):
self.df = df
self.transfoms = transforms
self.train = train
def __getitem__(self, idx):
row = self.df.iloc[idx]
fn = row.image
# 读取图片数据
image = cv2.imread(os.path.join('data/data97595/nongzuowu/train', fn))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (256, 256), interpolation=cv2.INTER_LINEAR)
# 读取 mask 数据
# masks = cv2.imread(os.path.join(row['mask_path'], fn), cv2.IMREAD_GRAYSCALE)/255
# masks = cv2.resize(masks, (1024, 1024), interpolation=cv2.INTER_LINEAR)
# 读取 label
label = paddle.zeros([4])
label[row.label] = 1
# ------------------------------ CutMix ------------------------------------------
prob = 20 # 将 prob 设置为 0 即可关闭 CutMix
if random.randint(0, 99) < prob and self.train:
rand_index = random.randint(0, len(self.df) - 1)
rand_row = self.df.iloc[rand_index]
rand_fn = rand_row.image
rand_image = cv2.imread(os.path.join('data/data97595/nongzuowu/train', rand_fn))
rand_image = cv2.cvtColor(rand_image, cv2.COLOR_BGR2RGB)
rand_image = cv2.resize(rand_image, (256, 256), interpolation=cv2.INTER_LINEAR)
# rand_masks = cv2.imread(os.path.join(rand_row['mask_path'], rand_fn), cv2.IMREAD_GRAYSCALE)/255
# rand_masks = cv2.resize(rand_masks, (1024, 1024), interpolation=cv2.INTER_LINEAR)
lam = np.random.beta(1,1)
bbx1, bby1, bbx2, bby2 = rand_bbox(image.shape, lam)
image[bbx1:bbx2, bby1:bby2, :] = rand_image[bbx1:bbx2, bby1:bby2, :]
# masks[bbx1:bbx2, bby1:bby2] = rand_masks[bbx1:bbx2, bby1:bby2]
lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (image.shape[1] * image.shape[0]))
rand_label = paddle.zeros([4])
rand_label[rand_row.label] = 1
label = label * lam + rand_label * (1. - lam)
# --------------------------------- CutMix ---------------------------------------
# 应用之前我们定义的各种数据增广
# augmented = self.transforms(image=image, mask=masks)
# img, mask = augmented['image'], augmented['mask']
img = image
return self.transfoms(img), label
def __len__(self):
return len(self.df)
train_dataset = JSHDataset(train_df, data_transforms, train=True)
val_dataset = JSHDataset(val_df, data_transforms)
#train_loader
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=8, shuffle=True, num_workers=0)
#val_loader
val_loader = paddle.io.DataLoader(val_dataset, places=paddle.CPUPlace(), batch_size=8, shuffle=True, num_workers=0)
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1]
print(x_data.dtype)
print(y_data)
break
paddle.float32
Tensor(shape=[8, 4], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[[0. , 0. , 1. , 0. ],
[0.54284668, 0.45715332, 0. , 0. ],
[0. , 1. , 0. , 0. ],
[0. , 0. , 1. , 0. ],
[0.32958984, 0. , 0.67041016, 0. ],
[0. , 0. , 0. , 1. ],
[0. , 0. , 0. , 1. ],
[0. , 0. , 0. , 1. ]])
from paddle.vision.models import resnet18
model = resnet18(num_classes=4)
# 模型封装
model = paddle.Model(model)
# 定义优化器
optim = paddle.optimizer.Adam(learning_rate=3e-4, parameters=model.parameters())
# 配置模型
model.prepare(
optim,
paddle.nn.CrossEntropyLoss(soft_label=True),
Accuracy()
)
# 模型训练与评估
model.fit(train_loader,
val_loader,
log_freq=1,
epochs=2,
verbose=1,
)
The loss value printed in the log is the current step, and the metric is the average value of previous steps.
Epoch 1/2
step 56/56 [==============================] - loss: 1.2033 - acc: 0.5843 - 96ms/step
Eval begin...
step 14/14 [==============================] - loss: 1.6905 - acc: 0.5625 - 73ms/step
Eval samples: 112
Epoch 2/2
step 56/56 [==============================] - loss: 0.5297 - acc: 0.7708 - 82ms/step
Eval begin...
step 14/14 [==============================] - loss: 0.5764 - acc: 0.7857 - 67ms/step
Eval samples: 112
总结
在CutMix中,用另一幅图像的一部分以及第二幅图像的ground truth标记替换该切块。在图像生成过程中设置每个图像的比例(例如0.4/0.6)。在下面的图片中,你可以看到CutMix的作者是如何演示这种技术比简单的MixUp和Cutout效果更好。
ps:神经网络热力图生成可以参考我另一个项目。

这两种数据增强方式能够很好地代表了目前数据增强的一些方法,比如cutout、mosaic等方法,掌握了这两种方法,大家也就理解了另外的cutout以及mosaic增强方法。
CutMix&Mixup详解与代码实战的更多相关文章
- net core 中间件详解及项目实战
net core 中间件详解及项目实战 前言 在上篇文章主要介绍了DotNetCore项目状况,本篇文章是我们在开发自己的项目中实际使用的,比较贴合实际应用,算是对中间件的一个深入使用了,不是简单的H ...
- Git详解之一 Git实战
Git详解之一 Git实战 入门 本章介绍开始使用 Git 前的相关知识.我们会先了解一些版本控制工具的历史背景,然后试着让 Git 在你的系统上跑起来,直到最后配置好,可以正常开始开发工作.读完本章 ...
- Spark详解(05-1) - SparkCore实战案例
Spark详解(05-1) - SparkCore实战案例 数据准备 1)数据格式 本项目的数据是采集电商网站的用户行为数据,主要包含用户的4种行为:搜索.点击.下单和支付. (1)数据采用_分割字段 ...
- 3.awk数组详解及企业实战案例
awk数组详解及企业实战案例 3.打印数组: [root@nfs-server test]# awk 'BEGIN{array[1]="zhurui";array[2]=" ...
- Python - 元组(tuple) 详解 及 代码
元组(tuple) 详解 及 代码 本文地址: http://blog.csdn.net/caroline_wendy/article/details/17290967 元组是存放任意元素集合,不能修 ...
- Python - 字典(dict) 详解 及 代码
字典(dict) 详解 及 代码 本文地址: http://blog.csdn.net/caroline_wendy/article/details/17291329 字典(dict)是表示映射的数据 ...
- 深度学习之卷积神经网络(CNN)详解与代码实现(一)
卷积神经网络(CNN)详解与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10430073.html 目 ...
- C#的String.Split 分割字符串用法详解的代码
代码期间,把代码过程经常用的内容做个珍藏,下边代码是关于C#的String.Split 分割字符串用法详解的代码,应该对码农们有些用途. 1) public string[] Split(params ...
- (转)awk数组详解及企业实战案例
awk数组详解及企业实战案例 原文:http://www.cnblogs.com/hackerer/p/5365967.html#_label03.打印数组:1. [root@nfs-server t ...
- laravel 框架配置404等异常页面的方法详解(代码示例)
本篇文章给大家带来的内容是关于laravel 框架配置404等异常页面的方法详解(代码示例),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助. 在Laravel中所有的异常都由Handl ...
随机推荐
- 基于ZXing.NET实现的二维码生成和识别客户端
一.前言 ZXing.Net的一个可移植软件包,是一个开源的.多格式的1D/2D条形码图像处理库,最初是用Java实现的.已经过大量优化和改进,它已经被手动移植.它与.Net 2.0..Net 3.5 ...
- Amazon MSK 可靠性最佳实践
1. Amazon MSK介绍 Kafka作为老牌的开源分布式事件流平台,已经广泛用于如数据集成,流处理,数据管道等各种应用中. 亚马逊云科技也于2019年2月推出了Apache Kafka的云托管版 ...
- 轻巧的批量图片压缩工具imgfast
现在的手机拍照动辄2M3M,还有7M8m的,如果要把这些文件上传到网上应用,浪费网络,占用资源 所以2022年中秋写了这个小工具,可以批量进行图片文件压缩,支持jpg和png. 文件下载链接https ...
- 当scroll-view水平滚动,内容溢出时,文本会自动竖向排列问题
当scroll-view水平滚动,内容溢出时,文本会自动竖向排列 解决方法:thite-space:nowrap:规定段落中的文本不进行换行
- [最优化DP]决策单调性
决策单调性的概念&证明工具: 决策单调性,是在最优化dp中的可能出现的一种性质,利用它我们可以降低转移的复杂度. 首先dp中会有转移,每个状态都由若干个状态转移而来,最优化dp比较特殊,只能由 ...
- VS Code C# 开发工具包正式发布
前言 微软于本月正式发布Visual Studio Code C#开发工具包,此前该开发套件已经以预览版的形式在6月份问世.经过4个月的测试和调整,微软修复了350多个问题,其中大部分是用户反馈导致的 ...
- python实现汉诺塔的图解递归算法
写在前面 工作闲来无事,看了python,写了一个汉诺塔. 还是蛮喜欢python这门语言的,很简洁. 正文 一.起源: 汉诺塔(又称河内塔)问题是源于印度一个古老传说的益智玩具.大梵天创造世界的时候 ...
- 彻底搞懂CAP理论(电商系统)
1.理解CAP CAP是 Consistency.Availability.Partition tolerance三个词语的缩写,分别表示一致性.可用性.分区容忍性. 下边我们分别来解释: 为了方便对 ...
- [Python急救站]草莓熊的绘制
草莓熊也是一个热门的图案,今天就用Python绘制一下 import turtle as t # 设置背景颜色,窗口位置以及大小 t.colormode(255) # 颜色模式 t.speed(0) ...
- 解决报错Invalid bound statement (not found)
解决报错Invalid bound statement (not found) 问题描述: 在玩mybatis-plus的时候,在测试类写了一个测试批量插入的方法,结果就报错: 它的意思是 无效的跳转 ...