机器学习-线性分类-支持向量机SVM-SMO算法-14
1. SVM算法总结
选择 核函数 以及对应的 超参数
为什么要选择核函数?
升维 将线性问题不可分问题 升维后转化成 线性可分的问题
核函数 有那些? linea gauss polinormail tanh选择惩罚项系数C
min ||w||2 + Csum(ei)构造优化问题:
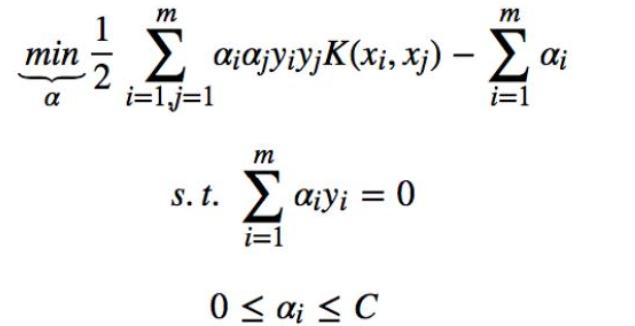
利用SMO算法 计算 α*
根据α* 计算w*
根据α* 得到支撑向量 计算每个支撑向量 对应的bs*
bs* 求平均得到b*
学得超平面: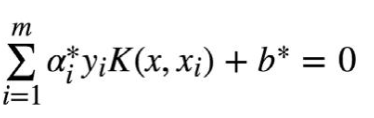
仔细观察这个式子就会发现:
其实只需要关注 支撑向量的C>α>0 非支撑向量的alpha为0
W*的计算:
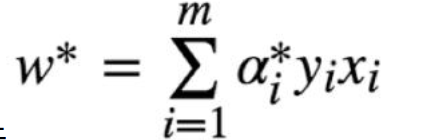
其实也就只需要关注 是支撑向量的几个点,支撑向量对于W,b的求解起关键作用,其他的非支撑向量,对模型没起任何作用
- 得到最终的判别式

神奇的SMO算法到底是如何进行的?
2. SMO算法
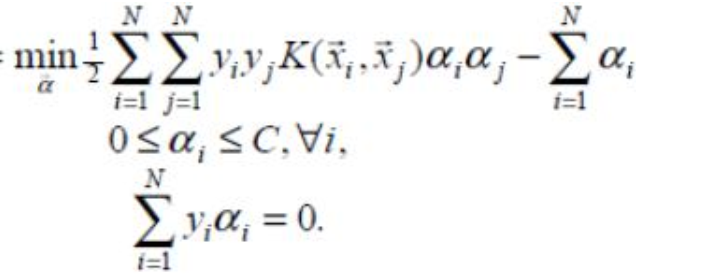
其中(xi,yi)表示训练样本数据,xi 为样本特征,yi∈{−1,1}为样本标签,C 为惩罚系数由自己设定。上述问题是要求解 N 个参数(α1,α2,α3,...,αN),其他参数均为已知
把原始求解 N 个参数二次规划问题分解成很多个子二次规划问题分别求解,每个子问题只需要求解 2 个参数,方法类似于坐标上升,节省时间成本和降低了内存需求。每次启发式选择两个变量进行优化,不断循环,直到达到函数最优值。
同时优化两个参数,固定其他 N-2 个参数,假设选择的变量为α1,α2,
固定其他参数α3,α4,...,αN,由于参数α3,α4,...,αN 的固定, 可以简化目标函数为只关于α1,α2的二元函数,Constant 表示常数项(不包含变量α1,α2 的项)。
v1 表示 x1 与 3---N 之后所有的样本运算
v2 表示 x2 与 3---N 之后所有的样本运算
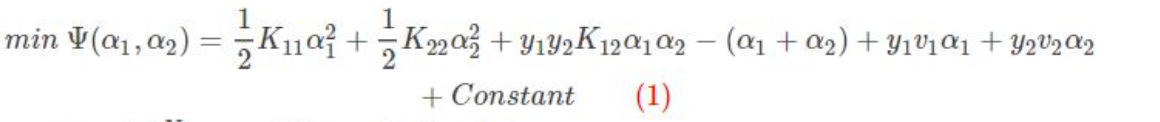
其中:

Kij表示 xi 与 xj 输入到核函数 进行运算的结果
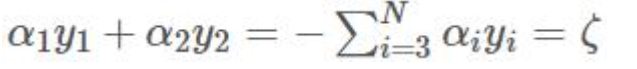
两边同时乘以 y1, 任意的y*2 = 1
得到:
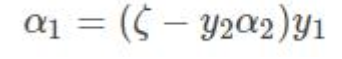
需要优化的目标函数转化成:

上式中是关于变量α2 的函数,对上式求导并令其为 0 得:
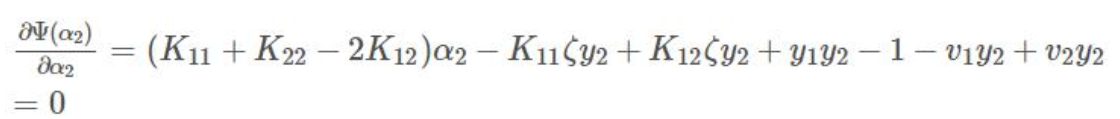

将4, 6, 7 带入求导=0 的式子
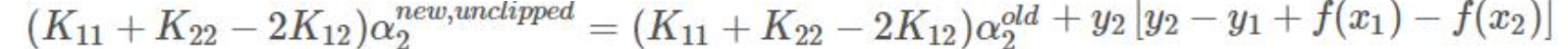
令η=K11+K22−2K12
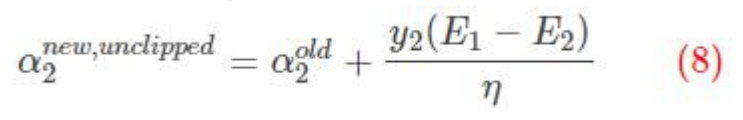
这里得到的α2 是未经过修建的alpha 不一定满足约束条件
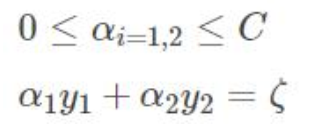


翻译一下:
两个拉格朗日算子 0< α1 α2 < C限定必须在正方形盒子内部
α1y1+α2y2=固定值 限定了必须在直线上 最优解 必须是一条线段
新的α2 下限L 上限H

修建后的alpha
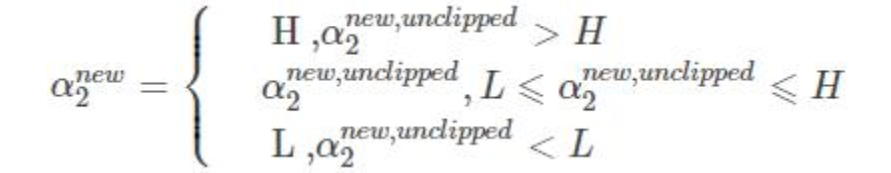
由于其他 N-2 个变量固定:

两边同时乘以y1:
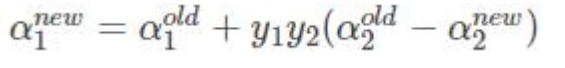
选择α1 α2采用上述方法进行优化,直到不违反kkt条件

α1 α2优化的同时对b进行更新:
- 如果:
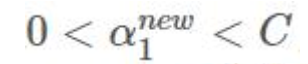
则 x1 y1 为支撑向量
两边乘以y1:
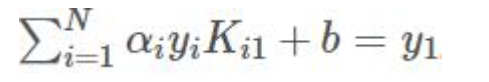
得到bnew:
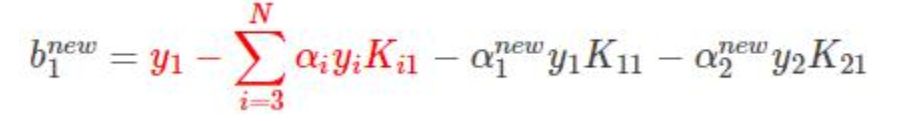
只不过是拆成3部分而已
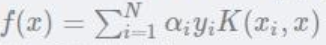

前两项可以替换为
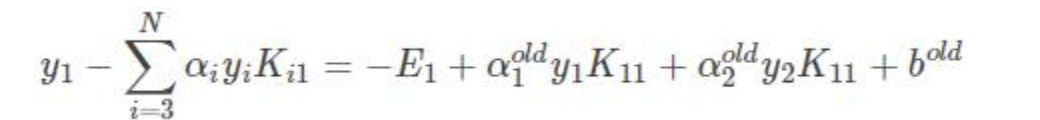
得到:
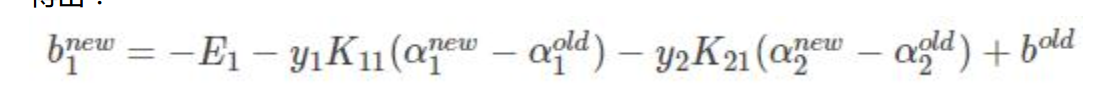
如果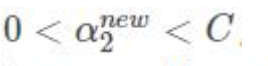
同理:
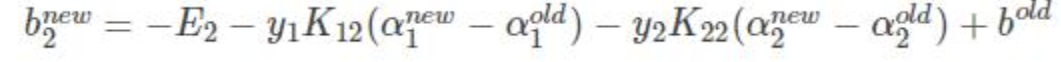
α1 α2 都满足:
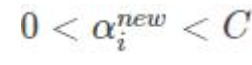
取一个就行: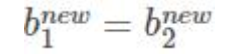
如果都不满足 他们的中点:
取1/2 *(α1 + α2)
机器学习-线性分类-支持向量机SVM-SMO算法-14的更多相关文章
- SVM-非线性支持向量机及SMO算法
SVM-非线性支持向量机及SMO算法 如果您想体验更好的阅读:请戳这里littlefish.top 线性不可分情况 线性可分问题的支持向量机学习方法,对线性不可分训练数据是不适用的,为了满足函数间隔大 ...
- 线性可分支持向量机--SVM(1)
线性可分支持向量机--SVM (1) 给定线性可分的数据集 假设输入空间(特征向量)为,输出空间为. 输入 表示实例的特征向量,对应于输入空间的点: 输出 表示示例的类别. 线性可分支持向量机的定义: ...
- 统计学习:线性可分支持向量机(SVM)
模型 超平面 我们称下面形式的集合为超平面 \[\begin{aligned} \{ \bm{x} | \bm{a}^{T} \bm{x} - b = 0 \} \end{aligned} \tag{ ...
- 机器学习算法整理(七)支持向量机以及SMO算法实现
以下均为自己看视频做的笔记,自用,侵删! 还参考了:http://www.ai-start.com/ml2014/ 在监督学习中,许多学习算法的性能都非常类似,因此,重要的不是你该选择使用学习算法A还 ...
- 机器学习笔记:支持向量机(svm)
支持向量机(svm)英文为Support Vector Machines 第一次接触支持向量机是2017年在一个在线解密游戏"哈密顿行动"中的一个关卡的二分类问题,用到了台湾教授写 ...
- 支持向量机的smo算法(MATLAB code)
建立smo.m % function [alpha,bias] = smo(X, y, C, tol) function model = smo(X, y, C, tol) % SMO: SMO al ...
- 吴裕雄--天生自然python机器学习:基于支持向量机SVM的手写数字识别
from numpy import * def img2vector(filename): returnVect = zeros((1,1024)) fr = open(filename) for i ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
- 机器学习-支持向量机SVM
简介: 支持向量机(SVM)是一种二分类的监督学习模型,他的基本模型是定义在特征空间上的间隔最大的线性模型.他与感知机的区别是,感知机只要找到可以将数据正确划分的超平面即可,而SVM需要找到间隔最大的 ...
- 机器学习——支持向量机SVM
前言 学习本章节前需要先学习: <机器学习--最优化问题:拉格朗日乘子法.KKT条件以及对偶问题> <机器学习--感知机> 1 摘要: 支持向量机(SVM)是一种二类分类模型, ...
随机推荐
- 记录一个异常 Gradle打包项目Lombok不生效 No serializer found for class com.qbb.User and no properties discovered to create BeanSerializer......
完整的错误: 03-Dec-2022 16:57:22.941 涓ラ噸 [http-nio-8080-exec-5] org.apache.catalina.core.StandardWrapperV ...
- 基于LSTM的股票价格预测模型【附源码】
导语 本文介绍了LSTM的相关内容和在股票价格预测上的应用. LSTM的股票价格预测 LSTM(Long Short Term Memory)是一种 特殊的RNN类型,同其他的RNNs相比可以更加方便 ...
- pinia状态管理初识
一款官方推荐的,代替vuex的,新的状态管理工具. 官方网: https://pinia.vuejs.org/zh/introduction.html 主要区别: 去除了modules的概念,每个st ...
- 【笔记整理】request模块基本使用
基本使用 发送get请求.获取响应各种请求.响应信息 def fun1(): url = "http://www.baidu.com" resp = requests.get(ur ...
- Python——第五章:csv模块
未来我们会使用爬虫获取到一些json文件,例如去英雄联盟官方爬取英雄的数据库 查看代码 {"hero":[{"heroId":"1",&qu ...
- Base64编码:数据传输的安全使者
Base64编码是一种将二进制数据转换为可传输的文本表示形式的方法,它在全球范围内被广泛应用于网络通信.数据存储和传输等领域.本文将从多个方面介绍Base64编码的原理.应用及其在现实场景中的优势,帮 ...
- 终于搞懂了Python模块之间的相互引用问题
摘要:详细讲解了相对路径和绝对路径的引用方法. 在某次运行过程中出现了如下两个报错: 报错1: ModuleNotFoundError: No module named '__main__.src_t ...
- SQL优化老出错,那是你没弄明白MySQL解释计划
摘要:数据库的解释计划阐明了sql的执行过程,展示了执行的细节,只要根据数据库告诉我们的问题按图索骥的分析就可以. 本文分享自华为云社区<轻松搞懂mysql的执行计划,再也不怕sql优化了> ...
- Java注解(批注)的基本原理
为什么要使用注解? 早期版本的Spring是通过XML文件的形式对整个框架进行配置的,一个缩减版的配置文件如下 <?xml version="1.0" encoding=&q ...
- linux添加用户,修改用户密码,修改用户权限,设置root用户操作
1.添加普通用户 [root@server ~]# useradd chenjiafa //添加一个名为chenjiafa的用户[root@server ~]# passwd chenjiafa ...