R_回归模型实例一
工作和生活中存在大量的具有相关性的事件,当找到不同变量之间的关系,我们就会用到回归分析。回归分析(Regression Analysis):是用来确定2个或2个以上变量间关系的一种统计分析方法。
在回归分析中,变量有2类:因变量 和 自变量。
- 因变量:通常是指实际问题中所关心的指标,用Y表示。
- 自变量:是影响因变量取值的一个变量,用X表示,如果有多个自变量则表示为X1, X2, …, Xn。
回归分析研究的主要步骤:
- 确定因变量Y 与 自变量X1, X2, …, Xn 之间的定量关系表达式,即回归方程。
- 对回归方程的置信度检查。
- 判断自变量Xn(n=1,2,…,m)对因变量的影响。
- 利用回归方程进行预测。
假设X和Y的关系是线性,可以用公式表式为:Y = a + b * X + c
- Y,为因变量
- X,为自变量
- a,为截距(Intercept)
- b,为自变量系数
- a+b*X, 表示Y随X的变化而线性变化的部分
- c, 为残差或随机误差,是其他一切不确定因素影响的总和,其值不可观测。假定c是符合均值为0方差为σ^2的正态分布 ,记作c~N(0,σ^2)
对于上面的公式,称函数f(X) = a + b * X 为一元线性回归函数,a为回归常数,b为回归系数,统称回归参数。X 为回归自变量或回归因子,Y 为回归因变量或响应变量。
实例
牙膏销售的实例:数据结构及示例化如下
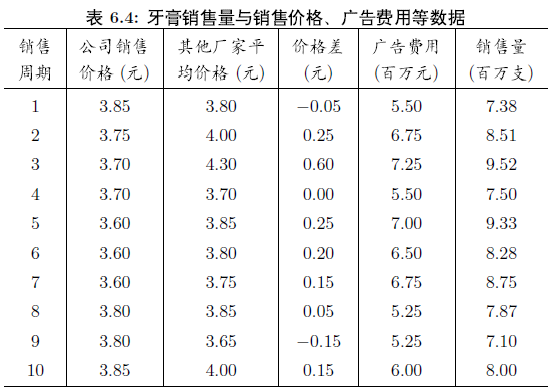
分析: 对于大多数顾客来说,在购买同类牙膏时,更多的会关心不同品牌之间的价格差,而不是它们的价格本身。因此,在研究各个因素对销售量的影响时,用价格差代替公司销售价格和其他厂家平均价格更为合适。
在计算过程中并不一定要知道Y和X是否有线性相关的关系。如果不存相关关系,那么回归方程就没有任何意义了,如果Y和X是有相关关系的,即Y会随着X的变化而线性变化。所以,我们需要用假设检验的方法,来验证相关性的有效性。
通常会采用三种显著性检验的方法:
- T检验法:T检验是检验模型某个自变量Xi对于Y的显著性,通常用P-value判断显著性,小于0.01更小时说明这个自变量Xi与Y相关关系显著。
- F检验法:F检验用于对所有的自变量X在整体上看对于Y的线性显著性,也是用P-value判断显著性,小于0.01更小时说明整体上自变量与Y相关关系显著。
- R^2(R平方)相关系统检验法:用来判断回归方程的拟合程度,R^2的取值在0,1之间,越接近1说明拟合程度越好。
回归模型拟合数据
当两个变量之间存在非常强烈的相互依赖关系的时候,我们就可以说两个变量之间的存在高度相关性。若两组的值一起增大,我们称之为正相关,若一组的值增大时,另一组的值减小,我们称之为负相关。
在使用回归模型拟合数据之前,我们先来观察自变量与因变量之间是如何相关的,我们求出除周期这一列外,其它各列的相关系数矩阵

观察发现sales销售量列的相关系数绝对值越大,相关性越强。注:R中cor函数来计算相关性也是有局限的,它不能计算非线性模型。
基本模型
利用散点图观察销售量与价格差和广告费用的关系
library(ggplot2)
mytable <- read.csv("price.csv")
gplot(mytable,aes(x=mytable$DifPrice,y=mytable$sales))+geom_point()+labs(x="价格差",y="销售量")+geom_smooth(se=F)+theme_bw()
ggplot(mytable,aes(x=mytable$price,y=mytable$sales))+geom_point()+labs(x="价格",y="销售量")+geom_smooth(se=F)+theme_bw()
ggplot(mytable,aes(x=mytable$Invest,y=mytable$sales))+geom_point()+labs(x="广告费",y="销售量")+geom_smooth(se=F)+theme_bw()
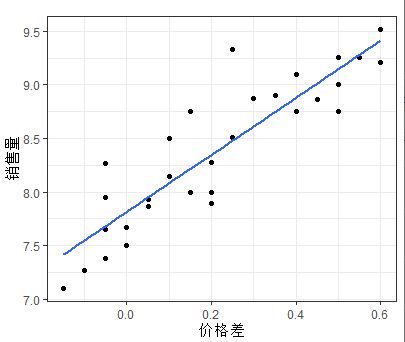
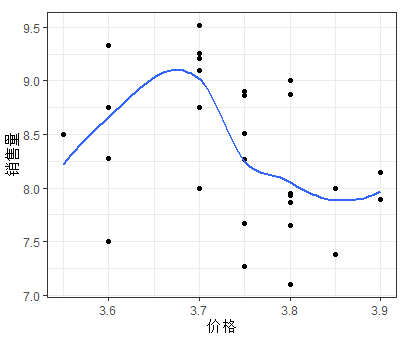
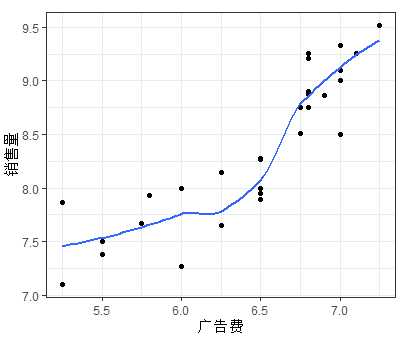
如上图可以发现随着价格差(x1)的增加,销售量(y)有比较明显的线型增长趋势;随着广告费用的增加,销售量有向上弯曲增加的趋势;
模型求解

- Residuals(残差):列出了残差的最小值点,1/4分位点,中位数点,3/4分位点,最大值点。
- Coefficients(系数):表示参数估计的计算结果。Residual standard error:表示残差的标准差,自由度为n-2
- Estimate(估计):参数估计列。Intercept行表示常数参数a的估计值
- Std. Error:为参数的标准差,sd(a), sd(b)
- t value:为t值,为T检验的值
- Pr(>|t|) :表示P-value值,用于T检验判定,匹配显著性标记
- 显著性标记:***为非常显著,**为高度显著, **为显著,·为不太显著,没有记号为不显著。
- Multiple R-squared:为相关系数R^2的检验,越接近1则越显著。
- Adjusted R-squared:为相关系数的修正系数,解决多元回归自变量越多,判定系数R^2越大的问题。
- F-statistic:表示F统计量,自由度为(1,n-2)
- p-value:用于F检验判定,匹配显著性标记。
模型改进
从如上的散点图可以看出,随着广告投入增加,销售量有向上弯曲增加的趋势。这里我们将广告投入的自变量换为二阶项来。则将销售量模型改为:
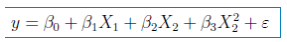
用lm函数拟合以上模型特征:
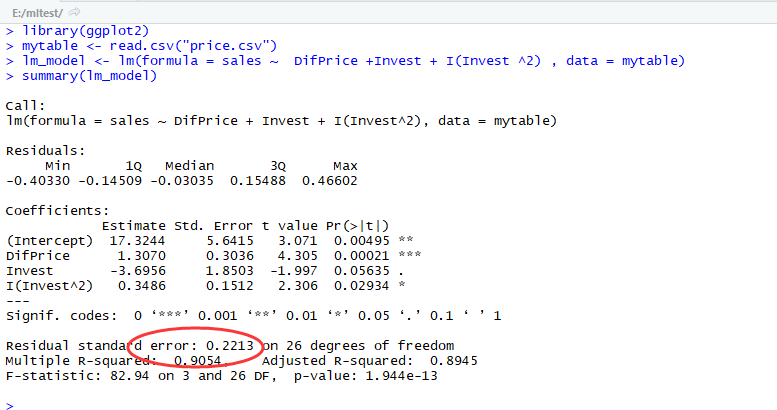
此时,我们发现,模型残差的标准差Residual standard error有所下降,相关系数的平方Multiple R-squared有所上升,这说明模型修正的是合理的。但同时也出现了一个问题,就是对于β2的P-值>0.05。
在做进一步的修正,考虑X1和X2交互作用,及模型为:
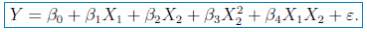
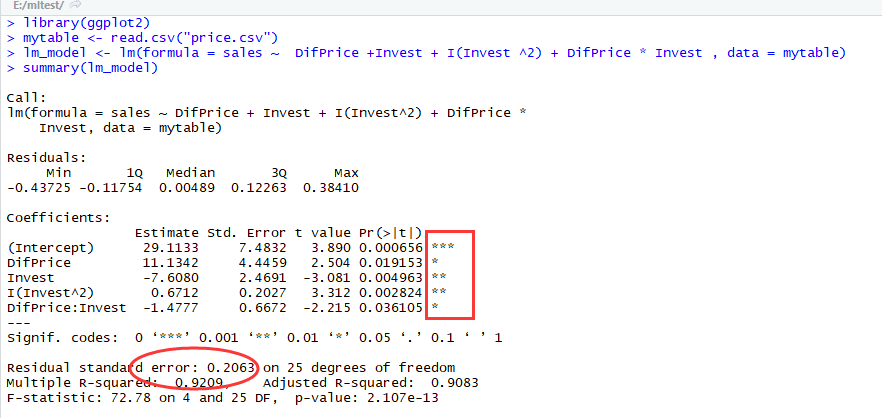
模型通过T检验和F检验,并且Residual standard error减少,Multiple R-squared增加。因此,最终模型选为:
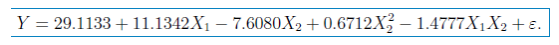
标准化

参考
- https://www.cnblogs.com/nxld/p/6138781.html
- https://blog.csdn.net/yitian_z/article/details/103097349
- https://www.jianshu.com/p/ec3d16ff7b45
- https://zhuanlan.zhihu.com/p/35850444
R_回归模型实例一的更多相关文章
- 如何在R语言中使用Logistic回归模型
在日常学习或工作中经常会使用线性回归模型对某一事物进行预测,例如预测房价.身高.GDP.学生成绩等,发现这些被预测的变量都属于连续型变量.然而有些情况下,被预测变量可能是二元变量,即成功或失败.流失或 ...
- 机器学习笔记(四)Logistic回归模型实现
一.Logistic回归实现 (一)特征值较少的情况 1. 实验数据 吴恩达<机器学习>第二课时作业提供数据1.判断一个学生能否被一个大学录取,给出的数据集为学生两门课的成绩和是否被录取 ...
- R语言广义线性模型(GLM)、全子集回归模型选择、检验分析全国风向气候数据|附代码数据
全文链接:http://tecdat.cn/?p=30914 最近我们被客户要求撰写关于广义线性模型(GLM)的研究报告,包括一些图形和统计输出. 我们正和一位朋友讨论如何在R软件中用GLM模型处理全 ...
- SPSS数据分析—Poisson回归模型
在对数线性模型中,我们假设单元格频数分布为多项式分布,但是还有一类分类变量分布也是经常用到的,就是Poisson分布. Poisson分布是某件事发生次数的概率分布,用于描述单位时间.单位面积.单位空 ...
- SPSS数据分析—配对Logistic回归模型
Lofistic回归模型也可以用于配对资料,但是其分析方法和操作方法均与之前介绍的不同,具体表现 在以下几个方面1.每个配对组共有同一个回归参数,也就是说协变量在不同配对组中的作用相同2.常数项随着配 ...
- SPSS数据分析—多分类Logistic回归模型
前面我们说过二分类Logistic回归模型,但分类变量并不只是二分类一种,还有多分类,本次我们介绍当因变量为多分类时的Logistic回归模型. 多分类Logistic回归模型又分为有序多分类Logi ...
- SPSS数据分析—二分类Logistic回归模型
对于分类变量,我们知道通常使用卡方检验,但卡方检验仅能分析因素的作用,无法继续分析其作用大小和方向,并且当因素水平过多时,单元格被划分的越来越细,频数有可能为0,导致结果不准确,最重要的是卡方检验不能 ...
- Poisson回归模型
Poisson回归模型也是用来分析列联表和分类数据的一种方法,它实际上也是对数线性模型的一种,不同点是对数线性模型假定频数分布为多项式分布,而泊松回归模型假定频数分布为泊松分布. 首先我们来认识一下泊 ...
- Probit回归模型
Probit模型也是一种广义的线性模型,当因变量为分类变量时,有四种常用的分析模型: 1.线性概率模型(LPM)2.Logistic模型3.Probit模型4.对数线性模型 和Logistic回归一样 ...
- logistic回归模型
一.模型简介 线性回归默认因变量为连续变量,而实际分析中,有时候会遇到因变量为分类变量的情况,例如阴性阳性.性别.血型等.此时如果还使用前面介绍的线性回归模型进行拟合的话,会出现问题,以二分类变量为例 ...
随机推荐
- C++常见面试题整理
1. CPP编译链接过程 2. new和malloc区别,delete和free区别 3. 指针和引用 4. 左值引用和右值引用 5. const 6. 函数重载 7. 函数调用栈帧开辟过程 8. i ...
- JNDI注入分析
JNDI介绍 JNDI(Java Naming and Directory Interface,Java命名和目录接口)是为Java应用程序提供命名和目录访问服务的API,允许客户端通过名称发现和查找 ...
- druid开启sql监控平台
1.maven导入依赖 <dependency> <groupId>com.alibaba</groupId> <artifactId>druid< ...
- 性能测试思想(What is performance testing?)
1.什么是性能测试 什么是软件性能? 定义:软件的性能是软件的一种非功能特性,它关注的不是软件是否能够完成特定的功能,而是在完成该功能是展示出来的及时性. 比如:一个登录功能他能实现登录操作,但是登录 ...
- Scala 不可变数组Array
1 package chapter07 2 3 object Test01_ImmutableArray { 4 def main(args: Array[String]): Unit = { 5 / ...
- 网页实现串口TCP数据通讯的两种方案
概述 串口和TCP数据通讯客户端的形式比较多,但是网页中用的比较少. 其实最大的是网页无法访问本地资源造成的,可能是出于安全方面考虑吧. 解决方案也不是没有,这里介绍几种供大家参考. 方案一:专用 ...
- OpenHarmony设备截屏的5种方式
本文转载自<OpenHarmony设备截屏的5种方式 >,作者westinyang 目录 ● 方式1:系统控制中心 ● 方式2:OHScrcpy投屏工具 `推荐` ● 方式3:DevE ...
- Linux之识别HBA的WWN
一.概念 FC HBA,也即Fibre Channel Host Bus Adapter,光纤通道主机适配器,简称光纤适配器. 在FC网络环境中,主机需要和FC网络.FC存储设备(SAN磁盘阵列)连接 ...
- Gin
0x01 准备 (1)概述 定义:一个 golang 的微框架 特点:封装优雅,API 友好,源码注释明确,快速灵活,容错方便 优势: 对于 golang 而言,web 框架的依赖要远比 Python ...
- 抓包整理————tcp 协议[八]
前言 简单介绍一下tcp 协议. 正文 tcp历史: advanced research projects agency network: 1973年: tcp/ip 协议 tcpv4 协议分层后的网 ...